mysql innodb索引原理
聚集索引(clustered index)
innodb存储引擎表是索引组织表,表中数据按照主键顺序存放。其聚集索引就是按照每张表的主键顺序构造一颗B+树,其叶子结点中存放的就是整张表的行记录数据,这些叶子节点成为数据页。
聚集索引的存储并不是物理上连续的,而是逻辑上连续的,叶子结点间按照主键顺序排序,通过双向链表连接。多数情况下,查询优化器倾向于采用聚集索引,因为聚集索引能在叶子结点直接找到数据,并且因为定义了数据的逻辑顺序,能特别快的访问针对范围值的查询。
聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。由于表里的数据只能按照一颗B+树排序,因此一张表只能有一个聚簇索引。
在Innodb中,聚簇索引默认就是主键索引。如果没有主键,则按照下列规则来建聚簇索引:
- 没有主键时,会用一个非空并且唯一的索引列做为主键,成为此表的聚簇索引;
- 如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。
由于主键使用了聚簇索引,如果主键是自增id,那么对应的数据也会相邻地存放在磁盘上,写入性能较高。如果是uuid等字符串形式,频繁的插入会使innodb频繁地移动磁盘块,写入性能就比较低了。
B+树(多路平衡查找树)
我们知道了innodb引擎索引使用了B+树结构,那么为什么不是其他类型树结构,例如二叉树呢?
计算机在存储数据的时候,有最小存储单元,这就好比人民币流通最小单位是分一样。文件系统的最小单元是块,一个块的大小是4k(这个值根据系统不同并且可设置),InnoDB存储引擎也有自己的最小储存单元—页(Page),一个页的大小是16K(这个值也是可设置的)。
文件系统中一个文件大小只有1个字节,但不得不占磁盘上4KB的空间。同理,innodb的所有数据文件的大小始终都是16384(16k)的整数倍。
所以在MySQL中,存放索引的一个块节点占16k,mysql每次IO操作会利用系统的预读能力一次加载16K。这样,如果这一个节点只放1个索引值是非常浪费的,因为一次IO只能获取一个索引值,所以不能使用二叉树。
B+树是多路查找树,一个节点能放n个值,n = 16K / 每个索引值的大小。
例如索引字段大小1Kb,这时候每个节点能放的索引值理论上是16个,这种情况下,二叉树一次IO只能加载一个索引值,而B+树则能加载16个。
B+树的路数为n+1,n是每个节点存在的值数量,例如每个节点存放16个值,那么这棵树就是17路。
从这里也能看出,B+树节点可存储多个值,所以B+树索引并不能找到一个给定键值的具体行。B+树只能找到存放数据行的具体页,然后把页读入到内存中,再在内存中查找指定的数据。
附:B树和B+树的区别在于,B+树的非叶子结点只包含导航信息,不包含实际的值,所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。
辅助索引
也称为非聚集索引,其叶子节点不包含行记录的全部数据,叶子结点除了包含键值以外,每个叶子结点中的索引行还包含一个书签,该书签就是相应行的聚集索引键。
如下图可以表示辅助索引和聚集索引的关系(图片源自网络,看大概意思即可):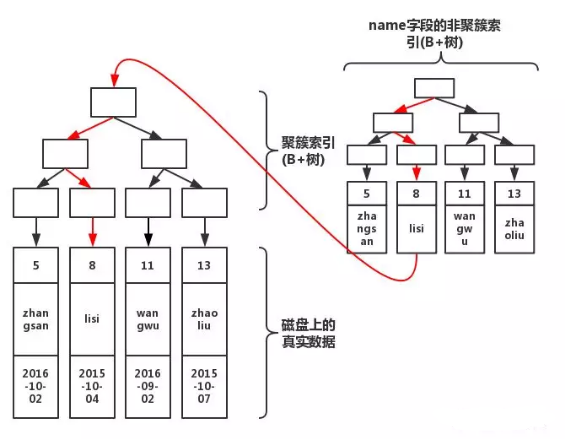
当通过辅助索引来寻找数据时,innodb存储引擎会通过辅助索引叶子节点获得只想主键索引的主键,既然后再通过主键索引找到完整的行记录。
例如在一棵高度为3的辅助索引树中查找数据,那需要对这颗辅助索引树进行3次IO找到指定主键,如果聚集索引树的高度同样为3,那么还需要对聚集索引树进行3次查找,最终找到一个完整的行数据所在的页,因此一共需要6次IO访问来得到最终的数据页。
创建的索引,如联合索引、唯一索引等,都属于非聚簇索引。
联合索引
联合索引是指对表上的多个列进行索引。联合索引也是一颗B+树,不同的是联合索引的键值数量不是1,而是大于等于2。
例如有user表,字段为id,age,name,现发现如下两条sql使用频率最多:
Select * from user where age = ? ;
Select * from user where age = ? and name = ?;这时候不需要为age和name单独建两个索引,只需要建如下一个联合索引即可:
create index idx_age_name on user(age, name)联合索引的另一个好处已经对第二个键值进行了排序处理,有时候可以避免多一次的排序操作。
覆盖索引
覆盖索引,即从辅助索引中就可以得到查询所需要的所有字段值,而不需要查询聚集索引中的记录。覆盖索引的好处是辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量的IO操作。
例如上面有联合索引(age,name),如果如下:
select age,name from user where age=?就能使用覆盖索引了。
覆盖索引的另一个好处是对于统计问题,例如:
select count(*) from userinnodb存储引擎并不会选择通过查询聚集索引来进行统计。由于user表上还有辅助索引,而辅助索引远小于聚集索引,选择辅助索引可以减少IO操作。
如果对于name列做了索引,那么:
select id,name from user也会使用覆盖索引,因为name在索引上,而id(主键)在其索引树的子节点上保存。
注意事项
- 索引只建合适的,不建多余的
因为每当增删数据时,B+树都要进行调整,如果建立多个索引,多个B+树都要进行调整,而树越多、结构越庞大,这个调整越是耗时耗资源。如果减少了这些不必要的索引,磁盘的使用率可能会大大降低。- 索引列的数据长度能少则少。
索引数据长度越小,每个块中存储的索引数量越多,一次IO获取的值更多。- 匹配列前缀可用到索引 like 9999%,like %9999%、like %9999用不到索引;
- Where 条件中in和or可以使用索引, not in 和 <>操作无法使用索引;
如果是not in或<>,面对B+树,引擎根本不知道应该从哪个节点入手。- 匹配范围值,order by 也可用到索引;
- 多用指定列查询,只返回自己想到的数据列,少用select *;
不需要查询无用字段,并且不使用*可能还会命中覆盖索引哦;- 联合索引中如果不是按照索引最左列开始查找,无法使用索引;
最左匹配原则;- 联合索引中精确匹配最左前列并范围匹配另外一列可以用到索引;
- 联合索引中如果查询中有某个列的范围查询,则其右边的所有列都无法使用索
- 查询优化器不一定会使用索引
在执行SQL时,查询优化器会判断使用索引的效率问题,如果优化器认为使用索引还不如全表扫描高效,那么就会弃用索引而使用全表扫描。- 必须使用UTF8MB4字符集
万国码,无需转码,无乱码风险,曾经线上Oracle曾经因为生僻字改字符集UTF-8,烦的一笔。- 禁止使用存储过程、视图、触发器、Event
解放数据库CPU,将计算转移到服务层,并发量大时这些功能很可能将数据库拖死,业务逻辑放到服务层具备更好的扩展性,能够轻易实现“增机器就加性能”。数据库擅长存储与索引,CPU计算还是上移吧- 禁止存储大文件或者大照片
- 禁止使用外键,如果有外键完整性约束,需要应用程序控制
外键会导致表与表之间耦合,update与delete操作都会涉及相关联的表,十分影响sql 的性能,甚至会造成死锁。高并发情况下容易造成数据库性能- 必须把字段定义为NOT NULL并且提供默认值
a)null的列使索引/索引统计/值比较都更加复杂,对MySQL来说更难优化
b)null 这种类型MySQL内部需要进行特殊处理,增加数据库处理记录的复杂性;同等条件下,表中有较多空字段的时候,数据库的处理性能会降低很多
c)null值需要更多的存储空,无论是表还是索引中每行中的null的列都需要额外的空间来标识
d)对null 的处理时候,只能采用is null或is not null,而不能采用=、in、<、<>、!=、not in这些操作符号。如:where name!=’shenjian’,如果存在name为null值的记录,查询结果就不会包含name为null值的记录- 禁止使用TEXT、BLOB类型
会浪费更多的磁盘和内存空间,非必要的大量的大字段查询会淘汰掉热数据,导致内存命中率急剧降低,影响数据库性能- 禁止使用ENUM,可使用TINYINT代替
a)增加新的ENUM值要做DDL操作
b)ENUM的内部实际存储就是整数,你以为自己定义的是字符串?- 禁止在更新十分频繁、区分度不高的属性上建立索引
a)更新会变更B+树,更新频繁的字段建立索引会大大降低数据库性能
b)“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似- 建立组合索引,必须把区分度高的字段放在前面
能够更加有效的过滤数据- 禁止使用SELECT *,只获取必要的字段,需要显示说明列属性
读取不需要的列会增加CPU、IO消耗;不能有效的利用覆盖索引- 禁止使用属性隐式转换
SELECT uid FROM t_user WHERE phone=13812345678 会导致全表扫描,而不能命中phone索引- 禁止在WHERE条件的属性上使用函数或者表达式
SELECT uid FROM t_user WHERE from_unixtime(day)>='2017-02-15' 会导致全表扫描
正确的写法是:SELECT uid FROM t_user WHERE day>= unix_timestamp('2017-02-15 00:00:00')- 禁止负向查询,以及%开头的模糊查询
a)负向查询条件:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,会导致全表扫描
b)%开头的模糊查询,会导致全表扫描- 禁止大表使用JOIN查询,禁止大表使用子查询
会产生临时表,消耗较多内存与CPU,极大影响数据库性能。这个视业务而定- 禁止使用OR条件,必须改为IN查询
旧版本Mysql的OR查询是不能命中索引的,即使能命中索引,为何要让数据库耗费更多的CPU帮助实施查询优化呢?mysql innodb索引原理的更多相关文章
- MySQL InnoDB 索引原理
本文由 网易云发布. 作者:范鹏程,网易考拉海购 InnoDB是 MySQL最常用的存储引擎,了解InnoDB存储引擎的索引对于日常工作有很大的益处,索引的存在便是为了加速数据库行记录的检索.以下是 ...
- MySQL系列(九)--InnoDB索引原理
InnoDB在MySQL5.6版本后作为默认存储引擎,也是我们大部分场景要使用的,而InnoDB索引通过B+树实现,叫做B-tree索引.我们默认创建的 索引就是B-tree索引,所以理解B-tree ...
- 数据库MySQL 之 索引原理与慢查询优化
数据库MySQL 之 索引原理与慢查询优化 浏览目录 索引介绍方法类型 聚合索引辅助索引 测试索引 正确使用索引 组合索引 注意事项 查询计划 慢查询日志 大数据量分页优化 一.索引介绍方法类型 1. ...
- 十、mysql之索引原理与慢查询优化
mysql之索引原理与慢查询优化 一.介绍 1.什么是索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还 ...
- 0614MySQL的InnoDB索引原理详解
转自http://www.cnblogs.com/shijingxiang/articles/4743324.html MySQL的InnoDB索引原理详解 http://www.admin10000 ...
- InnoDB 索引原理
InnoDB索引原理 索引能够提高访问的速率 B+树索引(最为常用和最为有效).全文索引.哈希索引. 数据库中的B+树索引可以分为聚集索引和辅助索引,但是不管是聚集还是辅助的索引,其内部都是B+树,是 ...
- MySQL InnoDB 索引 (INDEX) 页结构
MySQL InnoDB 索引 (INDEX) 页结构 InnoDB 为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做索引页 索引页内容 索引页分为以下部分: File Header:表 ...
- MYSQL:基础——索引原理及慢查询优化
MYSQL:基础——索引原理及慢查询优化 索引的数据结构 索引的数据结构是B+树.如下图所示,B+树的节点通常被表示为一组有序的数据项和子指针.图中第一个节点包含数据项3和5,包含三个指针,第一个指针 ...
- MySQL的InnoDB索引原理详解
摘要 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本篇 ...
随机推荐
- 编码问题2 utf-8和Unicode的区别
utf-8和Unicode到底有什么区别?是存储方式不同?编码方式不同?它们看起来似乎很相似,但是实际上他们并不是同一个层次的概念 要想先讲清楚他们的区别,首先应该讲讲Unicode的来由. 众所周知 ...
- PHP mysqli_free_result() 函数
mysqli_free_result() 函数释放结果内存. <?php // 假定数据库用户名:root,密码:123456,数据库:RUNOOB $con=mysqli_connect(&q ...
- Mybatis源码学习之日志(五)
简述 在Java开发中常用的日志框架有Log4j.Log4j2.Apache Commons Log.java.util.logging.slf4j等,这些工具对外的接口并不相同.为了统一这些工具的接 ...
- dapper通用分页方法
/// <summary> /// dapper通用分页方法 /// </summary> /// <typeparam name="T">泛型 ...
- Liferay使用Structure和Template制作Video Portlet
Liferay提供Structure和Teamplate机制,Structure定义以如何引入内容,Teamplate定义怎样展现内容,能快速为页面添加新内容展示. FlowPlayer是一款开源的W ...
- spring boot通过自定义注解和AOP拦截指定的请求
一 准备工作 1.1 添加依赖 通过spring boot创建好工程后,添加如下依赖,不然工程中无法使用切面的注解,就无法对制定的方法进行拦截 <dependency> <group ...
- vue 无法覆盖vant的UI组件的样式
vue 无法覆盖vant的UI组件的样式 有时候UI组件提供的默认的样式不能满足项目的需要,就需要我们对它的样式进行修改,但是发现加了scoped后修改的样式不起作用. 解决方法: 使用深度选择器,将 ...
- legend3---7、videojs的使用配置的启示是什么
legend3---7.videojs的使用配置的启示是什么 一.总结 一句话总结: 很多东西网上都有现成的,直接拿来用就好,效果是又快又好 1.用auth认证登录的时候报 "validat ...
- [MySql]MySql中外键设置 以及Java/MyBatis程序对存在外键关联无法删除的规避
在MySql设定两张表,其中product表的主键设定成orderTb表的外键,具体如下: 产品表: create table product(id INT(11) PRIMARY KEY,name ...
- 前端知识点回顾之重点篇——JavaScript异步机制
JavaScript异步机制 来源:https://www.cnblogs.com/zhaodongyu/p/3922961.html JavaScript是单线程异步执行的,单线程意味着代码在任务队 ...