sql语句之where子句
现在的登录都是把信息存在数据库,然后把输入的与数据库内容进行匹配,一样就登录成功,否则不成功。验证码是为了防止暴力破解,因为计算机能够自动匹配密码,但是不能识别图片上的字母,只有人能识别,所以匹配的速度会减慢。还有的会记录登录IP,如果IP频繁变化就会进行提示。还有银行会限制输入次数。
作用
限制表中的数据返回 符合where后面的条件的数据就会被选中,不符合where条件的语句会被过滤掉
两个极限条件
/*这是永真条件*/ (数据库里可以有注释,这里是多行注释)
where 1 = 1 ; (用一个等号判断相不相等,因为这里是不存在赋值的,没有“= =”)
- - 这是永假条件(数据库里可以有注释,这里是单行注释,注释符和注释之间要有空格)
where 1 = 2 ;
演示:列出每个员工的id 和salary 要求显示符合salary等于1400的员工
select id, salary from s_emp where salary=1400

字符串条件的表达
演示:要求显示first_name 是Carmen的员工,列出id first_name salary
select id, first_name, salary from s_emp where first_name='Carmen'

注意:一定要加’ ‘代表这是字符串值
常见的运算符
= 等于 != 不等于 >大于 < 小于 <= 小于等于 ................
sql提供的运算符
表达一个闭区间[a , b]
where 字段 between a and b ; (字段在闭区间a到b内)
a b的顺序不能错
演示:写程序查询,把s_emp表中id first_name salary 显示;要求salary在[1450,2500 ] 中。
select id, first_name, salary from s_emp where salary between 1450 and 2500

注意:不可以把2500和1450调换位置,编译不会有错,但逻辑有错)
where 字段 in(值1,值2,值3)
这个字段的值等于其中的一个值(只要有一个等于就返回), 交换值的顺序可能有影响,也可能没有影响。若值的概率都一样就没有影响(就按一个规律写(比如从小到大),这样不容易遗漏)。若不一样,则把概率高的值放在前面(人为的),这样查询效率高(因为每个数据都要挨个和给的值比较,只要有一个一样就返回)
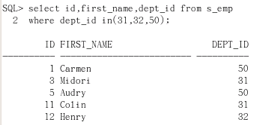
演示:写一个查询,把s_emp表中部门标号是31或者32或者50 部门的员工id first_name dept_id显示出来
select idm first_name, dept_id from s_emp where dept_id in(31, 32, 50)
模糊查询 like(像)+ 通配符
数据库里:
- “%”为通配符,代表0 - n个任意字符
- “-”代表一个任意字符
e.g. 李四 李斯 李思 李世民 (查找出姓李的)
Where name like ‘李%’;
e.g. 李小龙 小龙女 龙猫 (查找出所有带龙的)
Where name like ‘%龙%;
(找出中间带龙的)where name like ‘_龙%’;
演示:查询s_emp表中first_name,找出所有带a(小写a)的
select first_name from s_emp where first_name like '%a%'

数据库中有一张表user_tables(数据字典,存的都是大写)存了所有表的信息。例如s_emp s_dept 等
desc user

演示:从user_tables中找出所有以‘S_’开头的表名
注意:要对‘_’进行转义处理,用‘\_’表示下划线,再加escape ‘ \ ’ 代表是‘\’ 后面的内容进行转义处理
select table_name from user_tables where table_name like 'S\_%'

NULL值的判断
where 字段 is NULL ;
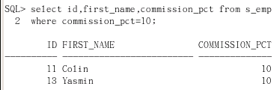
演示:把s_emp表中提成是10的员工的id first_name commission_pct显示出来
select id, first_name, commission_pct from s_emp where commission_pct=10
演示:把s_emp表中提成不是10的员工的id first_name commission_pct显示出来。
select id, first_name, commission_pct from s_emp where commission_pct!=10
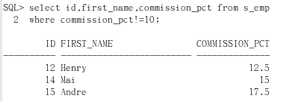
按理来说,一共有25人,不为10的人应该是20个的,但是这里只有3个。这是因为,基本的判定对空值是无效的,必须引入is NULL对控制进行判定所以要:
select id, first_name, commission_pct from s_emp where commoission_pct is NULL

当然也可以结合nvl,但是用is NULL是标准用法。
条件连接符号
- and 逻辑与
- or 逻辑或
- not 非
演示:(1)写程序查询,把s_emp表中id first_name salary 显示;要求salary在[1450,2500 ] 中。(between 。。。and。。。)
select id, first_name ,salary from s_emp where salary>=1450 and salary<=2500
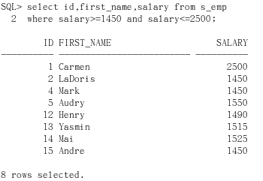
用这个更加具有通用性,可以是开区间。
(2)写一个查询,把s_emp表中部门标号是31或者32或者50 部门的员工id first_name dept_id显示出来(5.6.2里的in(。。,。。,。。))
select id, first_name, dept_id from s_emp where dept_id-31 or dept_id-32 or dept_id=50
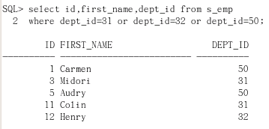
这里三个都是等价的,不存在顺序问题。
- > 的对立面是 <=
- < 的对立面是 >=
- = 的对立面是 != ^= < > (都是不等于)
- between a and b 的对立面是 not between a and b
- in 的对立面是 not in
- like 的对立面是 not like
- is null 的对立面是 is not null(只有最后一个不用注意空值,上面的都要注意空值)
演示:找出manager_id不是空的员工,列出id first_name manager_id
select id, first_name, manager_id from s_emp where manager_id is not null
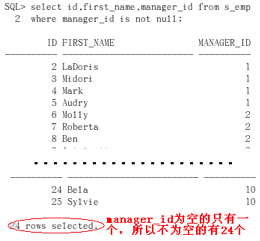
条件优先的问题 要优先的部分加括号
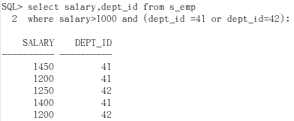
演示:(1)显示员工salar dept_id;
要求工资大于1000且部门标号为41的员工,或者部门标号为42的员工
select salary, dept_id from s_emp where salary>1000 and dept_id=41 or dept_id=42

(2)显示员工salar dept_id;
要求部门标号为41的员工,或者为42的员工里工资大于1000的
select salary, dept_id from s_emp where salary>1000 and (dept_id=41 or dept_id=42)
sql语句之where子句的更多相关文章
- SQL语句之on子句过滤和where子句过滤区别
1.测试数据: SQL> select * from dept; DEPTNO DNAME LOC ------ -------------- ------------- ...
- sql语句之from子句
如何从表中查询一个字端的数据 select 字段名 from 表名: 演示:从s_emp表中把月薪查询出来 select salary from s_emp ; (分号代表结束) 如何从表中查询 ...
- 数据库性能调优——sql语句优化(转载及整理) —— 篇1
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实 ...
- 数据库性能优化之SQL语句优化
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的编写等是体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...
- SQL优化的四个方面,缓存,表结构,索引,SQL语句
一,缓存 数据库属于 IO 密集型的应用程序,其主要职责就是数据的管理及存储工作.而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个IO是在毫秒级别,二者相差3个数量级.所 ...
- 数据库 SQL语句优化
温馨提示:本篇内容均来自网上,本人只做了稍微处理,未进行细致研究,仅当做以后不备之需,如若你喜欢可尽情转走. 一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图 ...
- 优化的四个方面,缓存,表结构,索引,SQL语句
一,缓存 数据库属于 IO 密集型的应用程序,其主要职责就是数据的管理及存储工作.而我们知道,从内存中读取一个数据库的时间是微秒级别,而从一块普通硬盘上读取一个IO是在毫秒级别,二者相差3个数量级.所 ...
- 数据库性能优化之SQL语句优化(上)
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统的 ...
- [转]数据库性能优化之SQL语句优化1
一.问题的提出 在应用系统开发初期,由于开发数据库数据比较少,对于查询SQL语句,复杂视图的的编写等体会不出SQL语句各种写法的性能优劣,但是如果将应用系统提交实际应用后,随着数据库中数据的增加,系统 ...
随机推荐
- Android 四大组件之“ BroadcastReceiver ”
前言 Android四大组件重要性已经不言而喻了,今天谈谈的是Android中的广播机制.在我们上学的时候,每个班级的教室里都会装有一个喇叭,这些喇叭都是接入到学校的广播室的,一旦有什么重要的通知,就 ...
- Spring AOP 源码分析 - 创建代理对象
1.简介 在上一篇文章中,我分析了 Spring 是如何为目标 bean 筛选合适的通知器的.现在通知器选好了,接下来就要通过代理的方式将通知器(Advisor)所持有的通知(Advice)织入到 b ...
- VNC黑屏解决办法
在Linux里安装配置完VNC服务端,发现多用户登陆会出现黑屏的情况,具体的现象为:客户端可以通过IP与会话号登陆进入系统,但登陆进去是漆黑一片,除了一个叉形的鼠标以外,伸手不见五指. 原因:用户的V ...
- Info - Get technical information from the Internet
Official Sites Overview / QuickStart Guide / Docs / E-books Community / Fourm / Blog Demo / Download ...
- 初印象至Vue路由
初印象系列为快速了解一门技术的内容,后续会推出本人应用这门技术时发现的一些认识. Vue路由和传统路由的区别: Vue路由主要是用来实现单页面应用内各个组件之间的切换,同样支持传递参数等功能.而传统路 ...
- 集合框架_DAY15
1:集合(掌握) (1)集合的由来 我们需要对多个对象进行存储和获取.可以使用对象数组.但是,如果对象的个数是变化的,对象数组就解决不了了.怎么办呢?java就提供了集合类解决. (2)集合和数组的区 ...
- Android 开发工具类 35_PatchUtils
增量更新工具类[https://github.com/cundong/SmartAppUpdates] import java.io.File; import android.app.Activity ...
- 详解C#泛型(三)
一.前面两篇文章分别介绍了定义泛型类型.泛型委托.泛型接口以及声明泛型方法: 详解C#泛型(一) 详解C#泛型(二) 首先回顾下如何构建泛型类: public class MyClass<T&g ...
- js便签笔记(6)——jQuery中的ready()事件为何需要那么多代码?
前言: ready()事件的应用,是大家再熟悉不过的了,学jQuery的第一步,最最常见的代码: jQuery(document).ready(function () { }); jQuery(fun ...
- 和我一起打造个简单搜索之ElasticSearch集群搭建
我们所常见的电商搜索如京东,搜索页面都会提供各种各样的筛选条件,比如品牌.尺寸.适用季节.价格区间等,同时提供排序,比如价格排序,信誉排序,销量排序等,方便了用户去找到自己心里理想的商品. 站内搜索对 ...