数据量越发庞大怎么办?新一代数据处理利器Greenplum来助攻
作者:李树桓 个推数据研发工程师
前言:近年来,互联网的快速发展积累了海量大数据,而在这些大数据的处理上,不同技术栈所具备的性能也有所不同,如何快速有效地处理这些庞大的数据仓,成为很多运营者为之苦恼的问题!随着Greenplum的异军突起,以往大数据仓库所面临的很多问题都得到了有效解决,Greenplum也成为新一代海量数据处理典型代表。本文结合个推数据研发工程师李树桓在大数据领域的实践,对处理庞大的数据量时,如何选择有效的技术栈做了深入研究,探索出Greenplum是当前处理大数据仓较为高效稳定的利器。
一、Greenplum诞生的背景
时间回到2002年,那时整个互联网数据量正处于快速增长期,一方面传统数据库难以满足当前的计算需求,另一方面传统数据库大多基于SMP架构,这种架构最大的一个特点是共享所有资源,扩展性能差,因此面对日益增长的数据量,难以继续支撑,需要一种具有分布式并行数据计算能力的数据库,Greenplum正是在此背景下诞生了。
和传统数据库的SMP架构不同,Greenplum主要基于MPP架构,这是由多个服务器通过节点互联网络连接而成的系统,每个节点只访问自己的本地资源(包括内存、存储等),是一种完全无共享(Share Nothing)结构,扩展能力较之前有明显提升。

二、解读 Greenplum架构
Greenplum主要由Master主节点和Interconnect网络层以及负责数据存储和计算的多个节点共同组成。
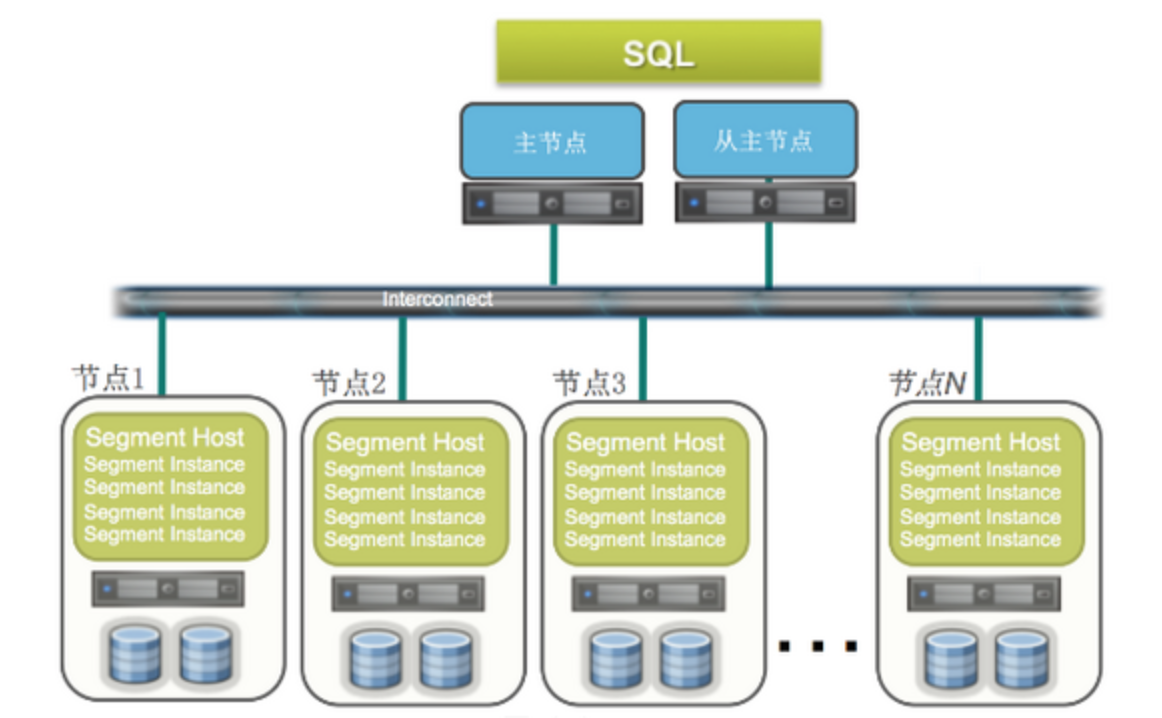
Master上有主节点和从节点两部分,两者主要的功能是生成查询计划并派发,以及协调Segment并行计算,同时在Master上保存着global system catalog,这个全局目录存着一组Greenplum数据库系统本身所具有的元数据的系统表。需要说明的是Master本身不参与数据交互,Greenplum所有的并行任务都是在Segment的数据节点上完成的,因此,Master节点不会成为数据库的性能瓶颈。
中间的网络层Interconnect,主要负责并行查询计划生产和Dispatch分发以及协调节点上QE执行器的并行工作, 正是因为Interconnect的存在,Greenplum才能实现对同一个集群中多个PostgreSQL实例的高效协同和并行计算。
整个结构图下方负责数据存储和计算的每个节点上又有多个实例,每个实例都是一个PostgreSQL数据库,这些实例共享节点的IO和CPU。PostgreSQL在稳定性和性能方面较为先进,同时又有丰富的语法支持,满足了Greenplum的功能需要。
三、了解Greenplum优势
Greenplum之所以能成为处理海量大数据的有效工具,与其所具备的几大优势密不可分。
优势一:计算效率提升
Greenplum的数据管道可以高效地将数据从磁盘传输到CPU,而目前市面上常用的计算引擎SPARK在传输数据时,则需要为每个并发查询分配一个内存,这对大型数据集的查询十分不利,而Greenplum所具备的实时查询功能,能够有效对大数据集进行计算。
优势二:扩展性能增强
Greenplum基于的MPP架构,节点之间完全不共享,同时又可以达到并行查询,因此在进行线性扩展时,数据规模可以达到PB级别。目前,Greenplum已经实现了开源,并且社区生态活跃,对于使用者而言,也会觉得更为可靠。
优势三:功能性优化
Greenplum可以支持复杂的SQL查询,大幅简化了数据的操作和交互过程。而目前流行的HAWQ、Spark SQL、Impala等技术基本都基于MapReduce进行的优化,虽然部分也使用了SQL查询,但是对SQL的支持十分有限。
四、Greenplum的容错机制
Greenplum数据库简称GPDB,它拥有丰富的特性,支持多级容错机制和高可用。
1)主节点高可用:为了避免主节点单点故障,特别设置一个主节点的副本(称为 Standby Master),通过流复制技术实现两者同步复制,当主节点发生故障时,从节点可以成为主节点,从而完成用户请求并协调查询执行。
2)数据节点高可用:每个数据节点都可以配备一个镜像,它们之间通过文件操作级别的同步来实现数据的同步复制(称为filerep技术)。故障检测进程(ftsprobe)会定期发送心跳给各个数据节点,当某个节点发生故障时,GPDB会自动进行故障切换。
3)网络高可用:为了避免网络的单点故障,每个主机会配置多个网口,并使用多个交换机,避免网络故障时造成整个服务器不可用。
同时,GPDB具有图形化的性能监控功能,基于此功能,用户可以确定数据库当前的运行情况和历史查询信息,同时跟踪系统使用情况和资源信息。
五、 Greenplum在业务场景中的应用
个推在大数据领域深耕多年,在处理庞大的数据仓的过程中,也在不断进行优化和更新技术栈,在进行技术选型时,针对不同的技术栈做了如下对比:

总得来说,Greenplum帮助开发者有效解决了处理数据库时遇到的一些难点,比如跨天去重、用户自定义维度、复杂的SQL查询等问题,同时,也方便开发者直接在原始数据上进行实时查询,减少了数据聚合过程中的遗失,当然,强大的Greenplum仍存在着一些问题需要去完善,例如在节点扩展的过程中元数据的管理问题,分布式数据库在扩展节点时会带来数据一致性,扩展的过程中有时会出现元数据混乱的情况等等,好在Greenplum有很多优秀的运维工具,能够帮我们在发生问题及时进行排查,更好的保障业务的稳定性。但是,尽管Greenplum在处理大数据方面的优势比较明显,对开发者来说,还是要根据自身需求选择相应的技术栈。
数据量越发庞大怎么办?新一代数据处理利器Greenplum来助攻的更多相关文章
- 海量数据处理利器greenplum——初识
简介及适用场景 如果想在数据仓库中快速查询结果,可以使用greenplum. Greenplum数据库也简称GPDB.它拥有丰富的特性: 第一,完善的标准支持:GPDB完全支持ANSI SQL 200 ...
- 海量数据处理利器greenplum——初识
简介及适用场景 如果想在数据仓库中快速查询结果,可以使用greenplum. Greenplum数据库也简称GPDB.它拥有丰富的特性: 第一,完善的标准支持:GPDB完全支持ANSI SQL 200 ...
- 对MySQL数据量日益增长产生的一点小想法
最近一直在想一个问题 MySQL数据量日益庞大,目前单表总记录数有 300W+,导致sql语句执行的速度变慢,如果一直这样增长下去,总有一天会爆炸的.怎么办??怎么办?? 第一:想到的必然是 添加索引 ...
- Salesforce 大数据量处理篇(二)Index
本篇参考: https://developer.salesforce.com/docs/atlas.en-us.202.0.salesforce_large_data_volumes_bp.meta/ ...
- php 大数据量及海量数据处理算法总结
下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能并不能完全覆盖所有的问题,但是这样的一些方法也基本可以处理绝大多数遇到的问题.下面的一些问题基本直接来源于公司的面试笔试题目, ...
- sql 数据库 庞大数据量 需要分表
17:04:05问下 在什么情况下 审核分区啊 ~..大熊..o○ 17:06:53这个要看应用~..大熊..o○ 17:07:37比如数据量很大,查询多是按照时间段查询,就可以用时间段来做分区~.. ...
- BloomFilter–大规模数据处理利器(转)
BloomFilter–大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求1 ...
- BloomFilter–大规模数据处理利器
转自: http://www.dbafree.net/?p=36 BloomFilter–大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法. ...
- BloomFilter ——大规模数据处理利器
BloomFilter——大规模数据处理利器 Bloom Filter是由Bloom在1970年提出的一种多哈希函数映射的快速查找算法.通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求 ...
随机推荐
- [python]记录Windows下安装matplot的经历
最近学习在看<机器学习实战>一书,第二章的时候要用到Natplotlib画图,于是便开始安装Matplotlib.本文所用到的所有安装包都可以在文末的链接中找到. 首先从Matplotli ...
- UCOSII笔记---信号量、邮箱、消息队列、信号量集、软件定时器
一.接收邮箱函数的参数:timeout表示的是滴答定时器的节拍数,比如设定5ms为一个节拍,超时为100ms,则timeout=20. void *OSMboxPend (OS_EVENT *peve ...
- libgdx自制简易版Don't Touch The White Tile
Don't Toutch The White说来也奇快,本来没什么难的,但是在欧美ios榜上却雄踞榜首好长时间.即使是在国内,也很火,还真是想不通,谁能解释下,难道真是所谓的抓住了用户的G点,或是这些 ...
- effective c++ 笔记 (3-4)
//---------------------------15/03/26---------------------------- 3:const函数的哲学思辨:就当是科普知识吧!如果成员函数是con ...
- Dive查看docker镜像层信息
1.主要采用docker运行dive的方式,不然宿主机还要安装go那些挺麻烦的.具体用法可查看官方: https://github.com/wagoodman/dive 2.拉取dive镜像 dock ...
- CryptoZombies学习笔记——Lesson2
第二课是僵尸猎食,将把app变得更像一个游戏,添加多人模式,建立更多创造僵尸的方法. chapter1 依然是简介 chapter2:映射和地址 映射相当于一个索引,指向不同地址,不同地址存储的数据不 ...
- Scrum Meeting day 2
第二次会议,开发人员会议 . • 前端: 1. 登陆界面,login, sign up, 添加加载时的图片. 2. 主界面:采用类微信类型.应含有联系人.群聊.设置 3. ...
- Linux内核分析(第二周)
操作系统是如何工作的? 一.总结:三大法宝 1.存储程序计算机 + 函数调用堆栈 + 中断机制 2.堆栈:C语言程序运行时候必须的一个记录调用路径和参数的空间(函数调用框架/提供局部变量/传递参数/保 ...
- 四则运算APP,团队项目之需求
队名:IG.Super 成员:范铭祥,曾威,刘恒,黄伟俊. 一.程序功能需求 程序可以出带括号的正整数四则运算,支持分数,除法保留两位小数,如:(1/3+1)*2 = 2.67,特别注意:这里是2.6 ...
- A-Softmax的总结及与L-Softmax的对比——SphereFace
A-Softmax的总结及与L-Softmax的对比--SphereFace \(\quad\)[引言]SphereFace在MegaFace数据集上识别率在2017年排名第一,用的A-Softmax ...