Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理
1,为什么选择 HDFS 存储数据
之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点:
1、高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性。
- 某一个副本丢失以后,它可以自动恢复,这是由 HDFS 内部机制实现的,我们不必关心。
2、适合批处理
- 它是通过移动计算而不是移动数据。
- 它会把数据位置暴露给计算框架。
3、适合大数据处理
- 处理数据达到 GB、TB、甚至PB级别的数据。
- 能够处理百万规模以上的文件数量,数量相当之大。
- 能够处理10K节点的规模。
4、流式文件访问
- 一次写入,多次读取。文件一旦写入不能修改,只能追加。
- 它能保证数据的一致性。
5、可构建在廉价机器上
- 它通过多副本机制,提高可靠性。
- 它提供了容错和恢复机制。比如某一个副本丢失,可以通过其它副本来恢复。
当然 HDFS 也有它的劣势,并不适合所有的场合:
1、低延时数据访问
- 比如毫秒级的来存储数据,这是不行的,它做不到。
- 它适合高吞吐率的场景,就是在某一时间内写入大量的数据。但是它在低延时的情况下是不行的,比如毫秒级以内读取数据,这样它是很难做到的。
2、小文件存储
- 存储大量小文件(这里的小文件是指小于HDFS系统的Block大小的文件(默认64M))的话,它会占用 NameNode大量的内存来存储文件、目录和块信息。这样是不可取的,因为NameNode的内存总是有限的。
- 小文件存储的寻道时间会超过读取时间,它违反了HDFS的设计目标。
3、并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写。
- 仅支持数据 append(追加),不支持文件的随机修改。
2,HDFS 如何存储数据
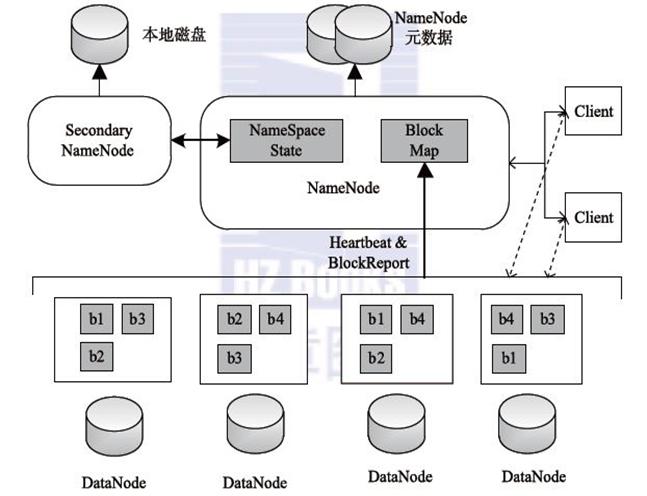
HDFS的架构图
HDFS 采用Master/Slave的架构来存储数据,这种架构主要由四个部分组成,分别为HDFS Client、NameNode、DataNode和Secondary NameNode。下面我们分别介绍这四个组成部分
1、Client:就是客户端。
- 文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。
- 与 NameNode 交互,获取文件的位置信息。
- 与 DataNode 交互,读取或者写入数据。
- Client 提供一些命令来管理 HDFS,比如启动或者关闭HDFS。
- Client 可以通过一些命令来访问 HDFS。
2、NameNode:就是 master,它是一个主管、管理者。
- NameNode 是 HDFS 的核心。
- NameNode 也称为 Master。
- NameNode 仅存储 HDFS 的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件。
- NameNode 不存储实际数据或数据集。数据本身实际存储在 DataNodes 中。
- NameNode 知道 HDFS 中任何给定文件的块列表及其位置。使用此信息NameNode 知道如何从块中构建文件。
- NameNode 并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从数据节点重建。
- NameNode 对于 HDFS 至关重要,当 NameNode 关闭时,HDFS / Hadoop 集群无法访问。
- NameNode 是 Hadoop 集群中的单点故障。
- NameNode 所在机器通常会配置有大量内存(RAM)。
3、DataNode:就是Slave。NameNode 下达命令,DataNode 执行实际的操作。
- DataNode 负责将实际数据存储在 HDFS 中。
- DataNode 也称为 Slave。
- NameNode 和 DataNode 会保持不断通信。
- DataNode 启动时,它将自己发布到 NameNode 并汇报自己负责持有的块列表。
- 当某个 DataNode 关闭时,它不会影响数据或群集的可用性。NameNode 将安排由其他 DataNode 管理的块进行副本复制。
- DataNode 所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode 中。
- DataNode 会定期(dfs.heartbeat.interval 配置项配置,默认是 3 秒)向NameNode 发送心跳,如果 NameNode 长时间没有接受到 DataNode 发送的心跳, NameNode 就会认为该 DataNode 失效。
- block 汇报时间间隔取参数 dfs.blockreport.intervalMsec,参数未配置的话默认为 6 小时。
4、Secondary NameNode:并非 NameNode 的热备。当NameNode 挂掉的时候,它并不能马上替换 NameNode 并提供服务。
- 辅助 NameNode,分担其工作量。
- 定期合并 fsimage和fsedits,并推送给NameNode。
- 在紧急情况下,可辅助恢复 NameNode。
3 HDFS 的工作机制
首先:HDFS是一个文件系统,用于存储和管理文件,通过统一的命名空间(类似于本地文件系统的目录树)。是分布式的,服务器集群中各个节点都有自己的角色和职责。
其次:
1.HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,之前的版本中是64M。
2.HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
3.目录结构及文件分块位置信息(元数据)的管理由namenode节点承担,namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的数据块信息(blockid及所在的datanode服务器)
4.文件的各个block的存储管理由datanode节点承担,datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication,默认是3)
5.Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量,HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行。
6.HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改。需要频繁的RPC交互,写入性能不好。
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNode 进行元数据的备份。
HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向NameNode 申请来进行。
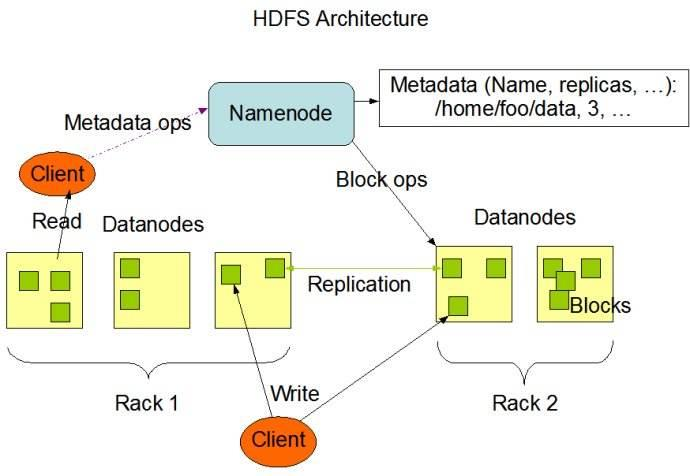
3.1 HDFS 写数据流程
详细步骤解析:
1、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
2、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
3、 NameNode 根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的 DataNode 的地址,如:A,B,C;注:默认存储策略由 BlockPlacementPolicyDefault 类支持。也就是日常生活中提到最经典的 3副本策略 。
1st replica 如果写请求方所在机器是其中一个 datanode,则直接存放在本地,否则随机在集群中选择一个 datanode.
2nd replica 第二个副本存放于不同第一个副本的所在的机架.
3rd replica 第三个副本存放于第二个副本所在的机架,但是属于不同的节点
如图:

4、 client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC 调用,建立 pipeline),A 收到请求会继续调用 B,然后 B 调用 C,将整个pipeline 建立完成,后逐级返回 client;
5、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
6、 数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
7、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个block 到服务器。
--------
3.2 HDFS 读数据流程
详细步骤解析:
1、 Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
2、 NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
3、 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
4、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
5、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
6、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
7、 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
8、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
9、 最终读取来所有的 block 会合并成一个完整的最终文件。
Hadoop之HDFS(二)HDFS基本原理的更多相关文章
- Hadoop集群(二) HDFS搭建
HDFS只是Hadoop最基本的一个服务,很多其他服务,都是基于HDFS展开的.所以部署一个HDFS集群,是很核心的一个动作,也是大数据平台的开始. 安装Hadoop集群,首先需要有Zookeeper ...
- HDFS二.HDFS实现分布式文件存储---体系结构
单击模式(Standalone): 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选择了最小配置.在这种默认模式下所有3个XML文件均为 ...
- Hadoop 系列文章(二) Hadoop配置部署启动HDFS及本地模式运行MapReduce
接着上一篇文章,继续我们 hadoop 的入门案例. 1. 修改 core-site.xml 文件 [bamboo@hadoop-senior hadoop-2.5.0]$ vim etc/hadoo ...
- HADOOP docker(二):HDFS 高可用原理
1.环境简述2.QJM HA简述2.1为什么要做HDFS HA?2.2 HDFS HA的方式2.2 HSFS HA的结构2.3 机器要求3.部署HDFS HA3.1 详细配置3.2 部署HDF ...
- Hadoop源码之HDFS(1)--------通信方式
说起hadoop这个东西,只能说真是个伟大的发明,而本人对cutting大神也是无比的崇拜,记得刚接触hadoop的时候,还觉得这个东西挺多余的,但是现在想想,这个想法略傻逼...... 2006-2 ...
- Hadoop学习笔记: HDFS
注:该文内容部分来源于ChinaHadoop.cn上的hadoop视频教程. 一. HDFS概述 HDFS即Hadoop Distributed File System, 源于Google发表于200 ...
- Hadoop(五)搭建Hadoop与Java访问HDFS集群
前言 上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令: hdfs dfs -ls xxx hdfs dfs -mkdir -p /xxx/xxx hdfs dfs -cat ...
- Hadoop(四)HDFS的高级API操作
一 HDFS客户端环境准备 1.1 jar包准备 1)解压hadoop-2.7.6.tar.gz到非中文目录 2)进入share文件夹,查找所有jar包,并把jar包拷贝到_lib文件夹下 3)在全部 ...
- Hadoop(三)HDFS读写原理与shell命令
一 HDFS概述 1.1 HDFS产生背景 随着数据量越来越大,在一个操作系统管辖的范围内存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件 ...
- hadoop的API对HDFS上的文件访问
这篇文章主要介绍了使用hadoop的API对HDFS上的文件访问,其中包括上传文件到HDFS上.从HDFS上下载文件和删除HDFS上的文件,需要的朋友可以参考下hdfs文件操作操作示例,包括上传文件到 ...
随机推荐
- WEKA运行参数修改(RunWeka.ini文件)
一般使用weka进行数据挖掘的时候会碰到两个问题,一是内存不够,二是libsvm使用不了,这时就需要重新配置RunWeka.ini文件,解决上述问题.查看RunWeka.ini原文如下: # Cont ...
- 对结合BDD进行DDD开发的一点思考和整理
引言 二十年前的我,还在学校里抱着一台DIY机(德州486+大众主板+16M内存+3.5inch软驱+昆腾320M硬盘,当时全校最快主机没有之一),揣着一本<Undocumented DOS&g ...
- Ubuntu+Rmarkdown的中文slides实现(附GitHub template)
这两天要做毕业论文的答辩slides,搜Rmarkdown中文slides的时候百度到了自己两年前的博客 R+markdown+LaTeX 中文编译解决方案.讲真我一开始还真没有认出来,一看这文风和博 ...
- 【解题报告】2014ACM/ICPC上海赛区现场赛B
唉 谷歌出的神题,差点爆零了...三小时终于A掉 B题 题目大概是说从左上角的点出发,经过某路线最后回到原点,求每个格子被路线包含的圈数的平方和. 首先可以知道,对于某个格子来说,从该格子的任意一个 ...
- iOS设置translucent 引发的坐标问题
iOS NavigationBar + 导航栏 tablevie时候的布局情况,之前迷惑了我很久,怎么也没法理解透明度会影响布局. 接下来看一下以下三种情况的运行结果 1.全部系统默认情况下利用m ...
- C# 浅拷贝与深拷贝(复制)
在有些时候,我们需要从数据库读取数据填充对象或从硬盘读取文件填充对象,但是这样做相对耗时.这时候我们就想到了对象的拷贝.本文即以实例形式解析了C#浅拷贝和深拷贝的用法. C#中有两种类型变量,一种 是 ...
- BZOJ5340: [Ctsc2018]假面
BZOJ5340: [Ctsc2018]假面 https://lydsy.com/JudgeOnline/problem.php?id=5340 分析: 背包,只需要求\(g_{i,j}\)表示强制活 ...
- 在Git远程管理项目
新建repository 本地目录下,在命令行里新建一个代码仓库(repository) 里面只有一个README.md 命令如下: touch README.md git init 初 ...
- ARP表 MAC表 路由表
ARP表是一个动态表,存储在计算机当中,目的是做一个ip地址与mac地址的对应.假设在同一子网段,计算机A与计算机B通信计算机A的ip地址192.168.0.1 MAC地址AA-AA-AA-AA-AA ...
- UVA12296 Pieces and Discs
题意 PDF 分析 可以看成直线切割多边形,直接维护. 对每个多边形考虑每条边和每个点即可. 时间复杂度?不过\(n,m \leq 20\)这种数据怎么都过了.据说是\(O(n^3)\)的,而且常数也 ...