python爬虫 抓取一个网站的所有网址链接

作者QQ:231469242
关键字:爬虫,网址抓取,python
测试
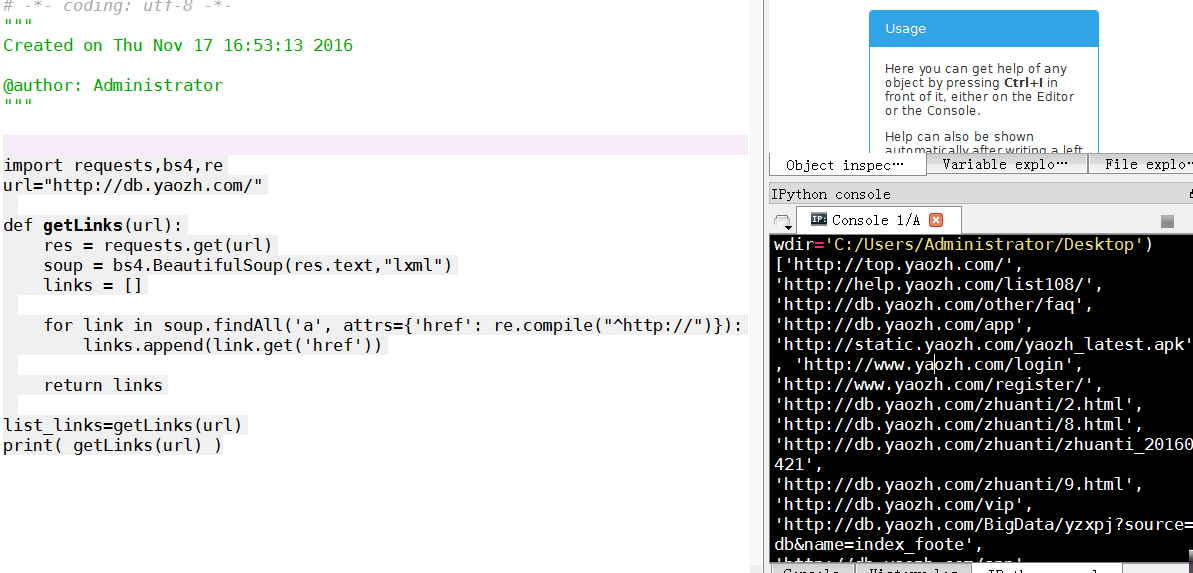
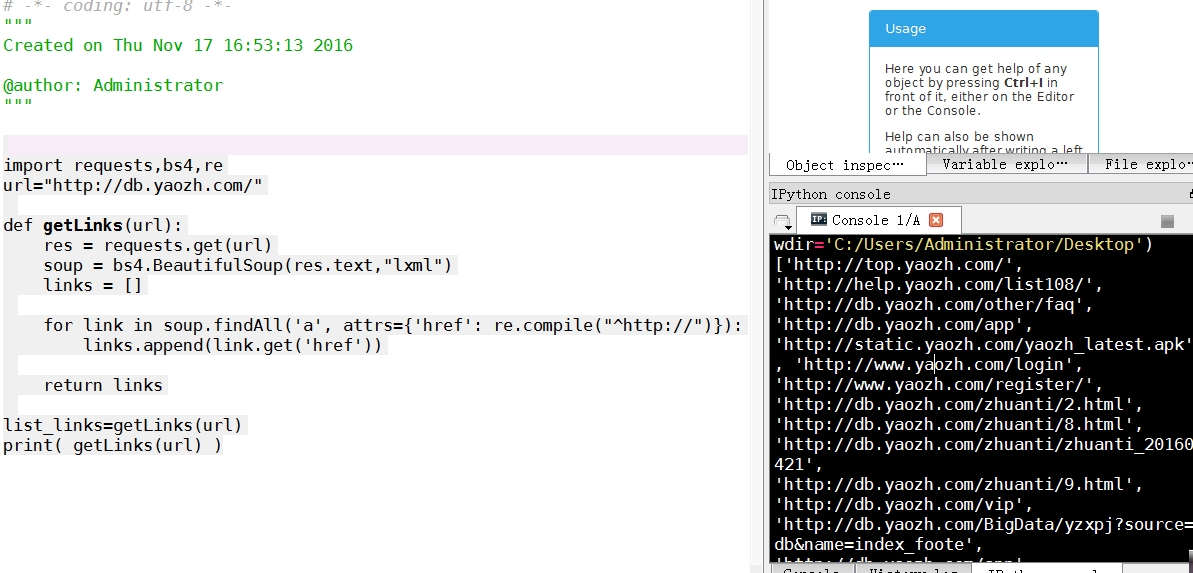
url=http://db.yaozh.com/
import requests,bs4,re
url="http://db.yaozh.com/" def getLinks(url):
res = requests.get(url)
soup = bs4.BeautifulSoup(res.text,"lxml")
links = [] for link in soup.findAll('a', attrs={'href': re.compile("^http://")}):
links.append(link.get('href')) return links list_links=getLinks(url)
print( getLinks(url) )
测试
url=http://www.yaozh.com
网址共121个
['http://db.yaozh.com', 'http://www.yaozh.com/zhihui', 'http://s.yaozh.com', 'http://news.yaozh.com', 'http://star.yaozh.com', 'http://club.yaozh.com/', 'http://edu.yaozh.com/', 'http://bbs.yaozh.com', 'http://www.35yao.com/', 'http://top.yaozh.com/', 'http://www.yaozh.com/', 'http://news.yaozh.com', 'http://db.yaozh.com', 'http://www.yaozh.com/zhihui', 'http://s.yaozh.com', 'http://bbs.yaozh.com', 'http://club.yaozh.com/', 'http://edu.yaozh.com/', 'http://star.yaozh.com/', 'http://top.yaozh.com/', 'http://db.yaozh.com/Zhuanti/zhuanti_20160721?source=www&name=index_slide', 'http://bbs.yaozh.com/thread-260886-1-1.html?source=www&name=index_slide', 'http://edu.yaozh.com/Course/84.html?source=www&name=index_slide', 'http://bbs.yaozh.com/thread-262781-1-1.html?source=www&name=index_slide', 'http://db.yaozh.com/pqf?source=www&position=index_newdb', 'http://db.yaozh.com/orangebook?source=www&position=index_newdb', 'http://db.yaozh.com/qxzhuce?source=www&position=index_newdb', 'http://db.yaozh.com/yfpw?source=www&name=index_newdb', 'http://db.yaozh.com/orangebook?source=www&name=long_banner', 'http://news.yaozh.com/Detail/index/id/16689.html', 'http://s.yaozh.com/Article/index?id=48?source=www&name=long_banner', 'http://bbs.yaozh.com/thread-262329-1-1.html?source=www&name=long_banner', 'http://bbs.yaozh.com/thread-216363-1-1.html', 'http://s.yaozh.com/3832', 'http://s.yaozh.com/3122', 'http://s.yaozh.com/1389', 'http://s.yaozh.com/1952', 'http://s.yaozh.com/4043', 'http://s.yaozh.com/4058', 'http://s.yaozh.com/3858', 'http://s.yaozh.com/1392', 'http://db.yaozh.com?source=www&name=long_banner', 'http://db.yaozh.com/app?source=www&name=db_left', 'http://news.yaozh.com/archive/12393.html', 'http://news.yaozh.com/archive/12275.html', 'http://news.yaozh.com/archive/12218.html', 'http://news.yaozh.com/archive/12138.html', 'http://news.yaozh.com/archive/11449.html', 'http://news.yaozh.com/archive/11340.html', 'http://news.yaozh.com/archive/11026.html', 'http://news.yaozh.com/archive/10433.html', 'http://news.yaozh.com/archive/10219.html', 'http://news.yaozh.com/archive/10206.html', 'http://news.yaozh.com/archive/9732.html', 'http://news.yaozh.com/archive/9648.html', 'http://news.yaozh.com/archive/9373.html', 'http://news.yaozh.com/archive/9279.html', 'http://news.yaozh.com/archive/8806.html', 'http://news.yaozh.com/archive/8479.html', 'http://news.yaozh.com/archive/8480.html', 'http://news.yaozh.com/archive/7897.html', 'http://news.yaozh.com/archive/7898.html', 'http://news.yaozh.com/archive/7899.html', 'http://db.yaozh.com/zhuangrang?from=www&position=index_hotdb', 'http://db.yaozh.com/zhuce?from=www&position=index_hotdb', 'http://db.yaozh.com/yaopinzhongbiao?from=www&position=index_hotdb', 'http://db.yaozh.com/index.php?action=foreign?from=www&position=index_hotdb', 'http://db.yaozh.com/screening?from=www&position=index_hotdb', 'http://db.yaozh.com/jiegou?from=www&position=index_hotdb', 'http://db.yaozh.com/vip/custom.html?source=www&name=db_right', 'http://www.xinyaohui.com', 'http://www.cqyjs.com/index.html', 'http://www.reed-sinopharm.com/', 'http://www.bucm.edu.cn', 'http://pharmacy.scu.edu.cn/', 'http://www.cqmu.edu.cn/', 'http://www.cqacmm.com/', 'http://www.cpri.com.cn/', 'http://www.cpu.edu.cn/', 'http://pharmacy.swu.edu.cn', 'http://www.mypharma.com', 'http://www.psyzg.com/', 'http://www.viptijian.com/0592', 'http://www.7lk.com/', 'http://www.j1.com/pd-baojianpin.html', 'http://www.3156.cn/', 'http://www.sdyyzs.cn', 'http://www.jiankangle.com', 'http://www.rmttjkw.com', 'http://www.sunyet.com', 'http://www.chinayikao.com/', 'http://www.hxyjw.com/ ', 'http://www.100xhs.com/ask/ ', 'http://www.360zhengrong.com/', 'http://www.ftxk.cn/', 'http://www.jianke.com/zypd/', 'http://www.medlive.cn/', 'http://health.qqyy.com/', 'http://www.wendaifu.com/', 'http://health.cqnews.net/', 'http://www.yaofu.cn/', 'http://www.ipathology.cn/', 'http://nk.99.com.cn/', 'http://www.baxsun.cn/', 'http://www.yiliu88.com ', 'http://www.wiki8.com/', 'http://www.39kf.com/', 'http://www.10000yao.com', 'http://www.3618med.com', 'http://www.chem960.com', 'http://www.yaojobs.com', 'http://www.hc3i.cn/', 'http://about.yaozh.com/about.html', 'http://about.yaozh.com/contact.html', 'http://about.yaozh.com/Qualification.html', 'http://about.yaozh.com/join.html', 'http://about.yaozh.com/link.html', 'http://help.yaozh.com/', 'http://bbs.yaozh.com/forum-123-1.html', 'http://bbs.yaozh.com', 'http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=50010802001068']
测试3
url=http://www.dxy.cn/
丁香园网址链接是501个
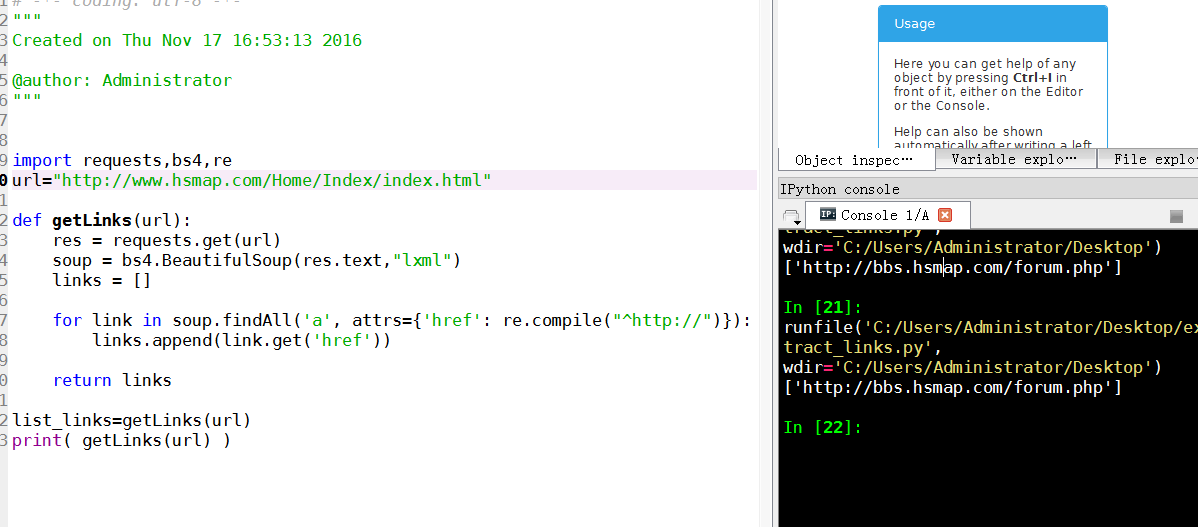
测试4
url=http://www.hsmap.com
只有一个链接

python爬虫 抓取一个网站的所有网址链接的更多相关文章
- Python 爬虫-抓取中小企业股份转让系统公司公告的链接并下载
系统运行系统:MAC 用到的python库:selenium.phantomjs等 由于中小企业股份转让系统网页使用了javasvript,无法用传统的requests.BeautifulSoup库获 ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- Python爬虫抓取某音乐网站MP3(下载歌曲、存入Sqlite)
最近右胳膊受伤,打了石膏在家休息.为了实现之前的想法,就用左手打字.写代码,查资料完成了这个资源小爬虫.网页爬虫, 最主要的是协议分析(必须要弄清楚自己的目的),另外就是要考虑对爬取的数据归类,存储. ...
- Python 爬虫: 抓取花瓣网图片
接触Python也好长时间了,一直没什么机会使用,没有机会那就自己创造机会!呐,就先从爬虫开始吧,抓点美女图片下来. 废话不多说了,讲讲我是怎么做的. 1. 分析网站 想要下载图片,只要知道图片的地址 ...
- Python爬虫 -- 抓取电影天堂8分以上电影
看了几天的python语法,还是应该写个东西练练手.刚好假期里面看电影,找不到很好的影片,于是有个想法,何不搞个爬虫把电影天堂里面8分以上的电影爬出来.做完花了两三个小时,撸了这么一个程序.反正蛮简单 ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
随机推荐
- Page结构
SQL Server存储数据的基本单元是Page,每一个Page的大小是8KB,数据文件是由Page构成的.在同一个数据库上,每一个Page都有一个唯一的资源标识,标识符由三部分组成:db_id,fi ...
- JavaScript快速入门-ECMAScript本地对象(Array)
Array对象 Array对象和python里面的list对象一样,是用来存储多个对象值的对象,且方法和属性基本上类似. 一.属性 lenght 二.方法 1.concat() 用于连接两个或多个 ...
- svn插件下载的两种方式
1.下载SVN插件 SVN插件下载地址及更新地址,你根据需要选择你需要的版本.现在最新是1.8.x Links for 1.8.x Release: Eclipse up ...
- Asp.Net_后台代码访问前台html标签
//单击按钮后批量改变li元素的内联文本值及样式 ; i <= ; i++) { HtmlGenericControl li = this.FindControl("li" ...
- Js_图片轮换
本文介绍用javascript制作图片轮换效果,原理很简单,就是设置延时执行一个切换函数,函数里面是先设置下面的缩略图列表的白框样式,再设置上面大图的src属性,在IE中显示很正常,可是在FF中会有变 ...
- Unity2D 面向目标方向
在2d空间上,假设角色的自身的y轴方向为正方向,如果要让角色随时面向一个目标点. 这里假设(0,0)点为目标点 第一种: Vector3 v = Vector3.zero - transform.po ...
- 谷歌算法研究员:我为什么钟爱PyTorch?
老铁们好!我是一名前谷歌的算法研究员,处理深度学习相关项目已有三年经验,接下来会在平台上给大家分享一些深度学习,计算机视觉和统计机器学习的心得体会,当然了内推简历一定是收的.这篇文章,不想说太多学术的 ...
- .net中操作Visual SourceSafe
最近整理一些资料,发现以前写的一段代码,提供对微软的版本管理软件visual sourcesafe的一些操作.以下简称vss. 想起以前写的时候,因为资料比较匮乏,只能边研究边测试,走了不少弯路. 由 ...
- linux读书笔记(5章)
linux读书笔记(5章) 标签(空格分隔): 20135328陈都 第五章 系统调用 5.1 与内核通信 系统调用 让应用程序受限的访问硬件设备 提供创建新进程并与已有进程通信的机制 提供申请操作系 ...
- ibmv7000查看序列号
ssh后 命令:lsenclosure 有以下数据 id status type managed IO_group_id IO_group_name product_MTM serial ...