(数据科学学习手札27)sklearn数据集分割方法汇总
一、简介
在现实的机器学习任务中,我们往往是利用搜集到的尽可能多的样本集来输入算法进行训练,以尽可能高的精度为目标,但这里便出现一个问题,一是很多情况下我们不能说搜集到的样本集就能代表真实的全体,其分布也不一定就与真实的全体相同,但是有一点很明确,样本集数量越大则其接近真实全体的可能性也就越大;二是很多算法容易发生过拟合(overfitting),即其过度学习到训练集中一些比较特别的情况,使得其误认为训练集之外的其他集合也适用于这些规则,这使得我们训练好的算法在输入训练数据进行验证时结果非常好,但在训练集之外的新测试样本上精度则剧烈下降,这样训练出的模型可以说没有使用价值;因此怎样对数据集进行合理的抽样-训练-验证就至关重要,下面就对机器学习中常见的抽样技术进行介绍,并通过sklearn进行演示;
二、留出法
留出法(hold-out)在前面的很多篇博客中我都有用到,但当时没有仔细介绍,其基本思想是将数据集D(即我们获得的所有样本数据)划分为两个互斥的集合,将其中一个作为训练集S,另一个作为验证集T,即D=SUT,S∩T=Φ。在S上训练出模型后,再用T来评估其测试误差,作为泛化误差的估计值;
需要注意的是,训练集/验证集的划分要尽可能保持数据分布的一致性,尽量减少因数据划分过程引入额外的偏差而对最终结果产生的影响,例如在分类任务中,要尽量保持S与T内的样本各个类别的比例大抵一致,这可以通过分层抽样(stratified sampling)来实现;
因为我们希望实现的是通过这个留出法的过程来评估数据集D的性能,但由于留出法需要划分训练集与验证集,这就不可避免的减少了训练素材,若验证集样本数量过于小,导致训练集与原数据集D接近,而与验证集差别过大,进而导致无论训练出的模型效果如何,都无法在验证集上取得真实的评估结果,从而降低了评估效果的保真性(fidelity),因此训练集与验证集间的比例就不能过于随便,通常情况下我们将2/3到4/5的样本划分出来用于训练;
在sklearn中我们使用sklearn.model_selection中的train_test_split()来分割我们的数据集,其具体参数如下:
X:待分割的样本集中的自变量部分,通常为二维数组或矩阵的形式;
y:待分割的样本集中的因变量部分,通常为一维数组;
test_size:用于指定验证集所占的比例,有以下几种输入类型:
1.float型,0.0~1.0之间,此时传入的参数即作为验证集的比例;
2.int型,此时传入的参数的绝对值即作为验证集样本的数量;
3.None,这时需要另一个参数train_size有输入才生效,此时验证集去为train_size指定的比例或数量的补集;
4.缺省时为0.25,但要注意只有在train_size和test_size都不输入值时缺省值才会生效;
train_size:基本同test_size,但缺省值为None,其实test_size和train_size输入一个即可;
random_state:int型,控制随机数种子,默认为None,即纯随机(伪随机);
stratify:控制分类问题中的分层抽样,默认为None,即不进行分层抽样,当传入为数组时,则依据该数组进行分层抽样(一般传入因变量所在列);
shuffle:bool型,用来控制是否在分割数据前打乱原数据集的顺序,默认为True,分层抽样时即stratify为None时该参数必须传入False;
返回值:
依次返回训练集自变量、测试集自变量、训练集因变量、测试集因变量,因此使用该函数赋值需在等号右边采取X_train, X_test, y_train, y_test'的形式;
下面以鸢尾花数据(三个class)为例,分别演示简单随机抽样和分层抽样时的不同情况:
未分层时:
from sklearn.model_selection import train_test_split
from sklearn import datasets
import pandas as pd '''载入数据'''
X,y = datasets.load_iris(return_X_y=True) '''不采取分层抽样时的数据集分割'''
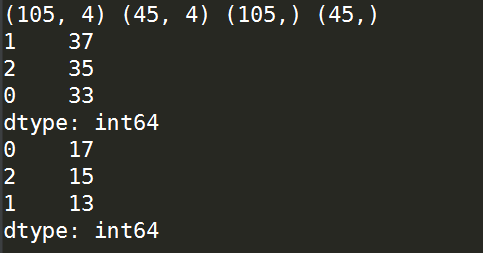
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3) '''打印各个数据集的形状'''
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape) '''打印训练集中因变量的各类别数目情况'''
print(pd.value_counts(y_train)) '''打印验证集集中因变量的各类别数目情况'''
print(pd.value_counts(y_test))
分层时:
'''采取分层抽样时的数据集分割'''
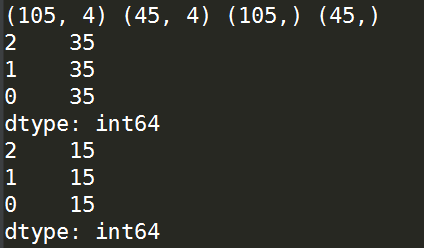
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,stratify=y) '''打印各个数据集的形状'''
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape) '''打印训练集中因变量的各类别数目情况'''
print(pd.value_counts(y_train)) '''打印验证集集中因变量的各类别数目情况'''
print(pd.value_counts(y_test))
三、交叉验证法
交叉验证法(cross validation)先将数据集D划分为k个大小相似的互斥子集,即D=D1UD2U...UDk,Di∩Dj=Φ(i≠j),每个子集Di都尽可能保持数据分布的一致性,即从D中通过分层采样得到。然后每次用k-1个子集的并集作为训练集,剩下的那一个子集作为验证集;这样就可获得k组训练+验证集,从而可以进行k次训练与测试,最终返回的是这k个测试结果的均值。显然,交叉验证法的稳定性和保真性在很大程度上取决与k的取值,因此交叉验证法又称作“k折交叉验证”(k-fold cross validation),k最常见的取值为10,即“10折交叉验证”,其他常见的有5,20等;
假定数据集D中包含m个样本,若令k=m,则得到了交叉验证法的一个特例:留一法(Leave-one-out),显然,留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分m个子集——每个子集包含一个样本,留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一法中被实际评估的模型与期望评估的用D训练出的模型很相似,因此,留一法的评估结果往往被认为比较准确,但其也有一个很大的缺陷:当数据集比较大时,训练m个模型的计算成本是难以想象的;
在sklearn.model_selection中集成了众多用于交叉验证的方法,下面对其中常用的进行介绍:
cross_val_score():
这是一个用于直接计算某个已确定参数的模型其交叉验证分数的方法,具体参数如下:
estimator:已经初始化的学习器模型;
X:自变量所在的数组;
y:因变量所在的数组;
scoring:str型,控制函数返回的模型评价指标,默认为准确率;
cv:控制交叉验证中分割样本集的策略,即k折交叉中的k,默认是3,即3折交叉验证,有以下多种输入形式:
1.int型,则输入的参数即为k;
2.None,则使用默认的3折;
3.一个生成器类型的对象,用来控制交叉验证,优点是节省内存,下面的演示中会具体介绍;
*若estimator是一个分类器,则默认使用分层抽样来产生子集。
n_jobs:int型,用来控制并行运算中使用的核心数,默认为1,即单核;特别的,设置为-1时开启所有核心;
函数返回值:
对应scoring指定的cv个评价指标;
下面以一个简单的小例子进行演示:
from sklearn.model_selection import cross_val_score
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier X,y = datasets.load_breast_cancer(return_X_y=True) clf = KNeighborsClassifier() '''打印每次交叉验证的准确率'''
score = cross_val_score(clf,X,y,cv=5,scoring='accuracy') print('accuracy:'+str(score)+'\n') '''打印每次交叉验证的f1得分'''
score = cross_val_score(clf,X,y,cv=5,scoring='f1') print('f1 score:'+str(score)+'\n') '''打印正确率的95%置信区间'''
print(str(round(score.mean(),3))+'(+/-'+str(round(2*score.std(),3))+')')

cross_validate():
这个方法与cross_val_score()很相似,但有几处新特性:
1.cross_validate()可以返回多个评价指标,这在需要一次性产生多个不同种类评分时很方便;
2.cross_validate()不仅返回模型评价指标,还会返回训练花费时长、
其具体参数如下:
estimator:已经初始化的分类器模型;
X:自变量;
y:因变量;
scoring:字符型或列表形式的多个字符型,控制产出的评价指标,可以通过在列表中写入多个评分类型来实现多指标输出;
cv:控制交叉验证的子集个数;
n_jobs:控制并行运算利用的核心数,同cross_val_score();
return_train_score:bool型,控制是否在得分中计算训练集回带进模型的结果;
函数输出项:字典形式的训练时间、计算得分时间、及各得分情况;
下面以一个简单的小例子进行说明:
from sklearn.model_selection import cross_validate
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier X,y = datasets.load_breast_cancer(return_X_y=True) clf = KNeighborsClassifier() '''定义需要输出的评价指标'''
scoring = ['accuracy','f1'] '''打印每次交叉验证的准确率'''
score = cross_validate(clf,X,y,scoring=scoring,cv=5,return_train_score=True) score

四、基于生成器的采样方法
sklearn中除了上述的直接完成整套交叉验证的方法外,还存在着一些基于生成器的方法,这些方法的好处是利用Python中生成器(generator)的方式,以非常节省内存的方式完成每一次的交叉验证,下面一一罗列:
KFold():
以生成器的方式产出每一次交叉验证所需的训练集与验证集,其主要参数如下:
n_splits:int型,控制k折交叉中的k,默认是3;
shuffle:bool型,控制是否在采样前打乱原数据顺序;
random_state:设置随机数种子,默认为None,即不固定随机水平;
下面以一个简单的小例子进行演示:
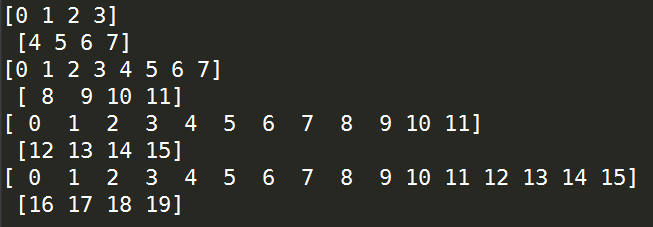
from sklearn.model_selection import KFold
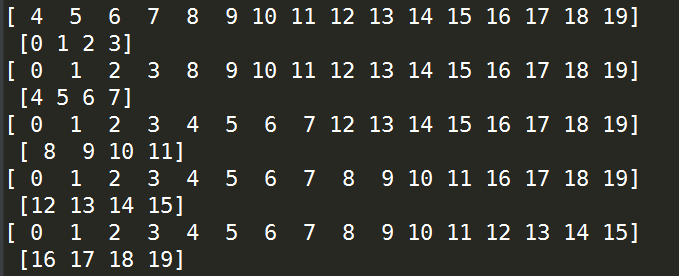
import numpy as np X = np.random.randint(1,10,20) kf = KFold(n_splits=5) for train,test in kf.split(X):
print(train,'\n',test)
LeaveOneOut():
对应先前所介绍的留出法中的特例,留一法,因为其性质很固定,所以无参数需要调节,下面以一个简单的小例子进行演示:
from sklearn.model_selection import LeaveOneOut
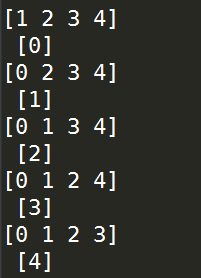
import numpy as np X = np.random.randint(1,10,5) kf = LeaveOneOut() for train,test in kf.split(X):
print(train,'\n',test)
LeavePOut():
LeaveOneOut()的一个变种,唯一的不同就是每次留出p个而不是1个样本作为验证集,唯一的参数是p,下面是一个简单的小例子:
from sklearn.model_selection import LeavePOut
import numpy as np X = np.random.randint(1,10,5) kf = LeavePOut(p=2) for train,test in kf.split(X):
print(train,'\n',test)
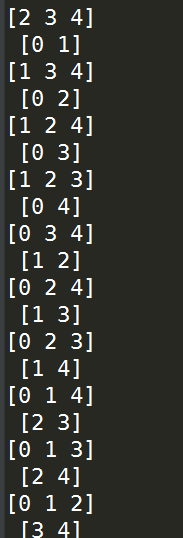
TimeSeriesSplit():
在机器学习中还存在着一种叫做时间序列的数据类型,这种数据的特点是高度的自相关性,前后相邻时段的数据关联程度非常高,因此在对这种数据进行分割时不可以像其他机器学习任务那样简单随机抽样的方式采样,对时间序列数据的采样不能破坏其时段的连续型,在sklearn.model_selection中我们使用TimeSeriesSplit()来分割时序数据,其主要参数如下:
n_splits:int型,控制产生(训练集+验证集)的数量;
max_train_size:控制最大的时序数据长度;
下面是一个简单的小例子:
from sklearn.model_selection import TimeSeriesSplit
import numpy as np X = np.random.randint(1,10,20) kf = TimeSeriesSplit(n_splits=4) for train,test in kf.split(X):
print(train,'\n',test)
以上就是sklearn中关于样本抽样的常见功能,如有笔误,望指出。
我的博客即将搬运同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1dq5sf6aad1ud
(数据科学学习手札27)sklearn数据集分割方法汇总的更多相关文章
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
随机推荐
- 1.6 WEB API NET CORE 使用Redis
一.Redis安装 https://www.cnblogs.com/cvol/p/9174078.html 二.新建.net core web api程序 选webapi 或者应用程序都可以 三.使用 ...
- 3元购买微信小程序解决方案一个月
一.登录微信公众平台https://mp.weixin.qq.com/ 二.点击立即注册.注意:这里不要用微信公众号登录,小程序账号和微信公众号是不同的. 三.在注册页面点击小程序板块. 四.进入小程 ...
- pip pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool
设置超时时间: pip --default-timeout=100 install Pillow
- CSS 替换元素和非替换元素 行内非替换元素
html元素也可以分为替换元素和非替换元素 1.替换元素 替换元素是由浏览器根据表示的元素和属性决定显示的内容. 例如:<img src="./image.jpg" /> ...
- python解析HTML之:PyQuery库的介绍与使用
本篇大部分转载于https://www.jianshu.com/p/c07f7cd1b548 先放自已自己解析techweb一个网站图片的代码 from pyquery import PyQuery ...
- python:序列与模块
一,序列化模块 什么叫序列化——将原本的字典.列表等内容转换成一个字符串的过程就叫做序列化. 比如,我们在python代码中计算的一个数据需要给另外一段程序使用,那我们怎么给? 现在我们能想到的方法就 ...
- 【洛谷2290】[HNOI2004] 树的计数(Python+利用prufer序列结论求解)
点此看题面 大致题意: 给定每个点的度数,让你求有多少种符合条件的无根树. \(prufer\)序列 这显然是一道利用\(prufer\)序列求解的裸题. 考虑到由\(prufer\)序列得到的结论: ...
- 【转】JS模块化工具requirejs教程(二):基本知识
前一篇:JS模块化工具requirejs教程(一):初识requirejs 我们以非常简单的方式引入了requirejs,这一篇将讲述一下requirejs中的一些基本知识,包括API使用方式等. 基 ...
- SignalR中的依赖注入
什么是依赖注入? 如果你已经熟悉依赖注入可以跳过此节. 依赖注入 (DI) 模式下,对象并不为自身的依赖负责. 下边的例子是一个主动 DI. 假设你有个对象需要消息日志.你可能定义了一个日志接口: C ...
- Several ports (8005, 8080, 8009) required by Tomcat v8.5 Server at localhost are already in use. The server may already be running in another process, or a system process may be using the port. To sta
eclipse出现:Several ports (8005, 8080, 8009) required by Tomcat v8.5 Server at localhost are already i ...