论文解读(BGRL)《Bootstrapped Representation Learning on Graphs》
论文信息
论文标题:Bootstrapped Representation Learning on Graphs
论文作者:Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Rémi Munos, Petar Veličković, Michal Valko
论文来源:2021, ArXiv
论文地址:download
论文代码:download
1 介绍
研究目的:对比学习中不适用负样本。
本文贡献:
- 对图比学习不使用负样本
2 方法
2.1 整体框架(节点级对比)
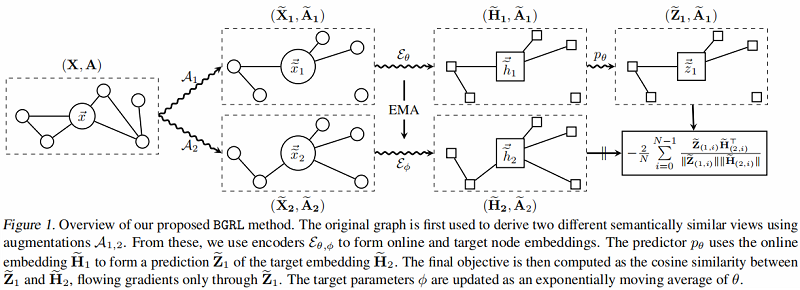
上面是 online network,下面是 target network 。
步骤:
- 步骤一:分别应用随机图增强函数 $\mathcal{A}_{1}$ 和 $\mathcal{A}_{2}$,产生 $G$ 的两个视图:$\mathbf{G}_{1}= \left(\widetilde{\mathbf{X}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$ 和 $\mathbf{G}_{2}=\left(\widetilde{\mathbf{X}}_{2}, \widetilde{\mathbf{A}}_{2}\right) $;
- 步骤二:在线编码器从其增广图中生成一个在线表示 $\widetilde{\mathbf{H}}_{1}:=\mathcal{E}_{\theta}\left(\widetilde{\mathbf{X}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$;目标编码器从其增广图生成目标表示 $\widetilde{\mathbf{H}}_{2}:=\mathcal{E}_{\phi}\left(\widetilde{\mathbf{X}}_{2}, \widetilde{\mathbf{A}}_{2}\right) $;
- 步骤三:在线表示被输入到一个预测器 $p_{\theta}$ 中,该预测器 $p_{\theta}$ 输出对目标表示的预测 $\widetilde{\mathbf{Z}}_{1}:= p_{\theta}\left(\widetilde{\mathbf{H}}_{1}, \widetilde{\mathbf{A}}_{1}\right)$,除非另有说明,预测器在节点级别工作,不考虑图信息(仅在 $\widetilde{\mathbf{H}}_{1}$ 上操作,而不是 $\widetilde{\mathbf{A}}_{1}$)。
2.2 BGRL更新步骤
更新 $\theta$
在线参数 $\theta$(而不是 $\phi$),通过余弦相似度的梯度,使预测的目标表示 $\mathbf{Z}_{1}$ 更接近每个节点的真实目标表示 $\widetilde{\mathbf{H}}_{2}$。
$\ell(\theta, \phi)=-\frac{2}{N} \sum\limits _{i=0}^{N-1} {\large \frac{\widetilde{\mathbf{Z}}_{(1, i)} \widetilde{\mathbf{H}}_{(2, i)}^{\top}}{\left\|\widetilde{\mathbf{Z}}_{(1, i)}\right\|\left\|\widetilde{\mathbf{H}}_{(2, i)}\right\|}} \quad\quad\quad(1)$
$\theta$ 的更新公式:
$\theta \leftarrow \operatorname{optimize}\left(\theta, \eta, \partial_{\theta} \ell(\theta, \phi)\right)\quad\quad\quad(2)$
其中 $ \eta $ 是学习速率,最终更新仅从目标对 $\theta$ 的梯度计算,使用优化方法如 SGD 或 Adam 等方法。在实践中,
我们对称了训练,也通过使用第二个视图的在线表示来预测第一个视图的目标表示。
更新 $\phi$
目标参数 $\phi$ 被更新为在线参数 $\theta$ 的指数移动平均数,即:
$\phi \leftarrow \tau \phi+(1-\tau) \theta\quad\quad\quad(3)$
其中 $\tau$ 是控制 $\phi$ 与 $ \theta$ 的距离的衰减速率。
只有在线参数被更新用来减少这种损失,而目标参数遵循不同的目标函数。根据经验,与BYOL类似,BGRL不会崩溃为平凡解,而 $\ell(\theta, \phi)$ 也不收敛于 $0$ 。
2.3. 完全非对比目标
对比学习常用的负样本带来的问题是:
- 如何定义负样本
- 随着负样本数量增多,带来的内存瓶颈;
本文损失函数定义的好处:
- 不需要对比负对 $\{(i, j) \mid i \neq j\} $ ;
- 计算方便,只需要保证余弦相似度大就行;
2.4.图增强函数
本文采用以下两种数据增强方法:
- 节点特征掩蔽(node feature masking)
- 边缘掩蔽(edge masking)
3 实验
数据集
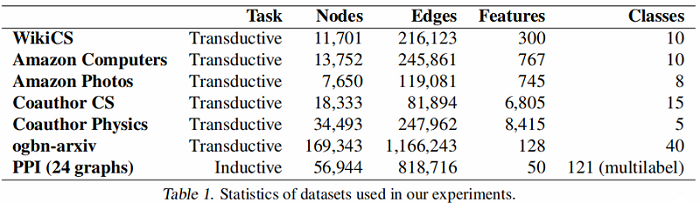
数据集划分:
- WikiCS: 20 canonical train/valid/test splits
- Amazon Computers, Amazon Photos——train/validation/test—10/10/80%
- Coauthor CS, Coauthor Physics——train/validation/test—10/10/80%
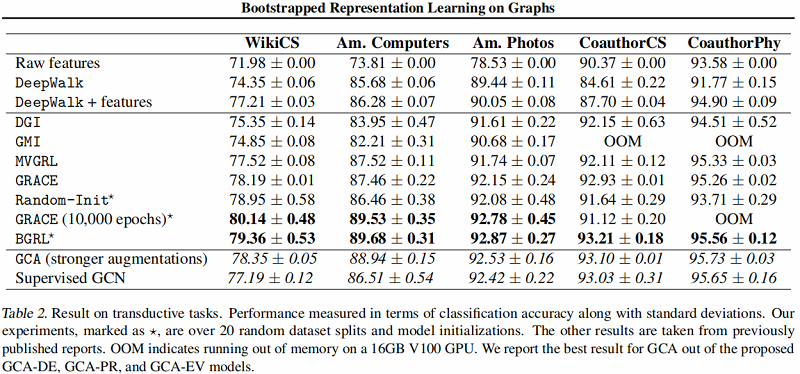
直推式学习——基线实验
图编码器采用 $\text{GCN$ Encoder 。
大图上的直推式学习——基线实验
结果:

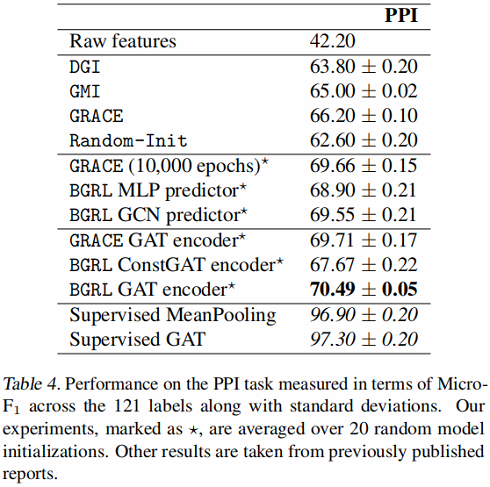
归纳式学习——基线实验
编码器采用 GraphSAGE-GCN (平均池化)和 GAT 。
结果:
4 结论
介绍了一种新的自监督图表示学习方法BGRL。通过广泛的实验,我们已经证明了我们的方法与最先进的方法具有竞争力,尽管不需要负例,并且由于不依赖于投影网络或二次节点比较而大大降低了存储需求。此外,我们的方法可以自然地扩展到学习图级嵌入,其中定义消极的例子是具有挑战性的,并且所有的目标不具有规模。
论文解读(BGRL)《Bootstrapped Representation Learning on Graphs》的更多相关文章
- 论文解读(MVGRL)Contrastive Multi-View Representation Learning on Graphs
Paper Information 论文标题:Contrastive Multi-View Representation Learning on Graphs论文作者:Kaveh Hassani .A ...
- 论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》
论文信息 论文标题:Representation Learning on Graphs with Jumping Knowledge Networks论文作者:Keyulu Xu, Chengtao ...
- 论文阅读 Dynamic Graph Representation Learning Via Self-Attention Networks
4 Dynamic Graph Representation Learning Via Self-Attention Networks link:https://arxiv.org/abs/1812. ...
- 论文解读《Deep Resdual Learning for Image Recognition》
总的来说这篇论文提出了ResNet架构,让训练非常深的神经网络(NN)成为了可能. 什么是残差? "残差在数理统计中是指实际观察值与估计值(拟合值)之间的差."如果回归模型正确的话 ...
- 论文解读( N2N)《Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximization》
论文信息 论文标题:Node Representation Learning in Graph via Node-to-Neighbourhood Mutual Information Maximiz ...
- 论文解读(GRCCA)《 Graph Representation Learning via Contrasting Cluster Assignments》
论文信息 论文标题:Graph Representation Learning via Contrasting Cluster Assignments论文作者:Chun-Yang Zhang, Hon ...
- 论文阅读 Inductive Representation Learning on Temporal Graphs
12 Inductive Representation Learning on Temporal Graphs link:https://arxiv.org/abs/2002.07962 本文提出了时 ...
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
- 论文解读(AutoSSL)《Automated Self-Supervised Learning for Graphs》
论文信息 论文标题:Automated Self-Supervised Learning for Graphs论文作者:Wei Jin, Xiaorui Liu, Xiangyu Zhao, Yao ...
随机推荐
- 一个故事看懂CPU的SIMD技术
好久不见,我叫阿Q,是CPU一号车间的员工.我所在的CPU有8个车间,也就是8个核心,咱们每个核心都可以同时执行两个线程,就是8核16线程,那速度杠杠滴. 我所在的一号车间,除了负责执行指令的我,还有 ...
- Pyinstaller打包Pytorch框架所遇到的问题
目录 前言 基本流程 一.安装Pyinstaller 和 测试Hello World 二.打包整个项目,在本机上调试生成exe 三.在新电脑上测试 参考资料 前言 第一次尝试用Pyinstalle ...
- Python库国内镜像
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ http://pypi.mirrors.ustc.edu.cn/simple/ 豆瓣 http://py ...
- 【深度学习 01】线性回归+PyTorch实现
1. 线性回归 1.1 线性模型 当输入包含d个特征,预测结果表示为: 记x为样本的特征向量,w为权重向量,上式可表示为: 对于含有n个样本的数据集,可用X来表示n个样本的特征集合,其中行代表样本,列 ...
- 半吊子菜鸟学Web开发 -- PHP学习2-正则,cookie和session
1正则表达式 1.1基本的匹配字符串 $p = '/apple/'; $str = "apple banna"; if (preg_match($p, $str)) { echo ...
- Snort中pcre和正则表达式的使用
Snort中pcre和正则表达式的使用 1. 题目描述 If snort see two packets in a TCP flow with first packet has "login ...
- 创建一个简单的Eureka注册中心
微服务和分布式已经成了一种极其普遍的技术,为了跟上时代的步伐,最近开始着手学习SpringCloud,就从Eureka开始.他们俩就不做介绍了,网上的说明一堆,随便打开一个搜索引擎输入关键字都足够了解 ...
- Java IO流处理
字节流是由字节组成的;字符流是由字符组成的Java里字符由两个字节组成. 1字符=2字节JAVA中的字节流是采用ASCII编码的,字符流是采用好似UTF编码,支持中文的 Java IO流处理 面试题汇 ...
- python 模块和包的基础知识
1.常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀 2.为了方便管理,我们通常将程序分成一个个的文件,这样做程序的结构更清晰,方便管理.这时我们不仅 ...
- 说说&和&&的区别?
&和&&都可以用作逻辑与的运算符,表示逻辑与(and),当运算符两边的表达式的结果都为true时,整个运算结果才为true,否则,只要有一方为false,则结果为false.