hadoop streaming anaconda python 计算平均值
原始Liunx 的python版本不带numpy ,安装了anaconda 之后,使用hadoop streaming 时无法调用anaconda python ,
后来发现是参数没设置好。。。
进入正题:
环境:
4台服务器:master slave1 slave2 slave3。
全部安装anaconda2与anaconda3, 主环境py2 。anaconda2与anaconda3共存见:Ubuntu16.04 Liunx下同时安装Anaconda2与Anaconda3
安装目录:/home/orient/anaconda2
Hadoop 版本2.4.0
数学原理:
设有一组数字,这组数字的均值和方差如下:
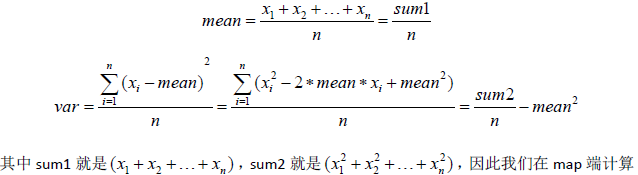
每个部分的{count(元素个数)、sum1/count、sum2/count},然后在reduce端将所有map端传入的sum1加起来在除以总个数n得到均值mean;将所有的sum2加起来除以n再减去均值mean的平方,就得到了方差var.
数据准备:
inputFile.txt 一共100个数字 全部数据 下载:
0.970413
0.901817
0.828698
0.197744
0.466887
0.962147
0.187294
0.388509
0.243889
0.115732
0.616292
0.713436
0.761446
0.944123
0.200903
编写mrMeanMapper.py
#!/usr/bin/env python
import sys
from numpy import mat, mean, power def read_input(file):
for line in file:
yield line.rstrip() input = read_input(sys.stdin)#creates a list of input lines
input = [float(line) for line in input] #overwrite with floats
numInputs = len(input)
input = mat(input)
sqInput = power(input,2) #output size, mean, mean(square values)
print "%d\t%f\t%f" % (numInputs, mean(input), mean(sqInput)) #calc mean of columns
print >> sys.stderr, "report: still alive"
编写mrMeanReducer.py
#!/usr/bin/env python
import sys
from numpy import mat, mean, power def read_input(file):
for line in file:
yield line.rstrip() input = read_input(sys.stdin)#creates a list of input lines #split input lines into separate items and store in list of lists
mapperOut = [line.split('\t') for line in input] #accumulate total number of samples, overall sum and overall sum sq
cumVal=0.0
cumSumSq=0.0
cumN=0.0
for instance in mapperOut:
nj = float(instance[0])
cumN += nj
cumVal += nj*float(instance[1])
cumSumSq += nj*float(instance[2]) #calculate means
mean = cumVal/cumN
meanSq = cumSumSq/cumN #output size, mean, mean(square values)
print "%d\t%f\t%f" % (cumN, mean, meanSq)
print >> sys.stderr, "report: still alive"
本地测试mrMeanMapper.py ,mrMeanReducer.py
cat inputFile.txt |python mrMeanMapper.py |python mrMeanReducer.py

我把 inputFile.txt,mrMeanMapper.py ,mrMeanReducer.py都放在了同一目录下 ~/zhangle/Ch15/hh/hh
所有的操作也都是这此目录下!!!
将inputFile.txt上传到hdfs
zhangle/mrmean-i 是HDFS上的目录
hadoop fs -put inputFile.txt zhangle/mrmean-i
运行Hadoop streaming
hadoop jar /usr/programs/hadoop-2.4./share/hadoop/tools/lib/hadoop-streaming-2.4..jar \
-input zhangle/mrmean-i \
-output zhangle/output12222 \
-file mrMeanMapper.py \
-file mrMeanReducer.py \
-mapper "/home/orient/anaconda2/bin/python mrMeanMapper.py" \
-reducer "/home/orient/anaconda2/bin/python mrMeanReducer.py"
参数解释:
第一行:/usr/programs/hadoop-2.4.0/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar 是我Hadoop streaming 所在的目录
第二行: zhangle/mrmean-i 是刚才将inputFile.txt 上传的目录
第三行:zhangle/mrmean-out12222 是结果输出目录,也是在HDFS上
第四行: mrMeanMapper.py是当前目录下的mapper程序
第五行: mrMeanRdeducer.py是当前目录下的reducer程序
第六行: /home/orient/anaconda2/bin/python 是anaconda2目录下的python ,如果去掉,会直接调用自带的python,自带python没有安装numpy等python包。!!
第七行: 同第六行。
查看运行结果:
hadoop fs -cat zhangle/output12222/part-

问题解决
1. 出现“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 1”的错误
解决方法:
在hadoop上实施MapReduce之前,一定要在本地运行一下你的python程序,看
首先进入包含map和reduce两个py脚本文件和数据文件inputFile.txt的文件夹中。然后输入一下命令,看是否执行通过:
cat inputFile.txt |python mrMeanMapper.py |python mrMeanReducer.py
2.出现错误:“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 2”,或者出现jar文件找不到的情况,或者出现输出文件夹已经存在的情况。
- Mapper.py和Reduce.py的最前面要加上:#!/usr/bin/env python 这条语句
- 在Hadoop Streaming命令中,请确保按以下的格式来输入
hadoop jar /usr/programs/hadoop-2.4./share/hadoop/tools/lib/hadoop-streaming-2.4..jar \
-input zhangle/mrmean-i \
-output zhangle/output12222 \
-file mrMeanMapper.py \
-file mrMeanReducer.py \
-mapper "/home/orient/anaconda2/bin/python mrMeanMapper.py" \
-reducer "/home/orient/anaconda2/bin/python mrMeanReducer.py"- 要确保jar文件的路径正确,hadoop 2.4版本的该文件是保存在:$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-2.4.0.jar中,不同的hadoop版本可能略有不同HDFS中的输出文件夹(这里是HDFS下的/user/hadoop/mr-ouput13),一定要是一个新的(之前不存在)的文件夹,因为即使上条Hadoop Streaming命令没有执行成功,仍然会根据你的命令来创建输出文件夹,而后面再输入Hadoop Streaming命令如果使用相同的输出文件夹时,就会出现“输出文件夹已经存在的错误”;参数 –file后面是map和reduce的脚本,路径可以是详细的绝对路径,,也可以是当前路径,当前路径下一定要有mapper,reducer 函数,但是在参数 -mapper 和-reducer之后,需要指定python脚本的环境目录,而且用引号引起来。
3.出现错误:“Error: java.lang.RuntimeException: PipeMapRed.waitOutputThreads(): subprocess failed with code 127”.
脚本环境的问题 在第六行与第七行 加上python 环境目录即可。
参考:
http://www.cnblogs.com/lzllovesyl/p/5286793.html
http://www.zhaizhouwei.cn/hadoop/190.html
http://blog.csdn.net/wangzhiqing3/article/details/8633208
hadoop streaming anaconda python 计算平均值的更多相关文章
- Hadoop Streaming例子(python)
以前总是用java写一些MapReduce程序现举一个例子使用Python通过Hadoop Streaming来实现Mapreduce. 任务描述: HDFS上有两个目录/a和/b,里面数据均有3列, ...
- 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试
相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控 用python + hadoop streami ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- hadoop streaming 编程
概况 Hadoop Streaming 是一个工具, 代替编写Java的实现类,而利用可执行程序来完成map-reduce过程.一个最简单的程序 $HADOOP_HOME/bin/hadoop jar ...
- hadoop streaming编程小demo(python版)
大数据团队搞数据质量评测.自动化质检和监控平台是用django,MR也是通过python实现的.(后来发现有orc压缩问题,python不知道怎么解决,正在改成java版本) 这里展示一个python ...
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
这是参照<机器学习实战>中第15章“大数据与MapReduce”的内容,因为作者写作时hadoop版本和现在的版本相差很大,所以在Hadoop上运行python写的MapReduce程序时 ...
- Python科学计算(一)环境简介——Anaconda Python
Anaconda Python 是 Python 科学技术包的合集,功能和 Python(x,y) 类似.它是新起之秀,已更新多次了.包管理使用 conda,GUI基于 PySide,所有的包基本上都 ...
- 用python + hadoop streaming 编写分布式程序(三) -- 自定义功能
又是期末又是实训TA的事耽搁了好久……先把写好的放上博客吧 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍 ...
- Hadoop Streaming框架学习(一)
Hadoop Streaming框架学习(一) Hadoop Streaming框架学习(一) 2013-08-19 12:32 by ATP_, 473 阅读, 3 评论, 收藏, 编辑 1.Had ...
随机推荐
- (转)java泛型
转自:http://blog.csdn.net/lonelyroamer/article/details/7868820 java泛型(二).泛型的内部原理:类型擦除以及类型擦除带来的问题 参考:j ...
- 数据库存入数据后id保持不变,或者直接报错
数据库存入数据后id保持不变,且添加的数据一直在进行覆盖 或者直接报错 数据库存入数据后id保持不变,且添加的数据一直在进行覆盖 原因是: 之前注释掉了loadimage();在该函数中含有建立新的记 ...
- expected_conditions判断页面元素
expected_condtions提供了16种判断页面元素的方法: 1.title_is:判断当前页面的title是否完全等于预期字符串,返回布尔值 2.title_contains:判断当前页面的 ...
- SQLServer------数据类型在C#中的转换
SQL C#tinyint bytesmallint Int16char stringint int
- FragmentStatePagerAdapter写法
为了节省资源,分批加载数据//适配器class TabLayoutViewPagerAdapter extends FragmentStatePagerAdapter { public TabLayo ...
- JMS和ActiveMQ的关系
JMS和MQ的关系: JMS是一个用于提供消息服务的技术规范,它制定了在整个消息服务提供过程中的所有数据结构和交互流程.而MQ则是消息队列服务,是面向消息中间件(MOM)的最终实现,是真正的服务提供者 ...
- 在VS2013下如何配置DirectX SDK的开发环境_百度经验
jpg改rar
- 基于 Golang 的 xls 读取类库:xls
Golang 编写的 xls 读取类库,能够实现 xls 表格的读取功能 func (w *WorkBook) ReadAllCells() (res [][]string) { for _, she ...
- codevs 5962 [SDOI2017]数字表格
输入描述 Input Description [题解] 对于蓝色部分预处理前缀积. 然后在用除法分块搞一下. O(Q*sqrt(min(n,m))*logn+nlogn) #include<c ...
- Oracle Schema Objects(Schema Object Storage And Type)
One characteristic of an RDBMS is the independence of physical data storage from logical data struct ...