B+树索引页大小是如何确定的?
B+树简介
在正式介绍本文的主题前,需要对 B+ 树有一定的了解,B+树是一种磁盘上数据的索引结构,大概长这个样子。
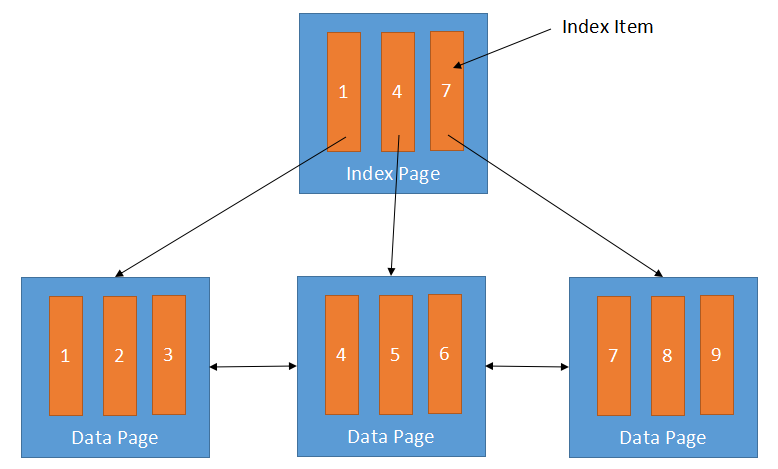
B+树的叶子节点是所有的数据,非叶子节点称为索引页,索引页里有若干个索引项,本例中有 3 个索引项,也就是索引页的出度为 3,表示它有 3 个子节点。
相要寻找某一个数据时,比如值为 6 的数据,只需要先在索引页中找到小于 6 的最大的索引项 4,就可以索引到保存了 4,5,6 三条数据的数据页,进而找到值为 6 的这一条数据。
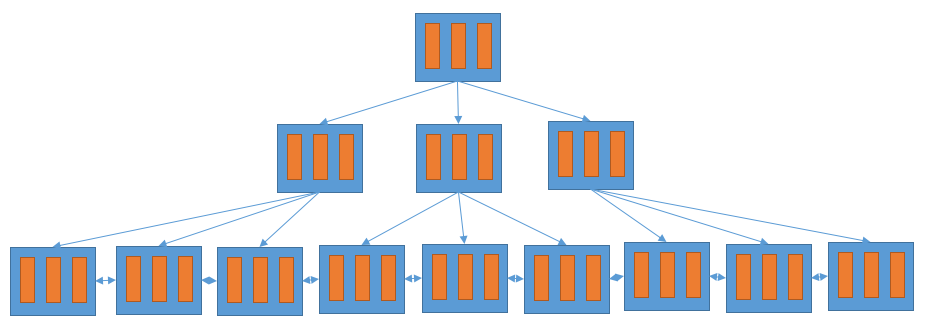
当然,B+ 树不是只有一个索引节点,只是为了方便展示所以图中只有一个索引节点,一个更大的 B+ 树如下图所示。
数学推导
假设 B+ 树总共索引了 N 条数据(叶子节点的数据量),每个索引页的出度为 EntriesPerPage(索引页内有多少个索引项),则 B+ 树的高度可以由如下式子计算:
\]
定义 IndexPageUtility 为衡量索引页到数据页的远近的指标,可以由如下式子计算:
\]
这里可以不必纠结为什么 utility 就是这么算的,只要理解 utility 和 EntriesPerPage 是正相关的关系就可以,因为最后算的收益成本比率只是一个比值,能比较出大小就可以,所以这里就取 utility 为 IndexHeight 计算公式的分母。
举个例子,如果索引项大小为 20 字节,那么 2KB 的索引页应该是能装下 100 个索引项,但实际上索引页内不仅仅只存有索引项,实际索引项最高能占用 70% 的空间,也就是 70 个索引项。这样的索引页的 utility 为 \(log_{2}{70}\) 约为 6.2,大约是 128KB 大小索引页 utility 的一半。
每一次读索引页都需要读一次磁盘,相应的距离目标数据也更进一步(使用 utility 衡量步长)。基于这种成本效益的权衡,产生了一个最佳的页面大小,平衡了读一次索引页的收益(IndexPageUtility)和成本(IndexPageAccessCost)。
对于越大的索引页,它的出度越大,utility 越高,从磁盘读取的成本也越高,对于特定的磁盘的寻址时间和传输速率,有一个最优的索引页大小。
假设磁盘平均寻址时间为 10 毫秒,传输速率为 10MB 每秒,索引页大小为 2KB,那么读取索引页需要的时间为 10.2 毫秒。
更准确的说,读取索引页的成本要么是有页面缓存时的内存存储成本,要么是从磁盘读取页面的磁盘访问成本。如果根索引页及附近的索引页缓存在内存中,能够节省一个数量恒定的 IO 次数,这个数量一般是可以忽略的。
因此从磁盘读取索引页的成本可以由如下式子计算,DiskLatency 为磁盘寻址时间。
\]
那么读取索引页的收益和成本的比率就是:
\]
应用分析
假设磁盘平均寻址时间为 10 毫秒,传输速率为 10MB 每秒,索引项大小为 20 字节,下表给出不同索引页大小对应的收益成本比率。
| IndexPageSize(KB) | EntriesPerPage | IndexPageUtility | IndexPageAccessCost | BenefitCostRatio |
|---|---|---|---|---|
| 2 | 68 | 6.1 | 10.2 | 0.60 |
| 4 | 135 | 7.1 | 10.4 | 0.68 |
| 8 | 270 | 8.1 | 10.8 | 0.75 |
| 16 | 541 | 9.1 | 11.6 | 0.78 |
| 32 | 1081 | 10.1 | 13.2 | 0.76 |
| 64 | 2163 | 11.1 | 16.4 | 0.68 |
| 128 | 4325 | 12.1 | 22.8 | 0.53 |
通过上表可以得出,索引页大小在 8KB 到 32KB 是收益成本比率是最优的。索引页过小或过大都不是好的选择。且该索引页大小范围也随着磁盘传输速率的提升而发生变化,当传输速率为 40MB 每秒,最优的索引页大小将变成 32KB 到 128 KB。
B+树索引页大小是如何确定的?的更多相关文章
- MySQL:InnoDB存储引擎的B+树索引算法
很早之前,就从学校的图书馆借了MySQL技术内幕,InnoDB存储引擎这本书,但一直草草阅读,做的笔记也有些凌乱,趁着现在大四了,课程稍微少了一点,整理一下笔记,按照专题写一些,加深一下印象,不枉读了 ...
- MySQL的B树索引与索引优化
MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为"BTREE"),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引 ...
- 搞懂MySQL InnoDB B+树索引
一.InnoDB索引 InnoDB支持以下几种索引: B+树索引 全文索引 哈希索引 本文将着重介绍B+树索引.其他两个全文索引和哈希索引只是做简单介绍一笔带过. 哈希索引是自适应的,也就是说这个不能 ...
- MySQL之B+树索引(转自掘金小册 MySQL是怎样运行的,版权归作者所有!)
每个索引都对应一棵B+树,B+树分为好多层,最下边一层是叶子节点,其余的是内节点.所有用户记录都存储在B+树的叶子节点,所有目录项记录都存储在内节点. InnoDB存储引擎会自动为主键(如果没有它会自 ...
- [MySQL] 索引中的b树索引
1.索引如果没有特别指明类型,一般是说b树索引,b树索引使用b树数据结构存储数据,实际上很多存储引擎使用的是b+树,每一个叶子节点都包含指向下一个叶子节点的指针,从而方便叶子节点的范围遍历 2.底层的 ...
- InnoDB存储引擎的 B+ 树索引
B+ 树是为磁盘设计的 m 叉平衡查找树,在B+树中,所有的记录都是按照键值的大小,顺序存放在同一层的叶子节点上,各叶子节点组成双链表.叶节点是数据,非叶节点是索引. 首先,需要清楚:B+ 树索引并不 ...
- InnoDB存储引擎的B+树索引算法
关于B+树数据结构 ①InnoDB存储引擎支持两种常见的索引. 一种是B+树,一种是哈希. B+树中的B代表的意思不是二叉(binary),而是平衡(balance),因为B+树最早是从平衡二叉树演化 ...
- MySQL中B+树索引的使用
1) 不同应用中B+树索引的使用 对于OLTP应用,由于数据量获取可能是其中一小部分,建立B+树索引是有异议时的 对OLAP应用,情况比较复杂,因为索引的添加应该是宏观的而不是微观的. ...
- B树索引与索引优化
B树索引与索引优化 MySQL的MyISAM.InnoDB引擎默认均使用B+树索引(查询时都显示为“BTREE”),本文讨论两个问题: 为什么MySQL等主流数据库选择B+树的索引结构? 如何基于索引 ...
随机推荐
- Svelte3.x网页聊天实例|svelte.js仿微信PC版聊天svelte-webchat
基于Svelte3+SvelteKit+Sass仿微信Mac界面聊天实战项目SvelteWebChat. 基于svelte3+svelteKit+sass+mescroll.js+svelte-lay ...
- 好客租房8-React基础阶段总结
React总结 1react是构建用户组件的javascript库 2使用react是,推荐使用脚手架方式 3初始化项目命令:npx create-react-app my-app 4启动项目命令:y ...
- Meaven静态资源过滤
` 点击查看代码 <build> <resources> <resource> <directory>src/main/java</directo ...
- 第06组 Beta冲刺 (1/6)
目录 1.1 基本情况 1.2 冲刺概况汇报 1.郝雷明 2. 方梓涵 3.曾丽莉 4.黄少丹 5. 董翔云 6.杜筱 7.鲍凌函 8.詹鑫冰 9.曹兰英 10.吴沅静 1.3 冲刺成果展示 1.1 ...
- 聊聊C#中的Mixin
写在前面 Mixin本意是指冰淇淋表面加的那些草莓酱,葡萄干等点缀物,它们负责给冰淇淋添加风味.在OOP里面也有Mixin这个概念,和它的本意相似,OOP里面的Mixin意在为类提供一些额外功能--在 ...
- Linux系列之linux访问windows文件
Linux永久挂载windows共享文件 Linux系统必须安装samba-client Linux服务器必须能访问到Windows的共享文件服务的(445端口) 1.Windows共享文件 2.测试 ...
- SQL Server各版本序列号/激活码/License/秘钥
SQL Server 2019 Enterprise:HMWJ3-KY3J2-NMVD7-KG4JR-X2G8G Enterprise Core:2C9JR-K3RNG-QD4M4-JQ2HR-846 ...
- kafka优劣
kafka优势 可扩展:Kafka集群可以透明的扩展,增加新的服务器进集群. 高性能:Kafka性能远超过传统的ActiveMQ.RabbitMQ等,Kafka支持Batch操作. 容错性:Kafka ...
- Markdown常见基本语法
标题 -方式一:使用警号 几个警号就是几级标题,eg: # 一级标题 -方式二: 使用快捷键 ctrl+数字 几级标题就选其对应的数字, eg: ctrl+2(二级标题) 子标题 -方式一: 使用星号 ...
- SAP FICO 常用table
Table 描 述 "Table Type" "Application Class" "Data Class" Description &q ...