Go项目实战:打造高并发日志采集系统(一)
项目结构
本系列文章意在记录如何搭建一个高可用的日志采集系统,实际项目中会有多个日志文件分布在服务器各个文件夹,这些日志记录了不同的功能。随着业务的增多,日志文件也再增多,企业中常常需要实现一个独立的日志采集系统,实时采集各个日志信息,并记录和输出到控制台或网页上,方便监控和查询。
本文日志采集系统架构如下
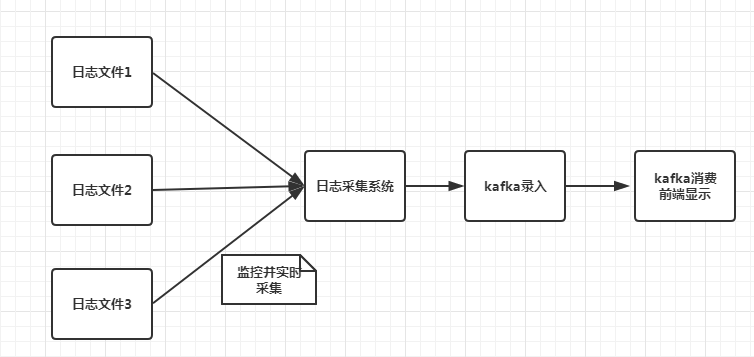
日志采集系统监控各个日志文件,当日志文件有日志录入时,日志采集系统实时获取日志内容并下入kafka队列中,之后可以实现Web端从kafaka取出信息,并前端显示。也可以将kafka的信息控制台输出,这个主要是看具体需求。本系列文章主要讲述如何搭建kafaka服务,编写高并发日志采集系统,稳定高效录入信息,以及从kafka中读取采集的日志。
本节目标
1 配置kafka,并启动消息队列。
2 编写代码向kafka录入消息,并且从kafka读取消息。
kafka简介和搭建
Kafka是一种高吞吐量的分布式发布订阅消息系统,由Java编写,内部使用了zookeeper(分布式应用程序协调服务),所以安装Kafka之前需要先安装jdk和zookeeper。
JDK安装
去官网https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html下载jdk,按步骤安装。之后配置环境变量即可。
Zookeeper安装
这里说下windows安装流程,linux类似。
从网址http://zookeeper.apache.org/releases.html下载zookeeper,之后解压即可使用。我在windows创建了一个文件夹D:\kafkazookeeper,将zookeeper解压到该文件夹。打开D:\kafkazookeeper\zookeeper-3.4.14\conf,把zoo_sample.cfg复制一份命名为zoo.cfg,从文本编辑器里打开zoo.cfg修改如下内容
dataDir=D:\\kafkazookeeper\\zookeeper-3.4.14\\data
dataLogDir=D:\\kafkazookeeper\\zookeeper-3.4.14\\log
目录根据你个人设置就行了。接下来添加如下环境变量
ZOOKEEPER_HOME: D:\kafkazookeeper\zookeeper-3.4.14
Path: 在现有的值后面添加 ";%ZOOKEEPER_HOME%\bin;
ZOOKEEPER_HOME值就是你的kafka安装目录。接下来进入D:\kafkazookeeper\zookeeper-3.4.14\bin启动zkServer.cmd
看到zookeeper服务跑起来了,默认端口为2181,不要关闭。
kafka安装
下载地址http://kafka.apache.org/downloads.html
将其解压到我自己的D:\kafkazookeeper目录下,打开D:\kafkazookeeper\kafka_2.12-2.2.0\config修改log.dirs,设置为
log.dirs=D:\\kafkazookeeper\\kafka_2.12-2.2.0\\logs
在kafka目录里执行如下命令,启动kafka
.\bin\windows\kafka-server-start.bat .\config\server.properties
测试kafka
创建topics
在kafka目录里执行如下命令
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
这样我们创建了一个主题,这个主题相当于一个标签,用于消息读写。
打开一个Producer
同样在kafka目录下执行
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
这样我们基于test主题启动了一个生产者
打开一个Consumer
同样在kafka目录下执行
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
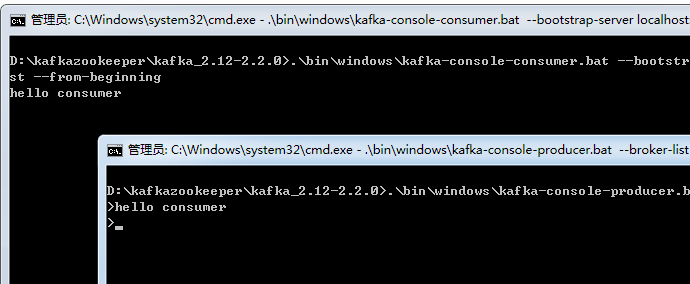
我们在生产者窗口写一些消息注入hello consumer,消费者窗口会取出消息并显示 hello consumer
实现代码向kafka写入消息
func main() {
config := sarama.NewConfig()
// 等待服务器所有副本都保存成功后的响应
config.Producer.RequiredAcks = sarama.WaitForAll
// 随机的分区类型:返回一个分区器,该分区器每次选择一个随机分区
config.Producer.Partitioner = sarama.NewRandomPartitioner
// 是否等待成功和失败后的响应
config.Producer.Return.Successes = true
// 使用给定代理地址和配置创建一个同步生产者
producer, err := sarama.NewSyncProducer([]string{"localhost:9092"}, config)
if err != nil {
panic(err)
}
defer producer.Close()
//构建发送的消息,
msg := &sarama.ProducerMessage{
//Topic: "test",//包含了消息的主题
Partition: int32(10), //
Key: sarama.StringEncoder("key"), //
}
inputReader := bufio.NewReader(os.Stdin)
for{
value, _ , err := inputReader.ReadLine()
if err != nil {
fmt.Printf("error:", err.Error())
return
}
msgType , _, err := inputReader.ReadLine()
msg.Topic = string(msgType)
fmt.Println("topic is : ",msg.Topic)
fmt.Println("value is : ",string(value))
msg.Value = sarama.ByteEncoder(value)
partition, offset, err := producer.SendMessage(msg)
if err != nil {
fmt.Println("Send message Fail")
fmt.Println(err.Error())
}
fmt.Printf("Partition = %d, offset=%d\n", partition, offset)
}
}
上述代码基于本地端口9092创建了生产者,然后构造了消息的分区大小以及Key值,接下来循环读取终端录入信息,第一行为value,第二行为topic,然后将消息发送到kafka,并且打印存储的分区和位移。
我们运行我们的程序,录入消息,可以看到消息发送到kafka后被消费者获取。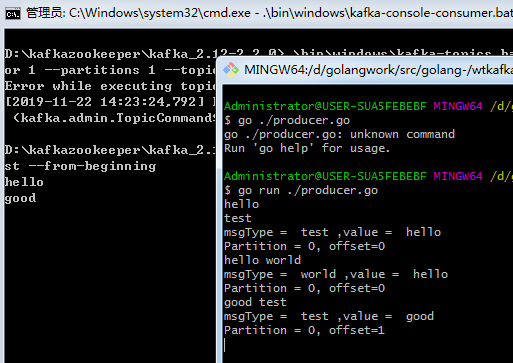
下一篇,我们完善消费者程序,并且实现文件监控和读取
。
谢谢关注我的公众号

Go项目实战:打造高并发日志采集系统(一)的更多相关文章
- Go项目实战:打造高并发日志采集系统(六)
前情回顾 前文我们完成了日志采集系统的日志文件监控,配置文件热更新,协程异常检测和保活机制. 本节目标 本节加入kafka消息队列,kafka前文也介绍过了,可以对消息进行排队,解耦合和流量控制的作用 ...
- Go项目实战:打造高并发日志采集系统(二)
日志统计系统的整体思路就是监控各个文件夹下的日志,实时获取日志写入内容并写入kafka队列,写入kafka队列可以在高并发时排队,而且达到了逻辑解耦合的目的.然后从kafka队列中读出数据,根据实际需 ...
- Go项目实战:打造高并发日志采集系统(三)
前文中已经完成了文件的监控,kafka信息读写,今天主要完成配置文件的读写以及热更新.并且规划一下系统的整体结构,然后将之前的功能串起来形成一套完整的日志采集系统. 前情提要 上一节我们完成了如下目标 ...
- Go项目实战:打造高并发日志采集系统(四)
前情回顾 前文我们完成了如下目标1 项目架构整体编写2 使框架支持热更新 本节目标 在前文的框架基础上,我们1 将之前实现的日志监控功能整合到框架中.2 一个日志对应一个监控协程,当配置热更新后根据新 ...
- Go项目实战:打造高并发日志采集系统(五)
前情回顾 前文我们完成了如下功能1 根据配置文件启动多个协程监控日志,并启动协程监听配置文件.2 根据配置文件热更新,动态协调日志监控.3 编写测试代码,向文件中不断写入日志并备份日志,验证系统健壮性 ...
- 《实战java高并发程序设计》源码整理及读书笔记
日常啰嗦 不要被标题吓到,虽然书籍是<实战java高并发程序设计>,但是这篇文章不会讲高并发.线程安全.锁啊这些比较恼人的知识点,甚至都不会谈相关的技术,只是写一写本人的一点读书感受,顺便 ...
- 《实战Java高并发程序设计》读书笔记
文章目录 第二章 Java并行程序基础 2.1 线程的基本操作 2.1.1 线程中断 2.1.2 等待(wait)和通知(notify) 2.1.3 等待线程结束(join)和谦让(yield) 2. ...
- 【实战Java高并发程序设计 7】让线程之间互相帮助--SynchronousQueue的实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
- 【实战Java高并发程序设计6】挑战无锁算法:无锁的Vector实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
随机推荐
- ak-1
最近研究ak,网上也有很多这方面的资料,就不重复叙述了,本次记录就是自己在做适应时的一些记录. 本次环境 中标麒麟 金蝶apusic 人大金仓 先说说东西从哪下载怎么来的 基本都是通过官网打电话申请 ...
- JS用正则替换特殊字符
'abcabce'.replace(/abc/g,'') "e" 'abcabce$E$'.replace(/$E$/g,'') "abcabce$E$" 'a ...
- C语言之const
鱼鹰 鱼鹰谈单片机 2月19日 预计阅读时间: 5 分钟 我们知道,数据分为两种,一种为只读,一种为可读可写,为了防止一些不变的数据被程序意外的修改,有必要对它进行保护.这就是 const 的作用. ...
- API接口防止参数篡改和重放攻击
{近期领导要求我对公司业务的支付类的ocr接口做研究,是否存在支付接口重放攻击,so.....} API重放攻击(Replay Attacks)又称重播攻击.回放攻击.他的原理就是把之前窃听到的数据原 ...
- Bootstrap Popover(弹出框)弹出自定义格式代码
HEAD 标签之间引入CSS:<link href="../../../public/css/bootstrap.min.css" rel="stylesheet& ...
- SSM框架初始配置
1 web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="h ...
- Comet OJ - Contest #11 B 背包dp
Code: #include <bits/stdc++.h> #define N 1005 #define M 2000 #define setIO(s) freopen(s". ...
- NetMQ介绍
NetMQ 是 ZeroMQ的C#移植版本. 一.ZeroMQ ZeroMQ(Ø)是一个轻量级的消息内核,它是对标准socket接口的扩展.它提供了一种异步消息队列,多消息模式,消息过滤(订阅),对 ...
- Python 爬取喜马拉雅音频
一.分析音频下载相关链接地址 1. 分析专辑音频列表页面 在 PC端用 Chrome 浏览器中打开 喜马拉雅 网站,打开 Chrome开发者工具,随意打开一个音频专辑页面,Chrome开发者工具中 ...
- jQuery动画之显示隐藏动画
1. 显示动画 以下面一个代码示例: <!doctype html> <html lang="en"> <head> <meta char ...