论文笔记 - RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Motivation
虽然半监督学习减少了大量数据标注的成本,但是对计算资源的要求依然很高(无论是在训练中还是超参搜索过程中),因此提出想法:由于计算量主要集中在大量未标注的数据上,能否从未标注的数据中检索出重要的数据(Coreset)呢?
Analysis
当前用来半监督学习的方案:
- 自洽正则化(Consistency Regularization):自洽正则化的思路是,对未标记数据进行数据增广(加入噪声等),产生的新数据输入分类器,预测结果应保持自洽。即同一个数据增广产生的样本,模型预测结果应保持一致。
- 最小化熵(Entropy Minimization):许多半监督学习方法都基于一个共识,即分类器的分类边界不应该穿过边际分布的高密度区域。具体做法就是强迫分类器对未标记数据作出低熵预测。
半监督学习能够成功实施的必要条件:有标签的数据和无标签的数据来自相同的分布。否则会导致模型性能的大幅度下降。因此 DS3L 将其转化为了一个双层的优化问题:
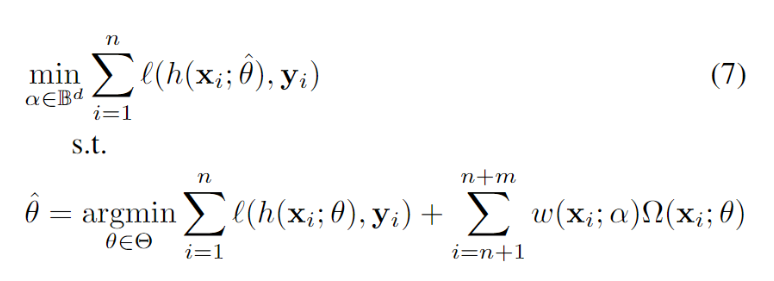
下面的式子和普通的半监督学习一直,不过在无标签正则化项(自洽正则化或最小化熵)前加上了权重参数,权重参数由什么决定:越不影响模型在有标签数据上的表现的数据权重越大;
换句话说:你用一个无标签的数据 A 更新了参数,结果发现更新玩参数的模型在有标签的数据集上表现变差了,那么 A 就是 OOD 或者有巨大噪声的数据,他的权重越小越好,权重为 0 表示不要 A 这个数据了。
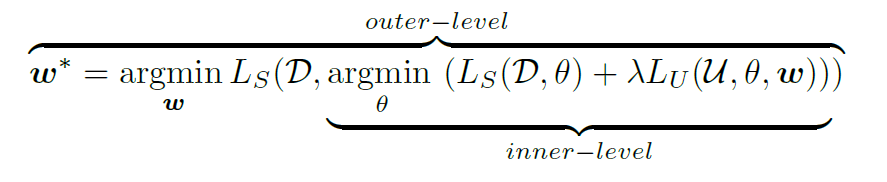
上图:双层优化。
我们选取 Coreset 的出发点也是一样:选择一个无标签数据的子集 $S_t$,使得在这个子集上半监督训练出的参数,在有标签数据上的误差最小,同样是个双层优化。
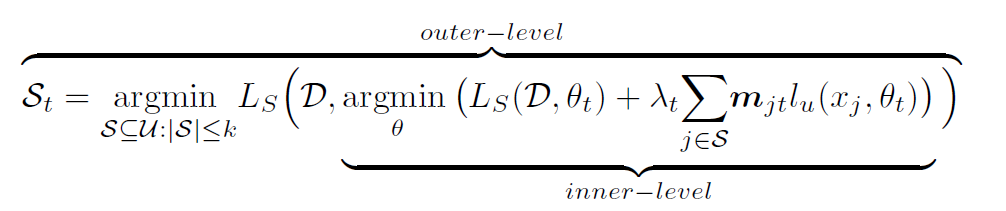
但是这个式子明显是不可解的,首先我们需要遍历出所有的 $S_t$ 组合,对每一种组合应用半监督训练使其收敛,用收敛后的模型权重应用到有标签数据计算准确率,再用这个准确率评估我们选的子集怎么样,复杂度不可想象。
因此用近似的方法进行转化,转化为一层的优化问题:
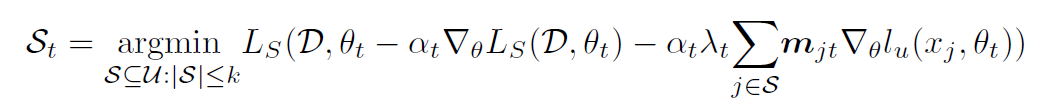
上图的核心思想是适应性的数据挑选,也就是说不是选一种 Coreset 就一次训练到收敛,而是根据训练进度逐渐调整 Coreset,直到得到最好的 Coreset:首先仍然遍历出所有的 $S_t$ 组合,对每一种组合计算半监督训练的损失函数,用这个损失函数优化一遍参数,只进行一次迭代,然后用更新后的模型对有标签的数据求准确度,再用这个准确率评估我们选的子集怎么样,因为这只是一步迭代,因此子集会不断更新。
相当理想了,但是计算复杂度依然是不可接受的,原因就在于最开始的遍历出所有的 $S_t$ 组合,因此作者又提出:当式子中的 $L_s$ 项(即有标签数据的损失项)是交叉熵形式的时候,整个式子就拥有了次模性,因此可以用贪心算法快速解决,同时保证收敛性和收敛速度,也就是原本开始时我们需要遍历所有的可能的 $S_t$ 组合,现在只需要遍历所有的可能加入 $S_t$ 的单个数据就可以了。加上符号,变成具有单调(增)性的次模函数:
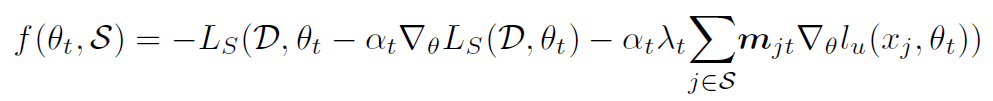
次模性的定义:

因此每次我们只需要挑选让这个次模函数增长最大的单个(无标签)数据,把他加到 Coreset 里面就行了。
作者说现在很好,但是我懒得一个一个计算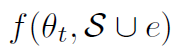 (也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
(也就是加上把单个无标签数据 e 加到 Coreset 里面后一次优化后,模型在有标签数据上的损失的负值)怎么办,别慌,可以用泰勒展开近似估计:
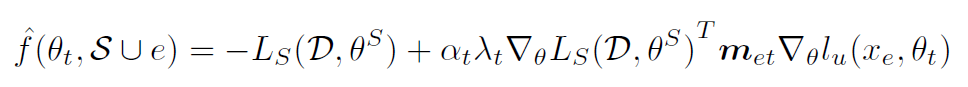
Algorithm

论文笔记 - RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning的更多相关文章
- 论文笔记之:Heterogeneous Image Features Integration via Multi-Modal Semi-Supervised Learning Model
Heterogeneous Image Features Integration via Multi-Modal Semi-Supervised Learning Model ICCV 2013 本文 ...
- 论文笔记(5):Fully Convolutional Multi-Class Multiple Instance Learning
这篇论文主要介绍了如何使用图片级标注对像素级分割任务进行训练.想法很简单却达到了比较好的效果.文中所提到的loss比较有启发性. 大体思路: 首先同FCN一样,这个网络只有8层(5层VGG,3层全卷积 ...
- 【转载】论文笔记系列-Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
一. 引出主题¶ 深度学习领域一直存在一个比较严重的问题——“灾难性遗忘”,即一旦使用新的数据集去训练已有的模型,该模型将会失去对原数据集识别的能力.为解决这一问题,本文提出了树卷积神经网络,通过先将 ...
- 论文笔记之:Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach
Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach 2017.11.28 Introductio ...
- 论文笔记:(TOG2019)DGCNN : Dynamic Graph CNN for Learning on Point Clouds
目录 摘要 一.引言 二.相关工作 三.我们的方法 3.1 边缘卷积Edge Convolution 3.2动态图更新 3.3 性质 3.4 与现有方法比较 四.评估 4.1 分类 4.2 模型复杂度 ...
- 论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks
论文笔记-IGCV3:Interleaved Low-Rank Group Convolutions for Efficient Deep Neural Networks 2018年07月11日 14 ...
- 【论文笔记系列】AutoML:A Survey of State-of-the-art (下)
[论文笔记系列]AutoML:A Survey of State-of-the-art (上) 上一篇文章介绍了Data preparation,Feature Engineering,Model S ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN
论文笔记:Towards Diverse and Natural Image Descriptions via a Conditional GAN ICCV 2017 Paper: http://op ...
随机推荐
- MySQL设置字段从指定数字自增,比如10000
MySQL设置字段从指定数字自增,比如10000. 方式一 方式二 方式一 此时就解决了MySQL从指定数字进行自增 CREATE TABLE hyxxb( hyid INT AUTO_INCREME ...
- Python自学笔记6-列表有哪些常用操作
列表是Python中最重要的数据类型,它使用的频率非常非常的高,最大程度的发挥Python的灵活性. 和字符串一样,列表的操作方法也有很多.如果说一头钻进去,可能会导致学习没有重点.在这篇文章当中,首 ...
- BZOJ4212 神牛的养成计划 (字典树,bitset)
题面 Description Hzwer成功培育出神牛细胞,可最终培育出的生物体却让他大失所望- 后来,他从某同校女神 牛处知道,原来他培育的细胞发生了基因突变,原先决定神牛特征的基因序列都被破坏了, ...
- 【JDBC】学习路径4-分页查询
第一章:什么是分页查询呢? 简而言之,分页数 就是百度搜索引擎中的网页的页数. 分页查询,就是从数据库中提取一部分出来,给用户. 用处:减少服务器负担. 为了方便测试,我们先给数据库添加大量信息. 还 ...
- 用metasploit映射公网远程控制舍友电脑
用metasploit映射公网远程控制舍友电脑 Metasploit是一款开源的安全漏洞检测工具,可以帮助安全和IT专业人士识别安全性问题,验证漏洞的缓解措施,并管理专家驱动的安全性进行评估,提供真正 ...
- FusionCopmpute之CNA,VRM虚拟机安装
CNA和VRM安装步骤一样,需要修改的只有IP 按步骤创建 修改自己虚拟机想要存放的位置 需要把自己网络同样配置为仅主机(提前配好) 自己也可以修改至200G 虚拟机只是用多少取多少 CNA可以设置为 ...
- 学习ASP.NET Core Blazor编程系列二——第一个Blazor应用程序(中)
学习ASP.NET Core Blazor编程系列一--综述 学习ASP.NET Core Blazor编程系列二--第一个Blazor应用程序(上) 四.创建一个Blazor应用程序 1. 第一种创 ...
- Linux系统编程001--系统IO
1. 文件系统:用来存储.组织.管理文件的一套方式.协议 2. 文件 文件的属性:i-node唯一表示一个文件的存在与否 文件的内容 3. Linux系统如何实现文件的操作? 点击查看代码 硬件层: ...
- 关于mciSendString函数调用mp3音频的问题
先说结论:这个函数一定要调用MP3文件,手动改MP3格式无效,一定要保证下载源是MP3格式文件.具体可参考:https://blog.csdn.net/m0_46436640/article/deta ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...