从零开始山寨Caffe·捌:IO系统(二)
生产者
双缓冲组与信号量机制
在第陆章中提到了,如何模拟,以及取代根本不存的Q.full()函数。
其本质是:除了为生产者提供一个成品缓冲队列,还提供一个零件缓冲队列。
当我们从外部给定了固定容量的零件之后,生产者的产能就受到了限制。
由两个阻塞队列组成的QueuePair,并不是Caffe的独创,它实际上是生产者与消费者的编程方式之一。
在大部分操作系统教材中,双缓冲区free、full通常由两个信号量empty、full实现。
信号量(Semaphore)由操作系统底层实现,并且几乎没有人会直接使用信号量去编程。
因为在逻辑上,可以由信号量可由mutex+计数器模拟得到。
信号量的名字很有趣,它实际上由两部分组成,信号(激活信号)、量(计数器)。
汉语的博大精深恰当地诠释的信号量的语义精神,而从Semaphore中,你读不出任何精华。
激活信号掩盖了mutex的功与名,信号量的第一大功能,就是mutex锁。
量,显然表明信号量可以计数,实际上,信号量经常会被拿来为临界资源计数。
下面的伪代码摘自我的操作系统课本,《计算机操作系统 <第四版> 汤小丹等 著》:
int in=,out=;
item buffer[n];
semaphore mutex=,empty=n,full=;
void wait(S){
while(S<=);
S--;
}
void signal(S) {S++;}
void producer{
while(){
produce an item in nexp;
...
wait(empty);
wait(mutex);
buffer[in]=nexp;
in=(in+)%n;
signal(mutex);
signal(full);
}
}
可以看到,除了mutex履行其互斥锁的职责之外,empty和full用来计数。
作为生产者,每次生产时,都要让empty减1,让full加1。
当empty小于等于零时,形成第二把锁,当然,这把锁不是为了互斥,只是为了阻塞。
为了增加效率,这第二把锁可以修改成条件阻塞,让生产者交出CPU控制权,当然这需要操作系统的支持。
信号量在现代编程中是多余的,事实上,也没有哪个线程库会提供。
当"量"为1时,信号量通常是去实现互斥锁功能。
当"量"为临界资源数量时,信号量通常是去实现资源计数、并且条件阻塞的功能。
这两部分的精神内涵都在Blocking Queue中实现了,So,忘记信号量吧。
多生产者单缓冲区
作为一般的机器学习玩家,你是用不着考虑多生产者的。
如果你比较有钱,经常喜欢摆弄4-way泰坦交火,那么就需要考虑一下多生产者的模型了。
在第肆章中,介绍了多GPU的基本运行原理,给出了如下这张图:

对于每个GPU而言,它至少需要一个对它负责的DataReader,每个DataRedaer应当有不同的数据来源。
Caffe中,将控制一个数据来源的类对象称为Body,默认有一个类静态成员的Body关联容器:
class DataReader
{
public:
.....
private:
static map<string, boost::weak_ptr<Body> > global_bodies;
};
值得注意的是,此处应该使用weak_ptr,而不是shared_ptr,因为Body本身将由一个shared_ptr控制。
将Body的shared_ptr存入map容器,将会导致指针计数器永远为1。
这样,当我们准备将Body从map容器中清除时,无法获知它是否已经被释放。
而weak_ptr指向shared_ptr时,不会增加指针计数器计数,当计数为0时,即可将其从map里清除。
每一个DataReader只能拥有一个Body,而每个Body可以有多个成品存储缓冲区(非用于零件缓冲,下节讲)。
每个Body控制一个数据来源,不同的数据来源可以用关键字来hash,默认Caffe提供的关键字是:
static string source_key(const LayerParameter& param){
return param.name() + ":" + param.data_param().source();
}
即Layer名,加上数据库路径。
多生产者主要用于多数据库同时并行训练,这是一种非常经典的模型。
一部分代码涉及到上层的DataLayer,将后续详解。
另外一种模型是单生产者,以单数据库,不同数据区域同时并行训练,该方法也可以采用。(下节讲)
Caffe的默认源码中,既没有完整实现多生产者并行模型,也没有完整实现单生产者并行模型,这点令人遗憾。
不过,从源码中仍然可以看出一点端倪,本教程只介绍大体思路,同样并不提供具体代码。
单生产者多缓冲区
在这种模型下,将只有一个DataReader,一个Body,但是有多个Pair,如图:
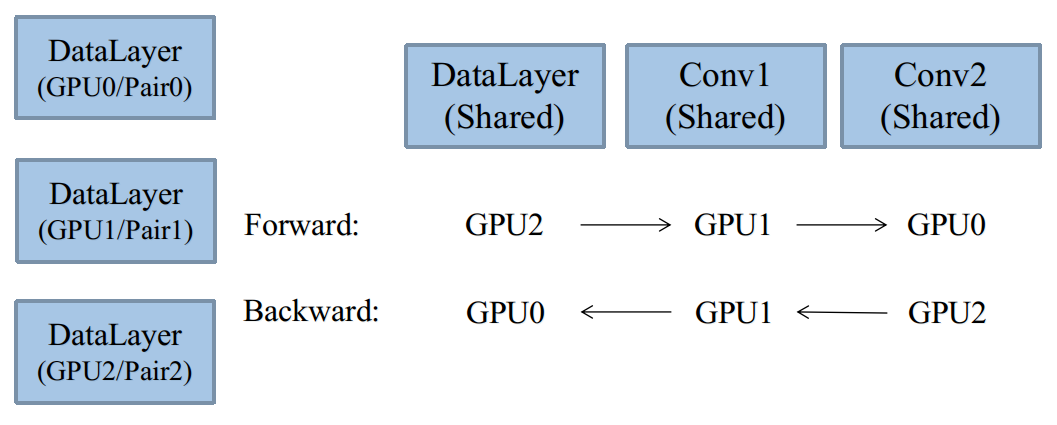
有趣的是,Body结构体中,提供了QueuePair数组容器:
class Body :public DragonThread{
public:
.......
BlockingQueue<boost::shared_ptr<QueuePair> > new_pairs;
};
但是,Caffe源码中的DataReader,默认只会使用该容器数组的第一个QueuePair,并没有完整实现多缓冲区:
class DataReader
{
public:
DataReader(const LayerParameter& param){
........
ptr_body->new_pairs.push(ptr_pair);
}
BlockingQueue<Datum*>& free() const { return ptr_pair->free; }
BlockingQueue<Datum*>& full() const { return ptr_pair->full; }
private:
boost::shared_ptr<QueuePair> ptr_pair;
boost::shared_ptr<Body> ptr_body;
};
可以看到,尽管我们设置了Body,存储多个QueuePair,但是提供的外部访问接口,居然直接使用了ptr_pair。
当然,如果你要编程使用多缓冲区,一定要修改DataReader的访问接口。
对于单个数据库的顺序数据读取,如何将顺序资源,平摊到多个缓冲区?
Caffe使用了循环读取法:
void Body::interfaceKernel(){
boost::shared_ptr<DB> db(GetDB(param.data_param().backend()));
db->Open(param.data_param().source(), DB::READ);
boost::shared_ptr<Cursor> cursor(db->NewCursor());
vector<boost::shared_ptr<QueuePair> > container;
try{
...............
while (!must_stop()){
for (int i = ; i < solver_count; i++)
read_one(cursor.get(), container[i].get());
}
} catch (boost::thread_interrupted&) {}
}
可以看到,在Body的线程函数中,利用全局管理器提供的solver_count,循环均摊数据到多个QueuePair中。
当你将solver_count设置成大于1时,将可以使用Body中的多个缓冲区QueuePair,这点需要注意。
单生产者单缓冲区(默认代码)
仔细思考一下,就会发现,单生产者多缓冲区方案是毫无意义的,看起来我们似乎模拟了多缓冲区。
但是实质只是一个线程,把资源分了一下组,多个组在DataLayer进行消费的时候,又会被合并成一个Batch:
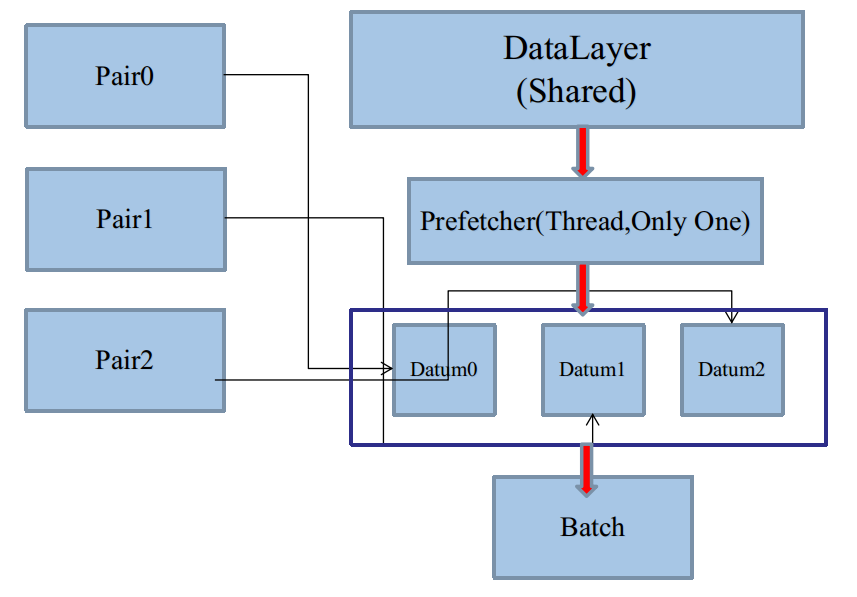
如图,因为一个DataLayer只能有一个Prefetching Thread,所以必然是每次从各个Pair里取一次。
如果我们先把Pair0取完,再取Pair1,再取Pair2,这样也是可以的,是一种不错的shuffle,但是需要追加代码。
从计算角度分析,多缓冲区不会加速,反而会减速,如果是为了做上述的shuffle,是情有可原的。
如果不是,只是单纯地为了负载均衡,轮流从各个Pair里取,那么本质上,就会退化成单生产者单缓冲区。
————————————————————————————————————————————————————
这可能是Caffe源码的本意。在这种方案中,DataReader和DataLayer是无须改动代码的。
只要我们加大DataParameter里的prefech数值,让CPU多缓冲几个Batch,为多个GPU准备就好了。
三种速度方案排名:
多生产者单缓冲区>单生产者单缓冲区>单生产者多缓冲区
线程嵌套线程与Socket
Caffe的源码真的很有启发性,在DataReader的构造和析构函数中,可以发现贡献者悄悄加了mutex:
DataReader::DataReader(const LayerParameter& param){
......
boost::mutex::scoped_lock lock(bodies_mutex);
......
}
DataReader::~DataReader(){
......
boost::mutex::scoped_lock lock(bodies_mutex);
......
}
熟悉C++的人应该知道,在常规情况下,构造和析构函数是不会并行执行的,也就是不会被线程执行。
线程并行的仅仅是工作函数,工作之前主进程构造,工作之后,主进程析构。
如果偏要认为构造和析构可能并行的话,那么将出现一种好玩的情况:
由于DataReader本身是线程,线程并行线程,将导致线程嵌套线程。
在我的操作系统课上,我的老师这么说:
线程仅仅拥有进程的少部分资源,权限很小。
那么线程能够嵌套线程么?经过百度之后,我发现真还可以。
当今的操作系统,无论是Linux,还是Windows,线程的资源权限都是非常大的。
————————————————————————————————————————————————————
线程嵌套线程,会不会和多GPU有关?我认为无关。
每个GPU的监督线程,这里我们假设使用DragonThread,在需要工作时,
只需要传入:Solver::solve函数就可以了,Solver、Net、Layer的构造和析构,显然是在主进程里执行的。
那么,线程嵌套线程,有什么意义,有什么情况是必须在线程里触发构造函数?
很有趣,一般来讲,只有Socket线程是这样的。
Socket线程无须使用DragonThread,实际上,Boost的Socket也是由boost::asio而不是boost::thread实现的。
不像多GPU,我们无法预估,在某一时刻,实际有多少个Socket在执行,有多少个用户发出了访问请求。
因此,不能直接把Solver、Net、Layer的构造,放在主进程当中。不然你知道你要构造多少份嘛?显然你不知道。
所以,从直觉上,将这些的构造,放在每一个启动的Socket线程里,用多少,构造多少,看起来不错,如图:
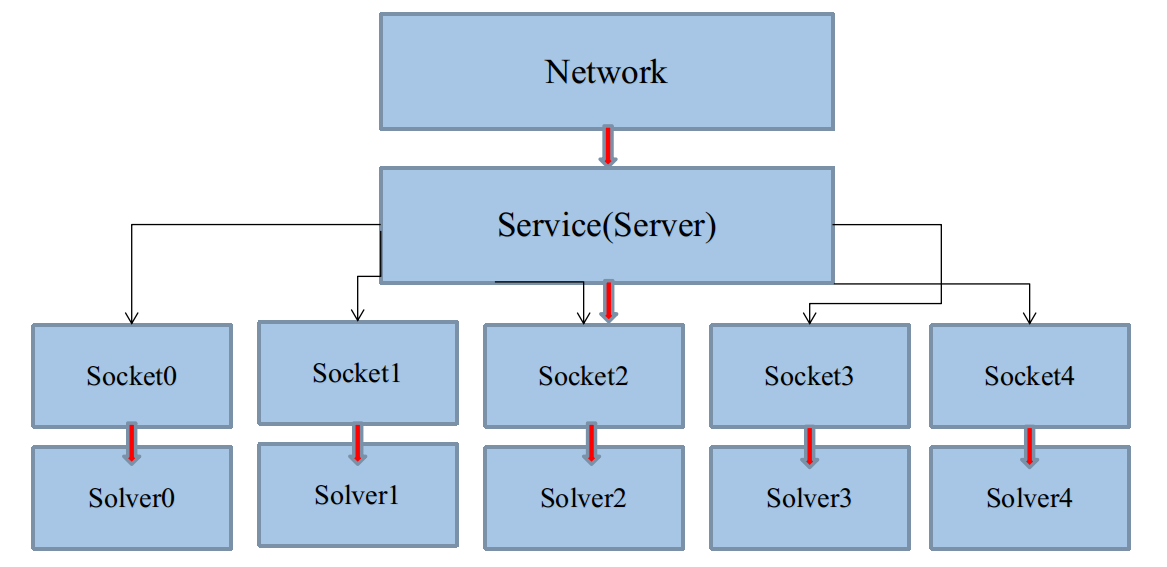
这样,假如这几个Solver使用了不同数据来源,那么global_bodies就有被几个Solver同时修改的可能。
这是构造和析构函数里,需要加mutex的直接原因。
————————————————————————————————————————————————————
Socket的意义何在?
①从训练角度,多个用户可以远程操控一台主机,训练不同的Net。
这点与多GPU训练一个模型是不一样的。一般而言,我们不会认为,多个用户通过Socket,居然想要训练同一个模型。
当然,这也是可以的。
②从测试角度,多个用户,可以利用同一个Net的参数,并行得到自己提供的数据的测试结果。
注意,这样就不要share整个Net,每个用户的solver使用独立的Net,独立读取训练好的参数。
否则,多个用户会在一个Net上卡半天。
代码实战
建立data_reader.hpp、data_reader.cpp。
QueuePair
class QueuePair{
public:
QueuePair(const int size);
~QueuePair();
BlockingQueue<Datum*> free; // as producter queue
BlockingQueue<Datum*> full; // as consumer queue
};
QueuePair的结构在上一章已经介绍过,每一个QueuePair将作为一个缓冲区。
QueuePair只需要实现构造函数和析构函数:
QueuePair::QueuePair(const int size){
// set the upbound for a producter
for (int i = ; i < size; i++) free.push(new Datum());
}
QueuePair::~QueuePair(){
// release and clear
Datum *datum;
while (free.try_pop(&datum)) delete datum;
while (full.try_pop(&datum)) delete datum;
}
在构造函数中,我们进行"零件"的填充,注意里面的Datum全是空元素,且存入队列的应该是指针。
切记勿存入实体对象Datum,这在应用程序开发中是大忌,因为C++并非Python,默认执行的深拷贝。
深拷贝大内存数据结构体,会严重拖慢程序执行,而且还是没有意义的,传递指针更恰当。
在析构函数中,实际上这是唯一一处对Protocol Buffer对象的主动析构,因为Datum没有用shared_ptr。
主动析构主要利用Blocking Queue提供的try,来控制循环进度。
此处切记不要把pop写成peek,否则会造成对空指针的delete,导致程序崩溃。
LayerParameter
DataReader的上层是DataLayer,它是DataLayer的成员变量之一,需要DataLayer提供proto参数。
在你的proto脚本中,追加如下项:
message DataParameter{
enum DB{
LEVELDB=;
LMDB=;
}
optional string source=;
optional uint32 batch_size=;
optional DB backend= [default=LMDB];
//4-way pre-buffering is enough for normal machines
optional uint32 prefech= [default=];
}
message LayerParameter{
optional string name=;
optional string type=;
optional DataParameter data_param=;
}
重新编译后,覆盖你的旧头文件和源文件。
DataParameter中,包含:数据库源路径、batch大小、数据库类型,以及预缓冲区大小。
比较特别的是预缓冲大小,默认是开4个Batch的预缓冲。如果你的GPU计算速度过快,明显大于
CPU供给数据的速度,消费者(DataLayer)经常提示缺数据,你得考虑加大预缓冲区数量。
将DataParameter嵌入到LayerParameter中去。
LayerParameter是一个巨型的数据结构,将包含所有类型Layer的超参数,你可以将其视为基类。
Body
class Body :public DragonThread{
public:
Body(const LayerParameter& param);
virtual ~Body();
vector<boost::shared_ptr<QueuePair>> new_pairs;
protected:
void interfaceKernel();
void read_one(Cursor *cursor, QueuePair *pair);
LayerParameter param;
};
Body实际上是一个线程,而DataReader却不是,尽管Body是DataReader成员变量。
Body的构造函数和析构函数就是启动线程和停止线程:
Body::Body(const LayerParameter& param) :param(param) { startThread();}
Body::~Body() { stopThread();}
线程工作函数比较复杂:
void Body::interfaceKernel(){
boost::shared_ptr<DB> db(GetDB(param.data_param().backend()));
db->Open(param.data_param().source(), DB::READ);
boost::shared_ptr<Cursor> cursor(db->NewCursor());
try{
// default solver_count=1
int solver_count = param.phase() == TRAIN ? Dragon::get_solver_count() : ;
// working period
while (!must_stop()){
for (int i = ; i < solver_count; i++)
read_one(cursor.get(), new_pairs[i].get());
}
// complex condition
} catch (boost::thread_interrupted&) {}
}
该函数将会一直卡在循环里,直到训练结束,Body执行析构函数,将线程执行停止。
Body-DataReader构成了Caffe数据缓冲的第一级别:数据库->Datum 。
在DataLayer中,还会进行第二级别的缓冲:Datum->Blob->Batch,将在后续分析。
最后,还剩下一个read_one函数:
void Body::read_one(Cursor *cursor, QueuePair *pair){
Datum *datum = pair->free.pop();
datum->ParseFromString(cursor->value());
pair->full.push(datum);
cursor->Next();
if (!cursor->valid()){
DLOG(INFO) << "Restarting data prefeching from start.\n";
cursor->SeekToFirst();
}
}
read_one每次从一个双缓冲组的free队列中取出空Datum指针。
利用Protocol Buffer的反序列化函数ParseFromString,从数据库中还原Datum,再扔到full队列里。
感谢Protocol Buffer,否则这部分的代码估计不下200行。
当数据库跑完之后,需要回到开头,再次重读,为迭代过程反复提供数据。
这一步只适合训练过程,如果你要一次测试自己的数据,请忘记这个函数,重写一个不要反复读的版本。
DataReader
class DataReader
{
public:
DataReader(const LayerParameter& param);
BlockingQueue<Datum*>& free() const { return ptr_pair->free; }
BlockingQueue<Datum*>& full() const { return ptr_pair->full; }
~DataReader();
static string source_key(const LayerParameter& param){
return param.name() + ":" + param.data_param().source();
}
private:
LayerParameter param;
boost::shared_ptr<QueuePair> ptr_pair;
boost::shared_ptr<Body> ptr_body;
static map<string, boost::weak_ptr<Body> > global_bodies;
};
该结构上文已经全面解析过。
在cpp的实现中,首先完成类静态成员变量的外部初始化。
map<string, boost::weak_ptr<Body> > DataReader::global_bodies;
以及一个静态mutex的定义:
static boost::mutex bodies_mutex;
该mutex是Caffe挖的坑之一,虽然默认不会生效,倒是给出了不错的指导。
当构建多生产者单缓冲区时,我们将会有多个Body,即多个DataReader,即多个DragonThread。
这意味着,Body的Hash容器将成为一个互斥资源。
该Hash容器的存在不是没有必要的,由于:
每个数据来源只能用一次,为了避免重复路径,显然需要Hash。
DataReader::DataReader(const LayerParameter& param){
ptr_pair.reset(new QueuePair(
param.data_param().prefech()*param.data_param().batch_size()));
boost::mutex::scoped_lock lock(bodies_mutex);
string hash_key = source_key(param);
boost::weak_ptr<Body> weak = global_bodies[hash_key];
ptr_body = weak.lock();
if (!ptr_body){
ptr_body.reset(new Body(param));
global_bodies[hash_key] = boost::weak_ptr<Body>(ptr_body);
}
ptr_body->new_pairs.push(ptr_pair);
}
DataReader的构造函数首先根据用户指定的预缓冲区大小,初始化默认的双缓冲队列组。
接下来,要在Body的Hash容器中登记,mutex锁住,修改之后解锁。
登记所使用的是weak_ptr,weak_ptr可看作shared_ptr的助手,通常视为观察者(Viewer)。
不可使用->,只能调用lock函数获得shared_ptr。
DataReader的析构,主要任务是析构Body,以及从Hash容器中反登记。
DataReader::~DataReader(){
string hash_key = source_key(param);
ptr_body.reset();
boost::mutex::scoped_lock lock(bodies_mutex);
if (global_bodies[hash_key].expired()) global_bodies.erase(hash_key);
}
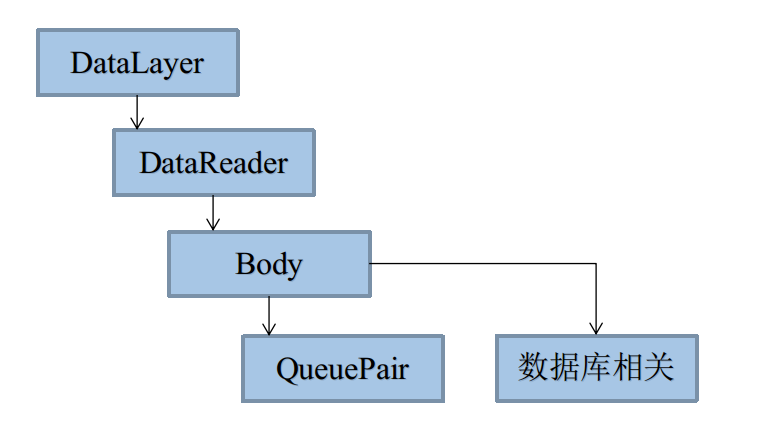
析构体系
DataReader中涉及几个比较重要的析构,这里以图描述下:
完整代码
data_reader.hpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_include/data_reader.hpp
data_reader.cpp
https://github.com/neopenx/Dragon/blob/master/Dragon/data_src/data_reader.cpp
从零开始山寨Caffe·捌:IO系统(二)的更多相关文章
- 从零开始山寨Caffe·拾贰:IO系统(四)
消费者 回忆:生产者提供产品的接口 在第捌章,IO系统(二)中,生产者DataReader提供了外部消费接口: class DataReader { public: ......... Blockin ...
- 从零开始山寨Caffe·陆:IO系统(一)
你说你学过操作系统这门课?写个无Bug的生产者和消费者模型试试! ——你真的学好了操作系统这门课嘛? 在第壹章,展示过这样图: 其中,左半部分构成了新版Caffe最恼人.最庞大的IO系统. 也是历来最 ...
- 从零开始山寨Caffe·零:必先利其器
工作环境 巧妇有了米炊 众所周知,Caffe是在Linux下写的,所以长久以来,大家都认为跑Caffe,先装Linux. niuzhiheng大神发起了caffe-windows项目(解决了一些编译. ...
- 从零开始山寨Caffe·拾:IO系统(三)
数据变形 IO(二)中,我们已经将原始数据缓冲至Datum,Datum又存入了生产者缓冲区,不过,这离消费,还早得很呢. 在消费(使用)之前,最重要的一步,就是数据变形. ImageNet Image ...
- 从零开始山寨Caffe·肆:线程系统
不精通多线程优化的程序员,不是好程序员,连码农都不是. ——并行计算时代掌握多线程的重要性 线程与操作系统 用户线程与内核线程 广义上线程分为用户线程和内核线程. 前者已经绝迹,它一般只存在于早期不支 ...
- 从零开始山寨Caffe·柒:KV数据库
你说你会关系数据库?你说你会Hadoop? 忘掉它们吧,我们既不需要网络支持,也不需要复杂关系模式,只要读写够快就行. ——论数据存储的本质 浅析数据库技术 内存数据库——STL的map容器 关 ...
- 从零开始山寨Caffe·玖:BlobFlow
听说Google出了TensorFlow,那么Caffe应该叫什么? ——BlobFlow 神经网络时代的传播数据结构 我的代码 我最早手写神经网络的时候,Flow结构是这样的: struct Dat ...
- 从零开始山寨Caffe·伍:Protocol Buffer简易指南
你为Class外访问private对象而苦恼嘛?你为设计序列化格式而头疼嘛? ——欢迎体验Google Protocol Buffer 面向对象之封装性 历史遗留问题 面向对象中最矛盾的一个特性,就是 ...
- 从零开始山寨Caffe·叁:全局线程管理器
你需要一个管家,随手召唤的那种,想吃啥就吃啥. ——设计一个全局线程管理器 一个机器学习系统,需要管理一些公共的配置信息,如何存储这些配置信息,是一个难题. 设计模式 MVC框架 在传统的MVC编程框 ...
随机推荐
- javascript实用技巧、javascript高级技巧
字号+作者:H5之家 来源:H5之家 2016-10-31 11:00 我要评论( ) 三零网提供网络编程. JavaScript 的技术文章javascript实用技巧.javascript高级技巧 ...
- JS生成指定范围内的数组
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- BZOJ 2086: [Poi2010]Blocks
Description 每次可以将大于 \(k\) 的一个数 \(-1\), 在左边或右边的数 \(+1\) ,问最大能得到多长的序列每个数都大于等于 \(k\) . Sol 单调栈. 这道题好神啊q ...
- ProgressBar---进度条
最近在处理标题进度条时,耗费了一些时间,现在总结一下ProgressBar的相关知识,有不对的地方请大神们批评指正! 进度条主要有以下三种: 1.对话框进度条 2.标题进度条 注意:requestWi ...
- 在Xcode5中修改整个项目名
总会遇到几个项目,在做到一半的时候被要求改项目名,网上找了下相关的资料,大多数是xcode5以前的版本,所以解决好了在这里mark一下,给需要的人. 目标为:将项目名XCD4改成xcd5. 先上结果图 ...
- css单位盘点
css单位有:px,em,rem,vh,vw,vmin,vmax,ex,ch 等等 1.px单位最常见,也最直接,这里不做介绍. 2.em:em的值并不是固定,它继承父级元素的字体大小,所以层数越深字 ...
- Fabric远程自动化使用说明
背景: 关于Fabric的介绍,可以看官网说明.简单来说主要功能就是一个基于Python的服务器批量管理库/工具,Fabric 使用 ssh(通过 paramiko 库)在多个服务器上批量执行任务.上 ...
- 修改组策略,禁止用户修改IP
运行中打开gepdit.msc,依次打开用户配置,管理模板,网络,网络连接:在右侧将“禁止访问LAN链接组建的属性”.“为管理员启用windows2000网络连接设置”设置为已启用即可令用户无法访问网 ...
- 【笔记】MySQL查询排名
select a.name, a.total_score,@rank:=@rank+1 as rank from ( select u.name,uti.total_ ...
- 详解Java 8中Stream类型的“懒”加载
在进入正题之前,我们需要先引入Java 8中Stream类型的两个很重要的操作: 中间和终结操作(Intermediate and Terminal Operation) Stream类型有两种类型的 ...