jieba分词的功能和性能分析
jieba分词问题导引
用户词典大小最大可以有多大
用户词典大小对速度的影响
有相同前缀和后缀的词汇如何区分
对比百度分词的API
问题一:词典大小
从源码大小分析,整个jieba分词的源码总容量为81MB,其中系统词典dict.txt的大小为5.16MB,所以用户词典至少可以大于5.16MB,在从词典中的词语数量来看,系统词典的总的词语数共349047行,每一行包括词语、词频、词性三个属性,所以初步可以判断用户词典可以很大。
import pandas as pd
import numpy as np
import os
path = os.getcwd()
print(path)
dict_path = os.path.join(path, 'medical_dict')
#调用pandas的read_csv()方法时,默认使用C engine作为parser engine,而当文件名中含有中文的时候,用C engine在部分情况下就会出错。所以在调用read_csv()方法时指定engine为Python就可以解决问题了。
res = pd.read_csv(dict_path+'\\部位.txt',sep=' ',header=None,encoding='utf-8',engine='python')
res = res.append( pd.read_csv(dict_path+'\\疾病.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
res = res.append( pd.read_csv(dict_path+'\\检查.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
res = res.append( pd.read_csv(dict_path+'\\手术.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
res = res.append( pd.read_csv(dict_path+'\\药品.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
res = res.append( pd.read_csv(dict_path+'\\症状.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
res = res.append( pd.read_csv(dict_path+'\\中药.txt',sep=' ',header=None,encoding='utf-8',engine='python') )
print(res.count())
0 35885
1 35880
2 35880
将35885个医疗词典放入,远比系统词典小。之后导出为一个用户词典,代码如下:
res[2] = res[1]
res[1] = 883635
print(res.head())
res.to_csv(dict_path+'\\medicaldict.txt',sep=' ',header=False,index=False)
测试语句
#encoding=utf-8
import jieba
import jieba.posseg as pseg
import os
path = os.getcwd()
# 添加用户词典
jieba.load_userdict(path + "\\medical_dict\\medicaldict.txt")
print( path + "\\medical_dict\\medicaldict.txt" )
test_sent = (
"患者1月前无明显诱因及前驱症状下出现腹泻,起初稀便,后为水样便,无恶心呕吐,每日2-3次,无呕血,无腹痛,无畏寒寒战,无低热盗汗,无心悸心慌,无大汗淋漓,否认里急后重感,否认蛋花样大便,当时未重视,未就诊。")
words = jieba.cut(test_sent)
print('/'.join(words))
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Public\Documents\Wondershare\CreatorTemp\jieba.cache
Loading model cost 0.921 seconds.
Prefix dict has been built succesfully.
D:\code\jiebafenci\jieba\medical_dict\medicaldict.txt
患者/1/月前/无/明显/诱因/及/前驱/症状/下/出现/腹泻/,/起初/稀便/,/后/为/水样便/,/无/恶心/呕吐/,/每日/2/-/3/次/,/无/呕血/,/无/腹痛/,/无/畏寒/
寒战/,/无/低热/盗汗/,/无/心悸/心慌/,/无/大汗淋漓/,/否认/里急后重/感/,/否认/蛋/花样/大便/,/当时/未/重视/,/未/就诊/。
结果正常,判别一条症状的响应速度快,jieba分词是足以将所有的医疗词汇放入,对于性能的影响可以在进一步分析。
问题二:词典大小对效率的影响
35885个词语,1条测试语句
load time: 1.0382411479949951s
cut time: 0.0s
71770个词语,1条测试语句
load time: 1.4251623153686523s
cut time: 0.0s
1148160个词语
load time: 7.892921209335327s
cut time: 0.0s
逐渐变慢了
2296320个词语
load time: 15.106632471084595s
cut time: 0.0s
在本机已经开始变得很慢了
4592640个词语
load time: 30.660043001174927s
cut time: 0.0s
9185280个词语
load time: 56.30760192871094s
18370560个词语
load time: 116.30s
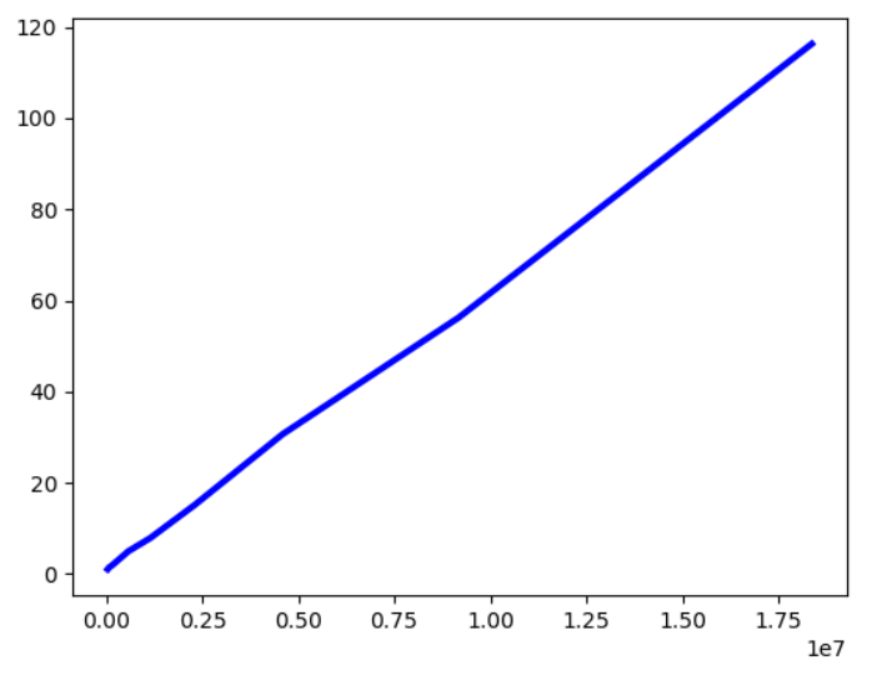
制作为折线图如上,基本上词语大小和加载速度呈正比。但是加载的词典一般保留在内存中,对内存和I/O负担较大。
之后将2220条病史数据导入后,对分词处理时间依然没有什么影响,在0.1s以内,分词时间可以忽略。
问题三:有相同前缀和后缀的词汇如何区分
关于无尿急、尿频、尿痛,在jieba分词导入用户词典后是能正确区分的,相关病例如下
/患者/3/小时/前/无/明显/诱因/出现/上/腹部/疼痛/,/左/上腹/为主/,/持续性/隐痛/,/无/放射/,/无/恶心/及/呕吐/,/无/泛酸/及/嗳气/,/无/腹胀/及/腹泻/,/无/咳嗽/及/咳痰/,/无/胸闷/及/气急/,/无/腰酸/及/腰疼/,/无/尿急/、/尿频/及/尿痛/,/无/头晕/,/无/黒/曚/,/无/畏寒/及/发热/,/无尿/黄/,/无/口苦/,/来/我院/求治/。
但是无尿黄划分成了无尿/黄,在查找用户词典后,发现是词典中没有尿黄的症状,为词典问题,便跳过处理。但是在症状中确实同时存在无尿和尿频,初步分析可能是词语在词典中的顺序,或者是jieba分词系统内部的分词策列导致,现在分析第一种可能,在词典中无尿在14221行,尿频在13561行,现在将无尿放在第一行,看分词结果。结果仍然为无/尿频,所以结果为是jieba分词内部的算法策略,当两个词语的词频相同是,后匹配的词语优先,比如在词语匹配中尿频比无尿后匹配,所以最后区分尿频,这与正确的分法也相匹配。
再比如腰部酸痛,在部位中有腰部这个词语,在症状中也有腰部酸痛这个词语,测试jieba分词会如何区分
测试词典:
腰部 883635
酸痛 883635
腰部酸痛 883635
测试结果:
腰部酸痛
将词典顺序交换后,并将腰部和疼痛的词频都设置成大于883635的值后,结果仍然是腰部酸痛,所以可以得出jieba分词更倾向于分长度更长的词语,即使短的词语的词频较大也会优先分长度更长的。而我去向自己学医的同学了解后,他也认为分成长词更合理,所以也不用处理。
在查看病例中,发现很多病例中存在方位名 + 部位名的词语,并且应该分成一个词语,如下代码实现添加方位名+部位名的词典,如词典中已经存在,便跳过。
res = pd.read_csv(dict_path+'\\部位.txt',sep=' ',header=None,encoding='utf-8',engine='python')
direct = ['上','下','左','右','前','后']
print(res[0].head())
resum = res[0].count()
print(resum)
result = res[0]
# 在部位名前加上方位名
for item in res[0].tolist():
if(item[0] in direct):
continue
else:
temp = Series(['左' + item, '右' + item], index = [resum+1,resum+2])
resum = resum + 2
result = result.append(temp)
print(result.tail())
df = pd.DataFrame(result)
print(df.describe())
百度分词
github地址 : https://github.com/baidu/lac/
实现代码
from LAC import LAC
# 装载分词模型
lac = LAC(mode='seg')
# 单个样本输入,输入为Unicode编码的字符串
text = u"LAC是个优秀的分词工具"
seg_result = lac.run(text)
# 批量样本输入, 输入为多个句子组成的list,平均速率会更快
texts = [u"腰部酸痛"]
lac.load_customization('userdict.txt', sep=None)
seg_result = lac.run(texts)
print(seg_result)
用户词典只需要添加词语和词性即可。经过测试得到结论:
1.百度分词无词频的概念,但是也更倾向于分长度更长的词语。
后匹配的词语优先,如无尿频,也会划分成无/尿频,与词典中的顺序无关。
jieba分词的功能和性能分析的更多相关文章
- 自然语言处理之jieba分词
在处理英文文本时,由于英文文本天生自带分词效果,可以直接通过词之间的空格来分词(但是有些人名.地名等需要考虑作为一个整体,比如New York).而对于中文还有其他类似形式的语言,我们需要根据来特殊处 ...
- jieba分词原理解析:用户词典如何优先于系统词典
目标 查看jieba分词组件源码,分析源码各个模块的功能,找到分词模块,实现能自定义分词字典,且优先级大于系统自带的字典等级,以医疗词语邻域词语为例. jieba分词地址:github地址:https ...
- profiler跟踪事件存为表之后性能分析工具
使用profiler建立跟踪,将跟踪结果存到表中,使用下面存储过程执行 exec temp_profiler 'tra_tablename'对表数据进行处理归类,然后进行性能分析 1.先建存储过程 2 ...
- SQL2005性能分析一些细节功能你是否有用到?(三)
原文:SQL2005性能分析一些细节功能你是否有用到?(三) 继上篇: SQL2005性能分析一些细节功能你是否有用到?(二) 第一: SET STATISTICS PROFILE ON 当我们比较查 ...
- SQL2005性能分析一些细节功能你是否有用到?(二)
原文:SQL2005性能分析一些细节功能你是否有用到?(二) 上一篇:SQL2005性能分析一些细节功能你是否有用到? 我简单的提到了些关于SQL性能分析最基本的一些方法,下面的文章我会陆续补充.前面 ...
- SQL2005性能分析一些细节功能你是否有用到?
原文:SQL2005性能分析一些细节功能你是否有用到? 我相信很多朋友对现在越来越大的数据量而感到苦恼,可是总要面对现实啊,包括本人在内的数据库菜鸟们在开发B/S程序时,往往只会关心自己的数据是否正确 ...
- 「功能笔记」性能分析工具gprof使用笔记
根据网上信息整理所成. 功能与优劣 gprof实际上只是一个用于读取profile结果文件的工具.gprof采用混合方法来收集程序的统计信息,它使用检测方法,在编译过程中在函数入口处插入计数器用于收集 ...
- Lucene.net(4.8.0) 学习问题记录五: JIEba分词和Lucene的结合,以及对分词器的思考
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- python结巴(jieba)分词
python结巴(jieba)分词 一.特点 1.支持三种分词模式: (1)精确模式:试图将句子最精确的切开,适合文本分析. (2)全模式:把句子中所有可以成词的词语都扫描出来,速度非常快,但是不能解 ...
随机推荐
- Java学习day5
API即应用程序编程接口,Java所包含的方法以及类很多,如果要使用他们就得了解这些的API如何使用,因为API多而复杂,我们可以通过帮助文档查询 与c/c++类似,Java通过Scanner类就可以 ...
- 将mysql主从复制由ABB模式修改为ABC模式
最近遇到一个奇葩的需求,需要将mysql的主从复制模式由ABB修改为ABC,恰好这个mysql集群没有开启GTID,当时是在B上做了一次全量备份,然后使用该全量备份恢复C的方式进行的.做完之后在想有没 ...
- nodejs的TCP相关的一些笔记
TCP协议 基于nodejs创建TCP服务端 TCP服务的事件 TCP报文解析与粘包解决方案 一.TCP协议 1.1TCP协议原理部分参考:无连接运输的UDP.可靠数据传输原理.面向连接运输的TCP ...
- what 的页面制作
1. html结构 <!-- section: what we do --> <section id="what" class="bg-light py ...
- 集合——Collection接口,List接口
集合:对象的容器,定义了对多个对象进行操作的常用方法.可实现数组的功能 集合和数组的区别: 数组长度固定,集合长度不固定 数组可以存储基本数据类型和引用数据类型,集合只能存储引用数据类型. 集合的位置 ...
- JS获取Cookie失败
项目开发日记-bug多多篇(1) 在做评论功能的时候遇到了一个很无厘头的错误,我的思路是参照点赞功能,用Ajax技术异步完成评论信息的传输,然后展示在页面上. 那么在提交评论信息的同时,要连着用户名, ...
- netty系列之:netty中的核心编码器bytes数组
目录 简介 byte是什么 netty中的byte数组的工具类 netty中byte的编码器 总结 简介 我们知道netty中数据传输的核心是ByteBuf,ByteBuf提供了多种数据读写的方法,包 ...
- 团队Beta2
队名:观光队 链接 组长博客 作业博客 组员实践情况 王耀鑫 **过去两天完成了哪些任务 ** 文字/口头描述 学习 展示GitHub当日代码/文档签入记录 接下来的计划 完成短租车,页面美化 **还 ...
- height不确定时,如何使用动画效果展开高度
要点: 当元素 height 不确定时,可以使用 max-height 设置动画效果 a[href="foldBox"] 用于打开 #foldBox(利用伪元素 :target) ...
- Docker的基本原理及使用
Docker 安装 https://docs.docker.com/engine/install/ubuntu/ 应用场景 Web 应用的自动化打包和发布. 自动化测试和持续集成.发布. 在服务型环境 ...