1.Hbase集群安装配置(一主三从)
1.HBase安装配置,使用独立zookeeper,shell测试
安装步骤:首先在Master(shizhan2)上安装:前提必须保证hadoop集群和zookeeper集群是可用的
1.上传:用工具将hbase安装包hbase-0.99.2-bin.tar.gz上传到:/data/software/目录下
2.解压:tar -xzvf hbase-0.99.2-bin.tar.gz -C /usr/local/src/
3.重命名:mv hbase-0.99.2 hbase
4.修改环境变量:在master机器上执行:vi /etc/profile,添加如下内容:
export HBASE_HOME=/usr/local/src/hbase
export PATH=$PATH:$HBASE_HOME/bin
5.修改配置文件:
vi /hbase/conf/hbase-site.xml
<configuration>
<property>
#hbasemaster的主机和端口
<name>hbase.master</name>
<value>shizhan2:60000</value>
</property>
<property>
#时间同步允许的时间差
<name>hbase.master.maxclockskew</name>
<value>180000</value>
</property>
<property>
#共享目录,持久化hbase数据
<name>hbase.rootdir</name>
<value>hdfs://shizhan2:9000/hbase</value>
</property>
<property>
#是否分布式运行,false即为单机
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
#zookeeper地址
<name>hbase.zookeeper.quorum</name>
<value>shizhan3,shizhan5,shizhan6</value>
</property>
<property>
#zookeeper配置信息快照的位置,zookeeper 保持信息的文件,默认为/tmp 重启会丢失
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/hbase/tmp/zookeeper</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2183</value>
</property>
</configuration>
vi /hbase/conf/hbase-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_45 //jdk安装目录
export HBASE_CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar //hadoop配置文件的位置
export HBASE_MANAGES_ZK=false #如果使用独立安装的zookeeper这个地方就是false,自带的设置为true
vi /conf/regionservers
shizhan3
shizhan5
shizhan6
6.将Hadoop的hdfs-site.xml和core-site.xml 放到hbase/conf下:
hdfs-site.xml:
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://shizhan2:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.6.4/hdpdata</value>
</property>
</configuration>
7.修Hanase安装包发送到其他机器:
scp –r /usr/local/src/hbase shizhan3:/usr/local/src/
scp –r /usr/local/src/hbase shizhan5:/usr/local/src/
scp –r /usr/local/src/hbase shizhan6:/usr/local/src/
8.启动:cd /usr/local/src/hbase/bin/ ./start-hbase.sh
9.查看:http://shizhan2:16010/,使用jps查看:


Hbase动态增删主备节点:
注意:以上安装是shizhan2作为主节点,shizhan3、shizhan5、shizhan6作为从节点(一主三从)
1.如下为Habase的多Master配置方案(添加双主Master):在任意安装了Hbase的机器上启动Master:
local-master-backup.sh start 2
2.添加Hbase节点:先拷贝一个从节点到其他机器上,然后启动
hbase-daemon.sh start regionserver
注意:动态添加、删除Hbase节点(HMaster、HRegionServer)是由Zookeeper控制的,例如:
:启动双主HMaster节点:在shizhan3上通过命令启动:
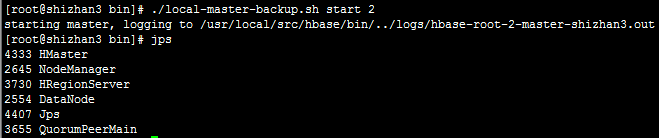
通过连接Zookeeper客户端连接Zookeeper服务查看节点:zkCli.sh -server shizhan2:2183
查看在shihan3上启动的双主节点HMaster备用节点信息:


此时如若将杀掉的从节点shizhan6重新启动:bin/hbase-daemon.sh start regionserver(动态增加节点)

可以看出节点被重新添加
在Hadoop+Zookeeper+Hbase集群中:
1.首先启动hadoop集群;
2.启动zookeeper集群服务:因为在Hbase中提供了HBASE_MANAGES_ZK变量来设置是否管理zookeeper集群,默认情况,
HBASE_MANAGES_ZK设置为true(Hbase自带),即告诉Hbase把zookeeper启动、停止作为Hbase启动、停止的一部分,如果要
设置为独立的Zookeeper集群管理(不是由HBase管理的集群),则将hbase-env.sh中的HBASE_MANAGES_ZK设置为false,如
果是独立启动zookeeper集群,那么这里的clientPort必须与zookeeper配置的一致,否则客户端连接的时候会报错(所以先
启动zookeeper集群,服务端口号设置的为2183,即可通过shizhan5/192.168.232.207:2183去连接)
3.启动Hbase集群;
1.Hbase集群安装配置(一主三从)的更多相关文章
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- hbase和ZooKeeper集群安装配置
一:ZooKeeper集群安装配置 1:解压zookeeper-3.3.2.tar.gz并重命名为zookeeper. 2:进入~/zookeeper/conf目录: 拷贝zoo_sample.cfg ...
- hbase单机及集群安装配置,整合到hadoop
问题导读:1.配置的是谁的目录conf/hbase-site.xml,如何配置hbase.rootdir2.如何启动hbase?3.如何进入hbase shell?4.ssh如何达到互通?5.不安装N ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- RabbitMQ集群安装配置+HAproxy+Keepalived高可用
RabbitMQ集群安装配置+HAproxy+Keepalived高可用 转自:https://www.linuxidc.com/Linux/2016-10/136492.htm rabbitmq 集 ...
- redis cluster 集群 安装 配置 详解
redis cluster 集群 安装 配置 详解 张映 发表于 2015-05-01 分类目录: nosql 标签:cluster, redis, 安装, 配置, 集群 Redis 集群是一个提供在 ...
- Hbase集群安装Version1.1.5
Hbase集群安装,基于版本1.1.5, 使用hbase-1.1.5.tar.gz安装包. 1.安装说明 使用外部Zookeeper集群而非Hbase自带zookeeper, 使用Hadoop文件系统 ...
- CentOS下Hadoop-2.2.0集群安装配置
对于一个刚开始学习Spark的人来说,当然首先需要把环境搭建好,再跑几个例子,目前比较流行的部署是Spark On Yarn,作为新手,我觉得有必要走一遍Hadoop的集群安装配置,而不仅仅停留在本地 ...
- hive集群安装配置
hive 是JAVA写的的一个数据仓库,依赖hadoop.没有安装hadoop的,请参考http://blog.csdn.net/lovemelovemycode/article/details/91 ...
随机推荐
- Robot:robot如何连接Oracle数据库(windows+linux)
1.需要安装基础数据库 pip install robotframework-databaselibrary 2.下载并安装对应版本的cx_Oracle,注意要和Oracle版本.系统位数.pytho ...
- sed练习,一些sed常用方法
1.复制/etc/rc.d/rc.local 文件至/tmp目录,将/tmp/rc.sysinit文件中的以至少一个空白字符开头的行的行首加#. sed -ri 's/^ +/#/g' rc.loc ...
- Docker容器中用户权限管理
在Linux系统中有一部分知识非常重要,就是关于权限的管理控制:Linux系统的权限管理是由uid和gid负责,Linux系统会检查创建进程的uid和gid,以确定它是否有足够的权限修改文件,而非是通 ...
- 高级UI-Snackbar
在与用户的交互中,最为常用的Toast和Dialog,但二者都存在其局限,Toast无法与用户进行交互,Dialog虽然可以与用户交互,但却会阻断用户操作的连贯性,介于二者之间的平衡,Snackbar ...
- vue {{}}的用法
参考链接:https://blog.csdn.net/cofecode/article/details/78666233
- SQL-锁-事物级别
一.锁 锁是一种安全机制,控制并发操作,防止用户读取其他用户正在更改的数据,或者多用户同时修改一个数据,从而保证事物的完整性和数据库的一致性.SQLserver 会自动强制执行锁,但是用户可以通过对锁 ...
- 第6章:LeetCode--数组(冒泡排序、快速排序)
11. Container With Most Water class Solution { public: int maxArea(vector<int>& height) { ...
- bs4解析
介绍:将一个html文档转换成BeautifulSoup对象,然后通过对象的方法或属性查找指定的节点内容 转换本地文件: soup = BeautifulSoup(fp,'lxml') fp为文档 ...
- 在订单服务中使用Hystrix进行熔断设置
使用Hystrix熔断(上) 在一个分布式系统里,一个服务依赖多个服务,可能存在某个服务调用失败, 比如超时.异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败, ...
- python学习-24 局部变量与全局变量
局部变量与全局变量 1.没有缩进的变量,为全局变量 name = 'jphn' 在子程序里定义的变量,局部变量 2. name = 'jphn' #全局变量 def a(): name='andy' ...