python之scrapy模拟登陆人人网
1、settings.py主要配置信息,包括USER_AGENT等
# -*- coding: utf-8 -*- # Scrapy settings for renren project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'renren' SPIDER_MODULES = ['renren.spiders']
NEWSPIDER_MODULE = 'renren.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36' # Obey robots.txt rules
ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default)
#COOKIES_ENABLED = False # Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False # Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#} # Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'renren.middlewares.RenrenSpiderMiddleware': 543,
#} # Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'renren.middlewares.RenrenDownloaderMiddleware': 543,
#} # Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#} # Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#ITEM_PIPELINES = {
# 'renren.pipelines.RenrenPipeline': 300,
#} # Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
2、rr.py,主要模拟登陆
# -*- coding: utf-8 -*-
import scrapy
import time
import re
class RrSpider(scrapy.Spider):
name = 'rr'
allowed_domains = ['renren.com']
start_urls = ['http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=201961933877'] def start_requests(self):
base_url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp='
s = time.strftime("%S")
ms = int(round(time.time() % (int(time.time())), 3) * 1000)
date_time = '' + str(s) + str(ms)
login_url = base_url + date_time
data = {'email': '',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '',
'captcha_type': 'web_login',
'password': '41980c8f91e2c872910598a9e0a147d05934506893ef022c5b42357a67e0a3be',
'rkey': 'fc9dfa5a27bed56e61f122d80f2f401d',
'f':'http%3A%2F%2Fwww.renren.com%2FLogin.do%3Frf%3Dr%26origURL%3Dhttp%253A%252F%252Fwww.renren.com%252F971298880%252Fprofile'
}
yield scrapy.FormRequest(url=login_url, formdata=data, callback=self.parse_login, dont_filter=True) def parse_login(self, response):
yield scrapy.Request(url='http://www.renren.com/971298880/profile', callback=self.parse_text, dont_filter=True) def parse_text(self, response):
print(response.body.decode())
3、登陆信息
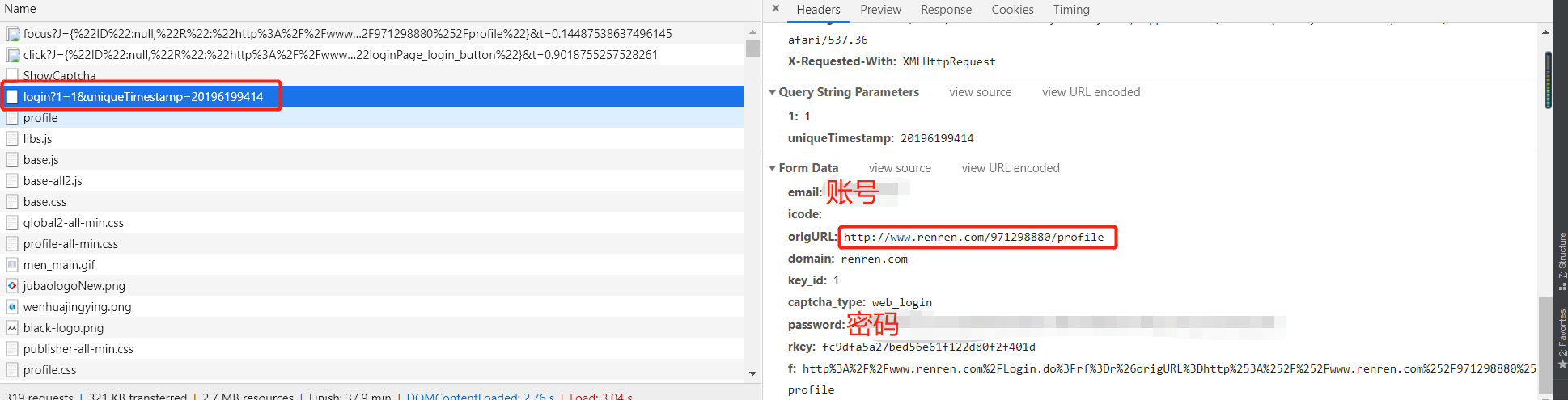
python之scrapy模拟登陆人人网的更多相关文章
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- 【python爬虫】用requests库模拟登陆人人网
说明:以前是selenium登陆取cookie的方法比较复杂,改用这个 """ 用requests库模拟登陆人人网 """ import r ...
- Python实现网站模拟登陆
一.实验简介 1.1 基本介绍 本实验中我们将通过分析登陆流程并使用 Python 实现模拟登陆到一个实验提供的网站,在实验过程中将学习并实践 Python 的网络编程,Python 实现模拟登陆的方 ...
- Scrapy模拟登陆
1. 为什么需要模拟登陆? #获取cookie,能够爬取登陆后的页面 2. 回顾: requests是如何模拟登陆的? #1.直接携带cookies请求页面 #2.找接口发送post请求存储cooki ...
- Scrapy 模拟登陆知乎--抓取热点话题
工具准备 在开始之前,请确保 scrpay 正确安装,手头有一款简洁而强大的浏览器, 若是你有使用 postman 那就更好了. Python 1 scrapy genspid ...
- Scrapy模拟登陆豆瓣抓取数据
scrapy startproject douban 其中douban是我们的项目名称 2创建爬虫文件 进入到douban 然后创建爬虫文件 scrapy genspider dou douban. ...
- python用scrapy模拟用户登录
scrapy模拟登录 关注公众号"轻松学编程"了解更多. 注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 ...
- scrapy实战--登陆人人网爬取个人信息
今天把scrapy的文档研究了一下,感觉有点手痒,就写点东西留点念想吧,也做为备忘录.随意写写,看到的朋友觉得不好,不要喷我哈. 创建scrapy工程 cd C:\Spider_dev\app\scr ...
- 爬虫入门之scrapy模拟登陆(十四)
注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 COOKIES_ENABLED = True或# COOKIES_ENABLE ...
随机推荐
- django框架—终端命令
创建一个虚拟环境:在虚拟环境中创建项目目录 cd到项目根目录 创建项目:django-admin startproject "项目名称" 创建app:python manage.p ...
- Linux基础篇之FTP服务器搭建(一)
一.配置网络可以访问互联网(没有条件的可以提前下载相关版本的依赖包(也叫安装包,以下统称依赖包)上传到系统中也可以). 二.检查系统中是否存在相关的依赖包. 没有返回信息,说明系统中不存在相关的依赖包 ...
- SQL Server 排序规则的影响
目录 SQL Server 排序规则 影响 效果演示 更改数据库排序规则 服务器级排序规则 数据库级排序规则 列级排序规则 查询时指定规则 建议 使用 Unicode 数据类型 使用二进制排序规则 [ ...
- python+selenium之——错误:selenium.common.exceptions.WebDriverException: Message: ‘geckodriver’ executable needs to be in PATH.
此时,需要自己配置geckodriver 下载geckodriver,地址:https://github.com/mozilla/geckodriver/releases 下载后解压得到geckodr ...
- linux基础_用户和组的三个文件
1./etc/passwd文件 用户(user)的配置文件,记录用户的各种信息 每行的含义:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录shell 2./etc/shadow文件 口令 ...
- prev([expr]) 取得一个包含匹配的元素集合中每一个元素紧邻的前一个同辈元素的元素集合。
prev([expr]) 概述 取得一个包含匹配的元素集合中每一个元素紧邻的前一个同辈元素的元素集合. 可以用一个可选的表达式进行筛选.只有紧邻的同辈元素会被匹配到,而不是前面所有的同辈元素.直线电机 ...
- 【luoguP1955 】[NOI2015]程序自动分析--普通并查集
题目描述 在实现程序自动分析的过程中,常常需要判定一些约束条件是否能被同时满足. 考虑一个约束满足问题的简化版本:假设x1,x2,x3...代表程序中出现的变量,给定n个形如xi=xj或xi≠xj的变 ...
- 数据类型(C++)
不同系统会有不同差异: 类型 位(byte) 范围 char 1 -128—127 or 0 – 255 unsigned char 1 0 – 255 signed int 1 -128—127 i ...
- SpringMVC——数据乱码问题
乱码解决: 1.controller传递数据给页面 :在RequestMapping当中指定produces="text/json;charset=utf-8" 2.Control ...
- 对AM信号FFT的matlab仿真
普通调幅波AM的频谱,大信号包络检波频谱分析 u(t)=Ucm(1+macos t)cos ct ma称为调幅系数 它的频谱由载波,上下边频组成 , 包络检波中二极管截去负半周再用电容低通滤波,可 ...