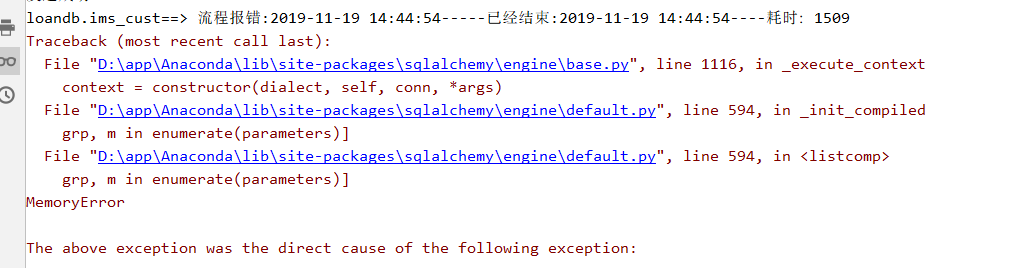
python panda读写内存溢出:MemoryError
pandas中read_xxx的块读取功能
pandas设计时应该是早就考虑到了这些可能存在的问题,所以在read功能中设计了块读取的功能,也就是不会一次性把所有的数据都放到内存中来,而是分块读到内存中,最后再将块合并到一起,形成一个完整的DataFrame。
def read_sql_table(table_name, con, schema=None, index_col=None,
coerce_float=True, parse_dates=None, columns=None,
chunksize=None):

1.chunksize是在一个每一个chunk块中有多少行。
2.当chunksize是非None的时候read_xxx返回的是一个迭代器
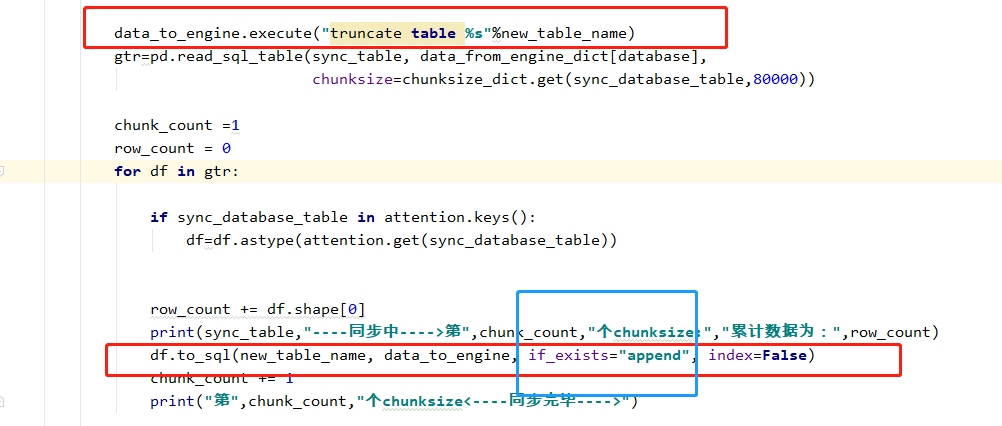
比如我自己的写的一个全量同步数据的代码如下:
gtr=pd.read_sql_table(sync_table, data_from_engine_dict[database],chunksize=20000)
count=0
for df in gtr:
if count==0:
df.to_sql(database+"_"+sync_table, data_to_engine, if_exists="replace", index=False)
else: df.to_sql(database + "_" + sync_table, data_to_engine, if_exists="append", index=False) count+=1
发现数据库中的表会被修改,我今天做了如下升级:
其他的read_xxx也有类似的参数
pandas.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]], sep=',', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None,
skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True,
iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, doublequote=True,
escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True,
memory_map=False, float_precision=None)[source]
我们再介绍一个不用改的参数:
low_memory : bool, default True
Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
To ensure no mixed types either set False, or specify the type with the dtype parameter.
Note that the entire file is read into a single DataFrame regardless, use the chunksize or iterator parameter to return the data in chunks.
(Only valid with C parser).
low_memory 默认就是True,如果不小心改成了False,chunksize参数不生效。
python panda读写内存溢出:MemoryError的更多相关文章
- POI读写大数据量excel,解决超过几万行而导致内存溢出的问题
1. Excel2003与Excel2007 两个版本的最大行数和列数不同,2003版最大行数是65536行,最大列数是256列,2007版及以后的版本最大行数是1048576行,最大列数是16384 ...
- Python之内存泄漏和内存溢出
预习知识:python之MRO和垃圾回收机制 一.内存泄漏 像Java程序一样,虽然Python本身也有垃圾回收的功能,但是同样也会产生内存泄漏的问题.对于一个用 python 实现的,长期运行的后台 ...
- android文件缓存,并SD卡创建目录未能解决和bitmap内存溢出解决
1.相关代码: 加入权限: <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" ...
- String内存溢出异常(错误)可能的原因及解决方式
摘要:本Blog主要为了阐述java.lang.OutOfMemoryError:PermGenspace可能产生的原因及解决方式. 当中PermGen space是Permanent Generat ...
- 【转】Python之mmap内存映射模块(大文本处理)说明
[转]Python之mmap内存映射模块(大文本处理)说明 背景: 通常在UNIX下面处理文本文件的方法是sed.awk等shell命令,对于处理大文件受CPU,IO等因素影响,对服务器也有一定的压力 ...
- Java之JVM调优案例分析与实战(2) - 集群间同步导致的内存溢出
环境:一个基于B/S的MIS系统,硬件为两台2个CPU.8GB内存的HP小型机,服务器是WebLogic 9.2,每台机器启动了3个WebLogic实例,构成一个6个节点的亲合式集群. 说明:由于是亲 ...
- 牛客网Java刷题知识点之内存溢出和内存泄漏的概念、区别、内存泄露产生原因、内存溢出产生原因、内存泄露解决方案、内存溢出解决方案
不多说,直接上干货! 福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 ...
- [Android随笔]内存泄漏以及内存溢出
名词解释 内存泄漏:memory leak,是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏危害能够忽略,但内存泄漏堆积后果非常严重,不管多少内存,迟早会被占光. 内存溢出:out of ...
- Python—文件读写操作
初识文件操作 使用open()函数打开一个文件,获取到文件句柄,然后通过文件句柄就可以进行各种各样的操作了,根据打开文件的方式不同能够执行的操作也会有相应的差异. 打开文件的方式: r, w, a, ...
随机推荐
- mysql数据恢复,binlog详解
个人博客:mysql数据恢复,binlog详解 binlog日志恢复数据,是挽救错误操作和数据损坏一根救命稻草,所以认识和使用binglog对于技术人员还是很有必要的 binlog一般用于 主从复制 ...
- STM32启动文件详解
启动文件使用的 ARM 汇编指令汇总 启动程序源码注释(点此下载) 1. Stack—栈 Stack_Size EQU 0x00000400 AREA STACK, NOINIT, READWRITE ...
- QLineEdit的信号函数
QLineEdit一共有6个信号函数,并不多,很好理解. ·void cursorPositionChanged( intold, intnew ) 当鼠标移动时发出此信号,old为先前的位置,new ...
- js 根据 数组条件 简单查询的方法临时保存
let array = [{ date: '2016-05-02', name: 'Ethan', status: 'success', total: '81' }, { date: '2016-05 ...
- 怎样对小数进行向上取整 / 向下取整 / 四舍五入 / 保留n位小数 / 生成随机数
1. 向上取整使用: Math.ceil() Math.ceil(0.1); Math.ceil(1.9); 2. 向下取整使用: Math.floor() Math.floor(0.1); Math ...
- 奇妙的算法【4】-汉诺塔&哈夫曼编码
1,汉诺塔问题[还是看了源码才记起来的,记忆逐渐清晰] 汉诺塔:汉诺塔(又称河内塔)问题是源于印度一个古老传说的益智玩具.大梵天创造世界的时候做了三根金刚石柱子,在一根柱子上从下往上按照大小顺序摞着6 ...
- 将mdf文件copy到docker对应的目录下
将mdf文件copy到docker对应的目录下: (<Docker-Container ID> 需要整体替换) docker cp /Users/Jay/Works/db/MyPost.m ...
- 华为Python面试题
最近在网上偶然看到此题: 有两个序列a,b,大小都为n,序列元素的值任意整形数,无序: 要求:通过交换a,b中的元素,使[序列a元素的和]与[序列b元素的和]之间的差最小 经过一番思索,我试着用穷举法 ...
- eclipse导入项目后出现红色叉号的解决方案
对于一名程序员来说,我导入的项目在项目的名称上无端加了一个红色的叉号,虽然这个不友好的符号,对于我整个的项目运行没有任何影响,但是总让我觉得不舒服,大大的叉号写在我的项目的脑袋上,我心里能舒服吗?于是 ...
- PowerBulider获取计算机mac地址
PowerBulider获取计算机mac地址 1.下载GETNET.DLL获取网络资源的API 2.PB的全局函数中的引入需要API,常用API列表如下 //得到计算机名字 function bool ...