智联招聘的python岗位数据结巴分词(一)
如何获取数据点击这里
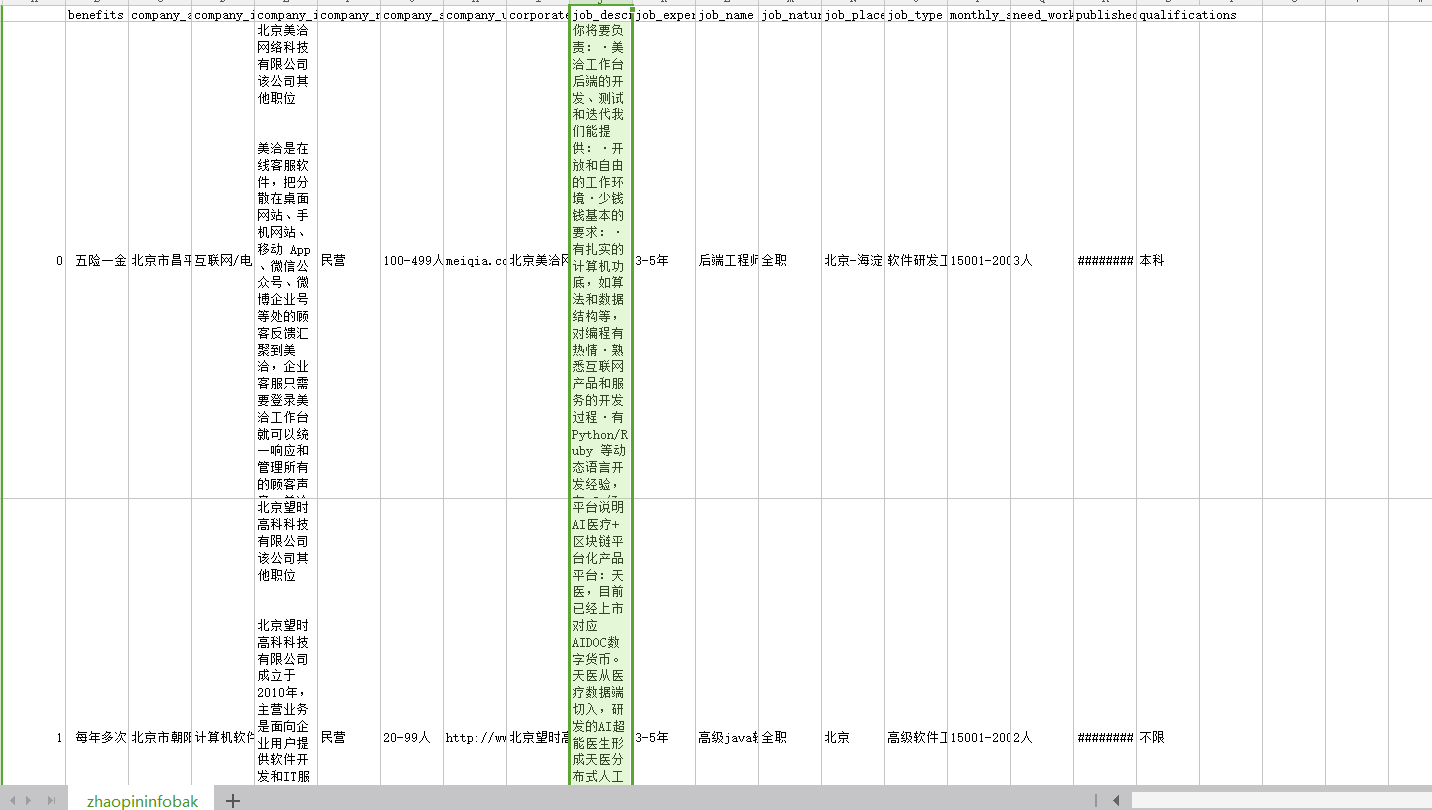
下载之后的文件名为:all_results.csv
数据样式大概这样。然后下面我分析的是工作要求 也就是那边的绿框那一列。
import csv
import os
import jieba
import jieba.posseg as psg #posseg模块可以获取词性
datapath=os.path.join(os.getcwd(),"all_results.csv")
with open(datapath,'r',newline='',encoding='utf-8') as csvfile:
# rows=csv.reader(csvfile)
# headers = next(rows)
# for i ,row in enumerate(rows):
# if i%50==0:
# print("正在处理第{}行数据".format(i))
# job_required=row[8]
# job_requirednew=job_required.strip().replace(" ","")
# result_list.append(job_requirednew)
rows=csv.DictReader(csvfile)
result_list=[row['job_description'].strip().replace('\xa0','').replace('\r\n','') for row in rows]
info_attr = [(x.word,x.flag) for x in psg.cut(''.join(result_list)) if len(x.word) >= 2] # 这里的x.word为词本身,x.flag为词性
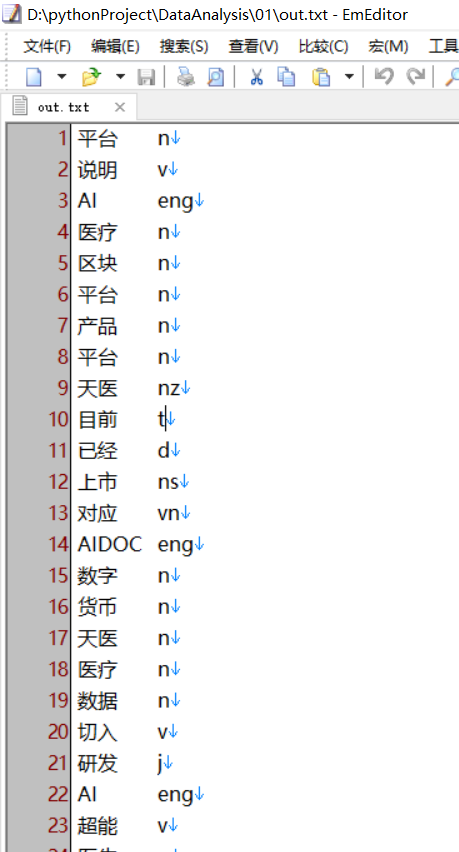
with open('out.txt','w+') as f:
for x in info_attr:
f.write('{0}\t{1}\n'.format(x[0],x[1]))
运行完上面的程序得到的文件结构如下
智联招聘的python岗位数据结巴分词(一)的更多相关文章
- 智联招聘的python岗位数据结巴分词(二)
上次获取第一次分词之后的内容了 但是数据数据量太大了 ,这时候有个模块就派上用场了collections模块的Counter类 Counter类:为hashable对象计数,是字典的子类. 然后使用m ...
- 智联招聘的python岗位数据词云制作
# 根据传入的背景图片路径和词频字典.字体文件,生成指定名称的词云图片 def generate_word_cloud(img_bg_path, top_words_with_freq, font_p ...
- 智联招聘获取python岗位的数据
import requests from lxml import html import time import pandas as pd from sqlalchemy import create_ ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- Python+selenium爬取智联招聘的职位信息
整个爬虫是基于selenium和Python来运行的,运行需要的包 mysql,matplotlib,selenium 需要安装selenium火狐浏览器驱动,百度的搜寻. 整个爬虫是模块化组织的,不 ...
- 用生产者消费模型爬取智联招聘python岗位信息
爬取python岗位智联招聘 这里爬取北京地区岗位招聘python岗位,并存入EXECEL文件内,代码如下: import json import xlwt import requests from ...
- 用Python爬取智联招聘信息做职业规划
上学期在实验室发表时写了一个爬取智联招牌信息的爬虫. 操作流程大致分为:信息爬取——数据结构化——存入数据库——所需技能等分词统计——数据可视化 1.数据爬取 job = "通信工程师&qu ...
- python爬取智联招聘职位信息(多进程)
测试了下,采用单进程爬取5000条数据大概需要22分钟,速度太慢了点.我们把脚本改进下,采用多进程. 首先获取所有要爬取的URL,在这里不建议使用集合,字典或列表的数据类型来保存这些URL,因为数据量 ...
- python爬取智联招聘职位信息(单进程)
我们先通过百度搜索智联招聘,进入智联招聘官网,一看,傻眼了,需要登录才能查看招聘信息 没办法,用账号登录进去,登录后的网页如下: 输入职位名称点击搜索,显示如下网页: 把这个URL:https://s ...
随机推荐
- 跳出for循环break和continue的区别
1.break 跳出for循环,结束for循环 如果有两层循环,break只能跳出一层循环 2.continue 跳出本次循环,继续下一条数据的循环
- Spring实战第六章学习笔记————渲染Web视图
Spring实战第六章学习笔记----渲染Web视图 理解视图解析 在之前所编写的控制器方法都没有直接产生浏览器所需的HTML.这些方法只是将一些数据传入到模型中然后再将模型传递给一个用来渲染的视图. ...
- 九度OJ--1167(C++)
#include <iostream>#include <algorithm>#include <map> using namespace std; int mai ...
- Kindle 3(非常旧的版本) 隔一段时间自动重启问题
买了本新书后,kindle 3 自己没事就在那边重启,几分钟一次 查到解决方案1: https://answers.yahoo.com/question/index?qid=2014040815565 ...
- 前端开发神器Sublime Text2/3之安装使用(windows7/Mac)
一,到官方网站下载神器 地址:http://www.sublimetext.com/3 Sublime Text 3 配置解释(默认){// 设置主题文件“color_scheme”: “Packag ...
- Android Studio环境解读
一.使用IDE开发APP的流程 要熟悉一个新的IDE,可依次完成以下流程: 二.相关术语解析 Dalvik: Android特有的虚拟机,和JVM不同,Dalvik虚拟机非常适合在移动终端上使用! A ...
- 《学习OpenCV》课后习题解答9
题目:(P126) 创建一个程序,使其读入并显示一幅图像.当用户鼠标点击图像时,获取图像对应像素的颜色值(BGR),并在图像上点击鼠标处用文本将颜色值显示出来. 解答: 本题关键是会用cvGet2D获 ...
- mysql 数据包太小会引发错误信息
Error querying database. Cause: com.mysql.cj.jdbc.exceptions.PacketTooBigException: Packet for quer ...
- 集群hadoop ubuntu版
搭建ubuntu版hadoop集群 用到的工具:VMware.hadoop-2.7.2.tar.jdk-8u65-linux-x64.tar.ubuntu-16.04-desktop-amd64.is ...
- 【算法】分块——教主的魔法&不勤劳的图书管理员
由不勤劳的图书管理员带入了分块的坑,深深地被其暴力与优雅所征服.分块的实质就是将暴力块状封装起来,一整块的部分就一整块处理,零碎的部分就怎么暴力怎么来.因为分块大小的原因,限制了零碎部分数据的数量级, ...