ArrayDeque(JDK双端队列)源码深度剖析
ArrayDeque(JDK双端队列)源码深度剖析
前言
在本篇文章当中主要跟大家介绍JDK给我们提供的一种用数组实现的双端队列,在之前的文章LinkedList源码剖析当中我们已经介绍了一种双端队列,不过与ArrayDeque不同的是,LinkedList的双端队列使用双向链表实现的。
双端队列整体分析
我们通常所谈论到的队列都是一端进一端出,而双端队列的两端则都是可进可出。下面是双端队列的几个操作:
数据从双端队列左侧进入。

数据从双端队列右侧进入。

- 数据从双端队列左侧弹出。

- 数据从双端队列右侧弹出。

而在ArrayDeque当中也给我们提供了对应的方法去实现,比如下面这个例子就是上图对应的代码操作:
public void test() {
ArrayDeque<Integer> deque = new ArrayDeque<>();
deque.addLast(100);
System.out.println(deque);
deque.addFirst(55);
System.out.println(deque);
deque.addLast(-55);
System.out.println(deque);
deque.removeFirst();
System.out.println(deque);
deque.removeLast();
System.out.println(deque);
}
// 输出结果
[100]
[55, 100]
[55, 100, -55]
[100, -55]
[100]
数组实现ArrayDeque(双端队列)的原理
ArrayDeque底层是使用数组实现的,而且数组的长度必须是2的整数次幂,这么操作的原因是为了后面位运算好操作。在ArrayDeque当中有两个整形变量head和tail,分别指向右侧的第一个进入队列的数据和左侧第一个进行队列的数据,整个内存布局如下图所示:

其中tail指的位置没有数据,head指的位置存在数据。
- 当我们需要从左往右增加数据时(入队),内存当中数据变化情况如下:

- 当我们需要从右往做左增加数据时(入队),内存当中数据变化情况如下:

- 当我们需要从右往左删除数据时(出队),内存当中数据变化情况如下:

- 当我们需要从左往右删除数据时(出队),内存当中数据变化情况如下:

底层数据遍历顺序和逻辑顺序
上面主要谈论到的数组在内存当中的布局,但是他是具体的物理存储数据的顺序,这个顺序和我们的逻辑上的顺序是不一样的,根据上面的插入顺序,我们可以画出下面的图,大家可以仔细分析一下这个图的顺序问题。

上图当中队列左侧的如队顺序是0, 1, 2, 3,右侧入队的顺序为15, 14, 13, 12, 11, 10, 9, 8,因此在逻辑上我们的队列当中的数据布局如下图所示:

根据前面一小节谈到的输入在入队的时候数组当中数据的变化我们可以知道,数据在数组当中的布局为:

ArrayDeque类关键字段分析
// 底层用于存储具体数据的数组
transient Object[] elements;
// 这就是前面谈到的 head
transient int head;
// 与上文谈到的 tail 含义一样
transient int tail;
// MIN_INITIAL_CAPACITY 表示数组 elements 的最短长度
private static final int MIN_INITIAL_CAPACITY = 8;
以上就是ArrayDeque当中的最主要的字段,其含义还是比较容易理解的!
ArrayDeque构造函数分析
- 默认构造函数,数组默认申请的长度为
16。
public ArrayDeque() {
elements = new Object[16];
}
- 指定数组长度的初始化长度,下面列出了改构造函数涉及的所有函数。
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 elements
}
return initialCapacity;
}
上面的最难理解的就是函数calculateSize了,他的主要作用是如果用户输入的长度小于MIN_INITIAL_CAPACITY时,返回MIN_INITIAL_CAPACITY。否则返回比initialCapacity大的第一个是2的整数幂的整数,比如说如果输入的是9返回的16,输入4返回8。
calculateSize的代码还是很难理解的,让我们一点一点的来分析。首先我们使用一个2的整数次幂的数进行上面移位操作的操作!


从上图当中我们会发现,我们在一个数的二进制数的32位放一个1,经过移位之后最终32位的比特数字全部变成了1。根据上面数字变化的规律我们可以发现,任何一个比特经过上面移位的变化,这个比特后面的31个比特位都会变成1,像下图那样:

因此上述的移位操作的结果只取决于最高一位的比特值为1,移位操作后它后面的所有比特位的值全为1,而在上面函数的最后,我们返回的结果就是上面移位之后的结果 +1。又因为移位之后最高位的1到最低位的1之间的比特值全为1,当我们+1之后他会不断的进位,最终只有一个比特位置是1,因此它是2的整数倍。

经过上述过程分析,我们就可以立即函数calculateSize了。
ArrayDeque关键函数分析
addLast函数分析
// tail 的初始值为 0
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
// 这里进行的 & 位运算 相当于取余数操作
// (tail + 1) & (elements.length - 1) == (tail + 1) % elements.length
// 这个操作主要是用于判断数组是否满了,如果满了则需要扩容
// 同时这个操作将 tail + 1,即 tail = tail + 1
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
代码(tail + 1) & (elements.length - 1) == (tail + 1) % elements.length成立的原因是任意一个数\(a\)对\(2^n\)进行取余数操作和\(a\)跟\(2^n - 1\)进行&运算的结果相等,即:
\]
从上面的代码来看下标为tail的位置是没有数据的,是一个空位置。
addFirst函数分析
// head 的初始值为 0
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
// 若此时数组长度elements.length = 16
// 那么下面代码执行过后 head = 15
// 下面代码的操作结果和下面两行代码含义一致
// elements[(head - 1 + elements.length) % elements.length] = e
// head = (head - 1 + elements.length) % elements.length
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
上面代码操作结果和上文当中我们提到的,在队列当中从右向左加入数据一样。从上面的代码看,我们可以发现下标为head的位置是存在数据的。
doubleCapacity函数分析
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
// arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length)
// 上面是函数 System.arraycopy 的函数参数列表
// 大家可以参考上面理解下面的拷贝代码
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
上面的代码还是比较简单的,这里给大家一个图示,大家就更加容易理解了:
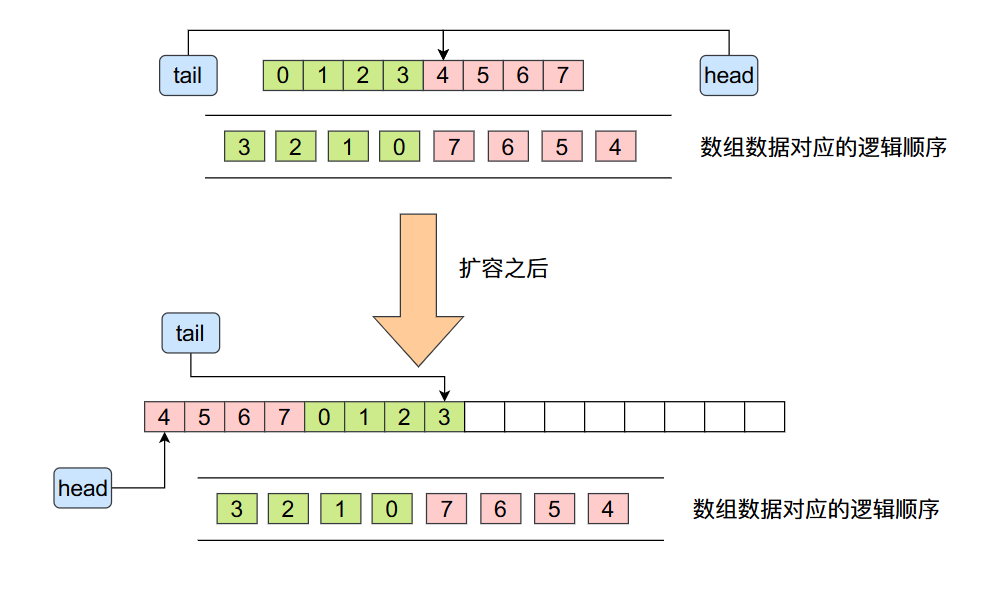
扩容之后将原来数组的数据拷贝到了新数组当中,虽然数据在旧数组和新数组当中的顺序发生变化了,但是他们的相对顺序却没有发生变化,他们的逻辑顺序也是一样的,这里的逻辑可能有点绕,大家在这里可以好好思考一下。
pollLast和pollFirst函数分析
这两个函数的代码就比较简单了,大家可以根据前文所谈到的内容和图示去理解下面的代码。
public E pollLast() {
// 计算出待删除的数据的下标
int t = (tail - 1) & (elements.length - 1);
@SuppressWarnings("unchecked")
E result = (E) elements[t];
if (result == null)
return null;
// 将需要删除的数据的下标值设置为 null 这样这块内存就
// 可以被回收了
elements[t] = null;
tail = t;
return result;
}
public E pollFirst() {
int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result == null)
return null;
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
return result;
}
总结
在本篇文章当中,主要跟大家分享了ArrayDeque的设计原理,和他的底层实现过程。ArrayDeque底层数组当中的数据顺序和队列的逻辑顺序这部分可能比较抽象,大家可以根据图示好好体会一下!!!
以上就是本篇文章的所有内容了,希望大家有所收获,我是LeHung,我们下期再见!!!都看到这里了,给孩子一个赞(start)吧, 免费的哦!!!
免费的哦!!!
更多精彩内容合集可访问项目:https://github.com/Chang-LeHung/CSCore
关注公众号:一无是处的研究僧,了解更多计算机(Java、Python、计算机系统基础、算法与数据结构)知识。
ArrayDeque(JDK双端队列)源码深度剖析的更多相关文章
- JDK数组阻塞队列源码深入剖析
JDK数组阻塞队列源码深入剖析 前言 在前面一篇文章从零开始自己动手写阻塞队列当中我们仔细介绍了阻塞队列提供给我们的功能,以及他的实现原理,并且基于谈到的内容我们自己实现了一个低配版的数组阻塞队列.在 ...
- FutureTask源码深度剖析
FutureTask源码深度剖析 前言 在前面的文章自己动手写FutureTask当中我们已经仔细分析了FutureTask给我们提供的功能,并且深入分析了我们该如何实现它的功能,并且给出了使用Ree ...
- libevent源码深度剖析十二
libevent源码深度剖析十二 ——让libevent支持多线程 张亮 Libevent本身不是多线程安全的,在多核的时代,如何能充分利用CPU的能力呢,这一节来说说如何在多线程环境中使用libev ...
- libevent源码深度剖析四
libevent源码深度剖析四 ——libevent源代码文件组织 1 前言 详细分析源代码之前,如果能对其代码文件的基本结构有个大概的认识和分类,对于代码的分析将是大有裨益的.本节内容不多,我想并不 ...
- Axios源码深度剖析
Axios源码深度剖析 - XHR篇 axios 是一个基于 Promise 的http请求库,可以用在浏览器和node.js中,目前在github上有 42K 的star数 分析axios - 目录 ...
- HashMap源码深度剖析,手把手带你分析每一行代码,包会!!!
HashMap源码深度剖析,手把手带你分析每一行代码! 在前面的两篇文章哈希表的原理和200行代码带你写自己的HashMap(如果你阅读这篇文章感觉有点困难,可以先阅读这两篇文章)当中我们仔细谈到了哈 ...
- libevent 源码深度剖析十三
libevent 源码深度剖析十三 —— libevent 信号处理注意点 前面讲到了 libevent 实现多线程的方法,然而在多线程的环境中注册信号事件,还是有一些情况需要小心处理,那就是不能在多 ...
- libevent源码深度剖析十一
libevent源码深度剖析十一 ——时间管理 张亮 为了支持定时器,Libevent必须和系统时间打交道,这一部分的内容也比较简单,主要涉及到时间的加减辅助函数.时间缓存.时间校正和定时器堆的时间值 ...
- libevent源码深度剖析十
libevent源码深度剖析十 ——支持I/O多路复用技术 张亮 Libevent的核心是事件驱动.同步非阻塞,为了达到这一目标,必须采用系统提供的I/O多路复用技术,而这些在Windows.Linu ...
随机推荐
- XCTF练习题---MISC---intoU
XCTF练习题---MISC---intoU flag:RCTF{bmp_file_in_wav} 解题步骤: 1.观察题目,下载附件 2.解压以后是一个音频文件,听一听,挺嗨的,一边听一边想到音频分 ...
- vue - vue基础/vue核心内容(终结篇)
今天是vue基础.vue核心内容第三天,也是最后一天,后面开始进入组件化学习,整个基础内容以生命周期的结束而结束,不得不说,张天禹把这节课讲活了,开始觉得vue是一个有生命的东西,包括前面所说的很多脏 ...
- 对象、Map、Set、WeakMap、WeakSet
对象.Map.Set.WeakMap.WeakSet 本文写于 2020 年 11 月 24 日 总的来说,Set 和 Map 主要的应用场景分别在于数据重组和数据储存.Set 是一种叫做「集合」的数 ...
- grafana展示zabbix统计
1.安装grafana 参照官网文档:https://grafana.com/grafana/download 我这边是centos系统,执行这两个命令 wget https://dl.grafa ...
- mysql 主从数据同步配置
一主一从,单向同步 master 数据库的数据变更单向同步到 slave 数据库 互为主从,双向同步 master 数据库的数据变更同步到 slave 数据库,slave 数据库的数据边同步到 mas ...
- 【工具-Nginx】从入门安装到高可用集群搭建
文章已收录至https://lichong.work,转载请注明原文链接. ps:欢迎关注公众号"Fun肆编程"或添加我的私人微信交流经验 一.Nginx安装配置及常用命令 1.环 ...
- sublime速查手册
零.sublime的优势 容易上手 支持多点编辑 包管理:Package Control 速度快 深度可订制,配置文件放github上 sublime-config 快速文件切换 cmd + p 输入 ...
- 爬取豆瓣喜剧类热门TOP60的电影
学习任务:爬取豆瓣喜剧类热门TOP60的电影并保存在douban.txt文件中. 代码示例: import requests url="https://movie.douban.com/j/ ...
- drools中的条件 when
目录 1.介绍 2.语法结构 3.模式例子 3.1 单个对象匹配 3.2 匹配任何对象 3.3 带条件匹配 3.3.1 注意事项 3.4 嵌套属性的匹配 3.4.1 访问单个嵌套属性 3.4.2 访问 ...
- Navicat可视化MySQL数据库
Navicat可视化MySQL数据库 Navicat内部封装了所有的操作数据库的命令,用户只需要点击操作即可,无需书写sql语句. navicat能够充当多个数据库的客户端. 具体操作参考百度. py ...