[Java复习] 集合框架 Collection
Q1 Collection
java的集合以及集合之间的继承关系?

数组和链表的区别?
固定长度,连续内存,不能扩展,随机访问快,插入删除慢。链表相反
List, Set, Map的区别?
List,Set继承Collection接口
List可以放重复数据,Set不能,Map是k-v对
List和Map的实现方式以及存储方式?
ArrayList: 底层动态数组。随机访问快,增删慢,线程不安全。
扩容导致数组复制,批量删除会导致找两个集合交集,效率低。
LinkedList: 底层链表(双向列表)。增删快,查找慢,线程不安全。
遍历: 1.普通for循环,元素越多后面越慢 2.迭代器:每次访问,用游标记录当前位置
根据下标获取node,会根据index处于前半段还是后半段进行折半,提升效率。
HashMap: 散列表, 数组+链表+红黑树(JDK1.8) 默认16, 扩容2的幂
Q2 List
ArrayList实现原理?
动态数组,默认10,扩容grow(minCapacity),增加到1.5倍
ArrayList和LinkedList的区别,以及应用场景?
1.动态数组和双向队列链表。
2.ArrayList(实现了RandomAccess接口)用for循环遍历优于迭代器,LinkedList则相反。
3.ArrayList在数组任意位置插入,或导致该位置后面元素重新排列,效率相对低。
LinkedList增删只需移动指针,时间效率高。不需扩容,空间效率也高。但随机访问元素时间效率低。
链表翻转? 手写链表逆序代码?
方法1:递归: 从最后一个Node开始,在弹栈的过程中将指针顺序置换。
public class Node {
private String data;
private Node next;
// Getter() & Setter()
}
public Node reverse(Node head) {
if (head == null || head.getNext() == null) {
return head;
}
Node temp = head.getNext();
Node newHead = reverse(head.getNext());
temp.setNext(head);
head.setNext(null);
return newHead;
}
解析:递归本质是系统压栈,压栈时保留现场。
例子:A->B->C->D
程序先压栈,到达倒数第2个节点时(C),C的next为D, reverse(D)返回D。
接着就是弹栈过程,执行temp.setNext(head); 此时temp是D, head是C,temp的next设置为C, 就是D->C, 不过head是C,还有next是D,这句会形成环(D->C->D)。需要下一句head.setNext(null);把C的next指针断开,形成D->C(C.next->null)的反转最后2个节点。返回新链表的头结点newHead,也就是D。后面进行相同操作,最终完成整个链表的反转。
方法2:遍历: 在链表遍历的过程中将指针顺序置换。
public Node traverseReverse(Node head) {
Node pre = null;
Node next;
while(head != null) {
next = head.getNext();
head.setNext(pre);
pre = head;
head = next;
}
return pre;
}
解析:在head点遍历, 第一次时为A节点,next为B节点,head(A)节点的next设置为前一个节点pre(当前为null),把head节点赋给pre,pre为A节点,再把next节点(B)赋给head。
进行下一次循环,head为B节点,pre为A节点,head(B)节点的next设置为前一个节点pre(A),形成B->A,再复制给pre。Head移动到下一个节点。依次继续循环。。。
判断一个单链表是否有环?如果有环找出环的起点,以及环的长度?
方法一,穷举遍历。用新节点ID和此节点之前所有节点ID依次比较,如发现存在相同ID,则有环。时间复杂度O(N*N), 没有额外空间,空间复杂度O(1)
方法二,哈希表HashSet缓存。如发现存在相同节点,则说明有环。时间复杂度O(N),空间复杂度O(N)。
方法三,快慢指针。快指针移动2个节点,慢指针移动1个节点。然后比较2个指针节点是否相同。相同有环。
Q3 Map
HashMap数据结构,实现原理?put, get, resize等工作原理?
HashMap存储key-value键值对。Key和value都允许为null。Key重复会被覆盖,value可以重复。无序。非线程安全。
JDK1.7 数组+链表,JDK1.8 数组+链表+红黑树。
默认集合容量16,默认填充因子0.75,数组长度为2的幂次方,链表长度>8,集合容量>64,链表转红黑树,当红黑树节点个数小于6,又会转化为链表。新增红黑树作为底层数据结构,在数据量较大且哈希碰撞较多时,提高索引效率。
HashMap实现原理:
底层table,是一个Node<K,V>的数组,当添加一个元素时,先计算key的hash值,以此确定插入table的位置。如果同一个hash的元素已经放入在table的同一位置,则添加到该元素的后面,形成链表。当链表过长时,转化为红黑树,提高查询效率。
计算数组table索引的方法:(算hash是1,2步,第3步算table索引)
1. 取 hashCode 值: h = key.hashCode()
2. 高位参与运算:h ^ (h>>>16)
好处:右位移16位,正好是32bit的一半,高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。
3. 取模运算:(table.length - 1) & hash
为什么用&,不用%? 因为lenth = 2n 时,X % length = X & (length - 1), & 的效率比 % 高很多。
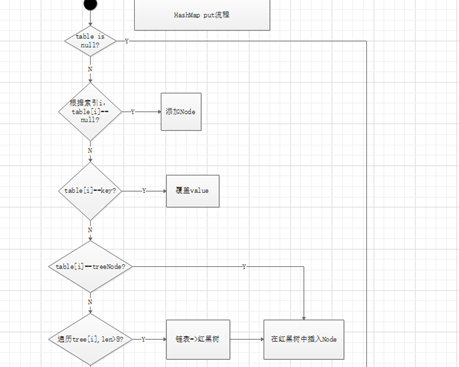
Put()方法工作原理:
① 判断键值对数组 table 是否为空或为null,否则执行resize()进行扩容;
② 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③ 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④ 判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤ 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树(treeifyBin),在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥ 插入成功后,判断实际存在的键值对数量size是否超过了最大容量threshold,如果超过,进行扩容resize()。
⑦ 如果新插入的key不存在,则返回null,如果新插入的key存在,则返回原key对应的value值(注意新插入的value会覆盖原value值)
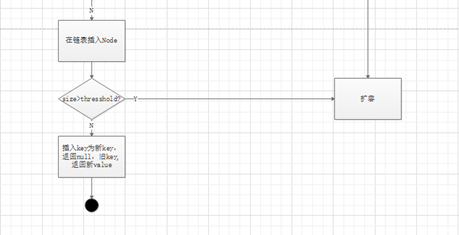
Resize扩容的工作原理:
1.计算新桶数组的容量 newCap
2.新阀值 newThr
3. 将原集合的元素重新映射到新集合中
3.1 既不是链表又不是红黑树,直接插入
3.2 红黑树,调用split方法重新分配
3.3.链表,不用像JDK1.7重新计算hash,只看原hash值新增的bit是1还是0,是0则索引不变,是1则索引变为”原索引+oldCap”
Get工作原理:
1. 通过key的hash计算table索引位置:hash & (length - 1)。
2. 检查数组该位置节点是否刚好是要找的元素,如果是则返回,如果不是则第3步。
3. 判断该元素时否TreeNode, 如果是则用红黑树TreeNode的方法find查找元素。如果不是则第4步。
4.遍历链表,找到相等(==或equals)的key。
HashMap线程不安全实际会如何体现?
1. 多线程同时Put元素,假设key发生碰撞(hash相同),这个两个key会添加到数组同一个位置,其中一个线程的数据被覆盖。
2. 多线程同时检查到需要扩容,都在重新计算元素位置及复制数据,最终只有一个线程扩容后的数组会赋值给table,其他线程会丢失。
HashMap如何变成线程安全?
1. Collections.synchronizeMap();
2. ConcurrentHashMap(java.util.concurrent). JDK1.5+
为什么String, Integer这样的wrapper类适合作为键?
String是不可变的,所以他创建的时候hashcode就被缓存了,不需要重新计算。还有字符串的处理速度要快过其他的键对象。
Integer的hashcode返回本身的值,也是不变的。
重新调整HashMap的大小存在什么问题?
JDK1.7多线程会产生竞争条件(race condition)。
两个线程同时尝试调整大小。调整过程,存储链表中元素次序会反过来,放在头部不是尾部,是为了避免尾部遍历(tail traversing)。如果竞争条件发生,就产生死循环。
HashMap中如何解决碰撞问题?如何减少碰撞?
在调用Put和get方法时,首先通过key的hashcode方法计算哈希桶的位置在存储对象。当获取对象时,通过键对象的equals()方法找到正确的键值对。
HashMap使用链表来解决碰撞问题,当碰撞发生了,对象将会存储在链表的下一个节点。
减少碰撞:1. 使用不可变,声明为final的对象,比如String 作为Key。
2.采用合适的equals()和hashCode()方法,将会减少碰撞发生,提高效率。String已经重写了equals和hashcode方法,很适合作为HashMap的Key。
LinkedHashMap和TreeMap是如何保证它的顺序的?
LinkedHashMap继承HashMap.Node的属性,额外增加了before, after用于指向前一个Entry和后一个Entry,在哈希表继承上构成双向链表。可以按照插入的顺序排序的Map。
TreeMap是按照Key的自然顺序或者Comparator的顺序进行排序。
LinkedHashMap是双向链表,TreeMap是红黑树。
它们两个哪个的有序实现比较好?
如果要按自然顺序或自定义顺序遍历键,那么TreeMap实现更好。如果需要输出的顺序和输入的相同,那么用LinkedHashMap实现更好。
Collection思维导图Github地址:
https://github.com/channingy/JavaSummary/
参考资料:
https://www.cnblogs.com/ysocean/p/8657850.html
https://www.cnblogs.com/ysocean/p/8711071.html
https://www.cnblogs.com/litexy/p/9744241.html
[Java复习] 集合框架 Collection的更多相关文章
- Java自学-集合框架 Collection
Java集合框架 Collection Collection是一个接口 步骤 1 : Collection Collection是 Set List Queue和 Deque的接口 Queue: 先进 ...
- java学习——集合框架(Collection,List,Set)
集合类的由来: 对象用于封装特有数据,对象多了需要存储,如果对象的个数不确定,就使用集合容器进行存储. 集合特点:1,用于存储对象的容器.2,集合的长度是可变的.3,集合中不可以存储基本数据类型值. ...
- Java集合框架Collection
转自:http://www.cdtarena.com/javapx/201306/8891.html [plain] view plaincopyprint?01.在 Java2中,有一套设计优良的接 ...
- Java中的集合框架-Collection(二)
上一篇<Java中的集合框架-Collection(一)>把Java集合框架中的Collection与List及其常用实现类的功能大致记录了一下,本篇接着记录Collection的另一个子 ...
- 理解java集合——集合框架 Collection、Map
1.概述: @white Java集合就像一种容器,可以把多个对象(实际上是对象的引用,但习惯上都称对象)"丢进"该容器中. 2.Java集合大致可以分4类: @white Set ...
- java的集合框架最全详解
java的集合框架最全详解(图) 前言:数据结构对程序设计有着深远的影响,在面向过程的C语言中,数据库结构用struct来描述,而在面向对象的编程中,数据结构是用类来描述的,并且包含有对该数据结构操作 ...
- java.util 集合框架集合
java的集合框架为程序提供了一种处理对象组的标准方式.设计了一系列标准泛型接口: ⑴Collection ()接口,扩展了Iterable接口,位于集合层次结构的顶部,因此所有的集合都实现Colle ...
- Java基础——集合框架
Java的集合框架是Java中很重要的一环,Java平台提供了一个全新的集合框架.“集合框架”主要由一组用来操作对象的接口组成.不同接口描述一组不同数据类型.Java平台的完整集合框架如下图所示: 上 ...
- java的集合框架之一
java是一套很成熟的东西,很多商用的东西都喜欢用它,用的人多,稳定.不过一般也不怎么说起它,因为太常见了,私下里说,写java应用层得就像农民工,每一处都是搭积木,根据设计师的东西如何优雅地搭好积木 ...
随机推荐
- 第一章、接口规范之Restful规范
阅读目录 2.1 数据的安全保障 2.2 接口特征表现 2.3 多数据版本共存 2.4 数据即是资源 2.5 资源操作由请求方式决定 3.1 正常响应 3.2 重定向响应 3.3 客户端异常 3.4 ...
- 第一章、前端之html
目录 第一章.前端之html 一. html介绍 第一章.前端之html 一. html介绍 web服务本质 import socket sk = socket.socket() sk.bind((& ...
- map()函数浅析
MapReduce的设计灵感来自于函数式编程,这里不打算提MapReduce,就拿python中的map()函数来学习一下. 文档中的介绍在这里: map(function, iterable, .. ...
- 一图一知-TS的基本数据类型
- 求 无向图的割点和桥,Tarjan模板
/* 求 无向图的割点和桥 可以找出割点和桥,求删掉每个点后增加的连通块. 需要注意重边的处理,可以先用矩阵存,再转邻接表,或者进行判重 */ const int MAXN = 10010; cons ...
- hg如何回退到某个版本
hg 如何回退 hg ... ? ? ?
- JavaScript 对象中this的指向问题
this运行在哪个对象下,就指向哪个对象.
- CSS基础学习-15-1.CSS 浏览器内核
- rac 数组之遍历
rac的数组遍历其实很简单.但是有个点需要注意. 以下先举个例子说明遍历的用法 NSArray *temArr = @["]; [temArr.rac_sequence.signal sub ...
- RAID 10是将RAID 1和RAID 0结合
RAID 10是将RAID 1和RAID 0结合,它的优点是同时拥有RAID 0的超凡速度和RAID 1的数据高可靠性,但是CPU占用率同样也更高,而且磁盘的利用率比较低.由于利用了RAID 0极高的 ...