目标检测之R-FCN
R-FCN:Object Detection via Region-based Fully Convolutional Networks
R-FCN的网络结构
一个Base的convolutional网络如RestNet101,一个RPN(Faster RCNN来的),一个Postition Sensitive的prediction层,最后的RoI pooling+ 投票的决策层
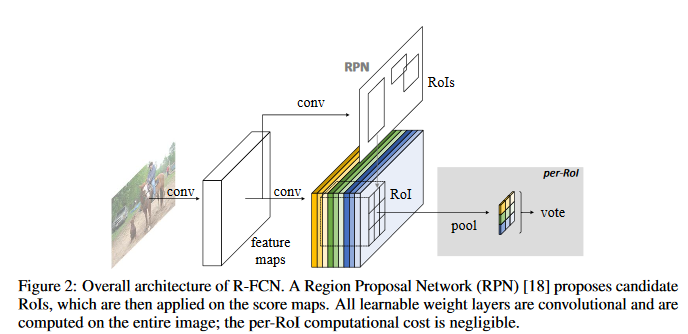
R-FCN的关键思想
- 分类需要特征具有平移不变性,检测则要求对目标的平移做出准确的相应。现在大部分CNN在分类上可以做的很好,但用在检测上效果不佳。SPP,Faster R-CNN类的方法在ROI Pooling前都是卷积,是具备平移不变性的,但一旦插入RoI pooling之后,后面的网络结构就不再具备平移不变性了。因此本文提出postition sensitive score map,这个概念是能把目标的位置信息融合进ROI pooling
- 对于region-based的检测方法,以Faster R-CNN为例,实际上分成了几个subnetwork,第一个subnetwork用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast R-CNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork中间的就是RoI pooling,希望的是将耗时的卷积都尽量移到前面共享的subnetwork上,因此和Faster R-CNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在前面共享的subnetwork。最后用来prediction卷积只有1层,大大减少了计算量
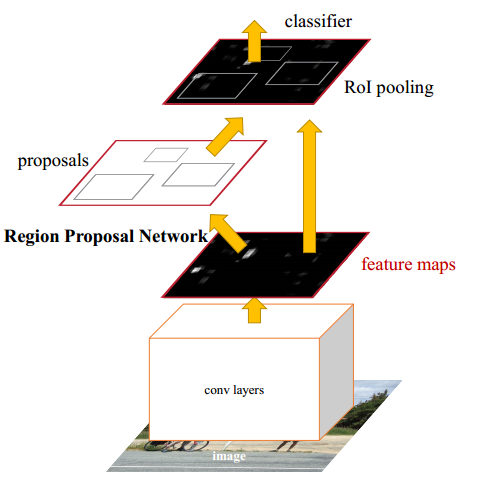
R-CNN,Faster R-CNN,R-FCN共享的卷积子网络深度以及RoI子网络深度对比:

方法细节

- Backbone architecture:ResNet 101——去掉原始ResNet101的最后一层全连接层,保留前100层,再接一个1*1*1024的全卷积层(100层输出的是2048,为了降低维度,再引入一个1*1的卷积层);
- K^2 * 2 (C + 1)的conv:ResNet101的输出是W*H*1024,用K^2(C + 1)个1024*1*1的卷积核去卷积,即可得到K^2(C + 1)个大小为W*H的position sensitive的score map。这步的卷积操作就是在做prediction。K = 3,表示把一个RoI划分成3*3,对应的9个位置分别是上左,上中,上右,中左,中中,中右,下左,下中,下右。
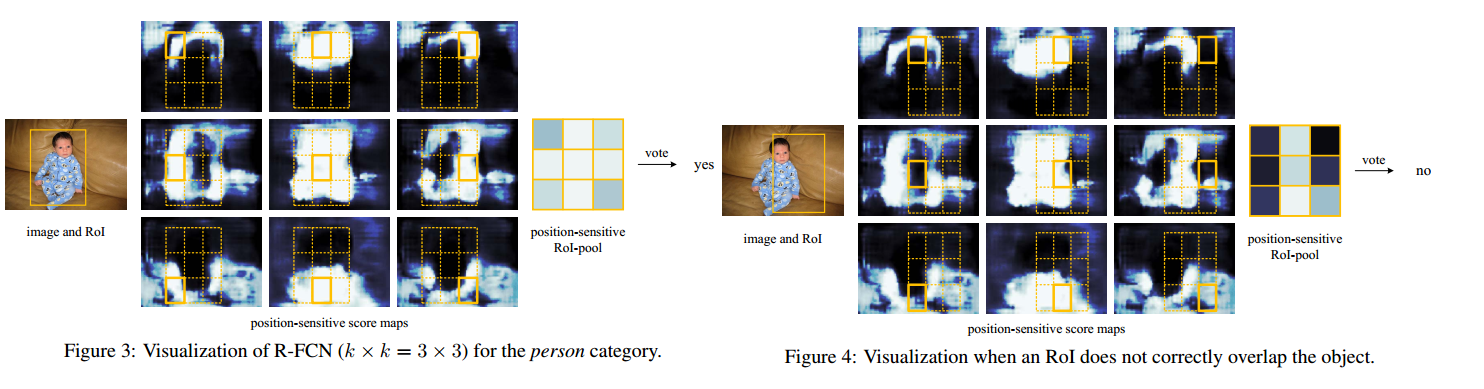
- K^2(C + 1)个feature map的物理意义:共有k*k = 9个颜色,每个颜色的立体块(W*H*(C+1))表示的是不同位置存在目标的概率值。共有K^2*(C + 1)个feature map。每个feature map,z(i,j,c)是第i+k(j - 1)个立体块上的第c个map(1 <=i,j <=3),(i,j)决定了9种位置的某一种位置,假设左上角位置(i=j=1),c决定了哪一类,假设为person类,在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置可能是人(c = ‘presion’)且是人左上部分(i=j=1)的概率值。
- ROI pooling:就是faster RCNN中的ROI pooling,也就是一层的SPP结构。主要用来将不同大小的ROI对应的feature map映射成同样维度的特征,思路是不论多大的ROI,规定在上面画一个n*n个bin的网络,每个网络里所有像素值做一个pooling(平均),这样不论图像多大,pooling后的ROI特征维度都是n*n。注意一点ROI pooling是每个feature map单独做,不是多个channel一起。
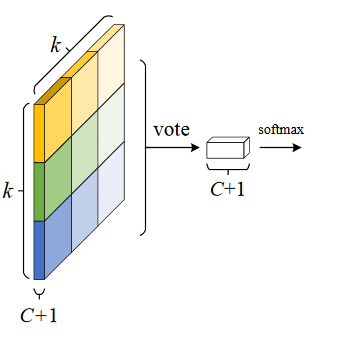
- ROI pooling的输入和输出:ROI pooling操作的输入(对于C+1个类)是K^2*(C + 1)* W' * H' (W',H'是ROI的宽度和高度)的score map上某ROI对应的那个立体块,且该立体块组成一个新的K^2*(C + 1)* W' * H'立体块;每个颜色的立体块(C + 1)都只抠出对应位置的一个bin,把这k*k个bin组成新的立体块,大小为(C + 1)* W’ * H’。例如,下图中第一块黄色只取左上角的bin,最后一块淡蓝色只取右下角的bin,所有的bin重新组合就变成了类似右图的那个薄的立体块(图中的这个是池化后的输出,即每个面上的bin已经是一个像素,池化之前这个bin对应的是一个区域,是多个像素)。ROI pooling的输出为一个(C +1)* k * k的立体块,如下图中的右图:

- vote投票:k*k个bin直接进行求和(每个类单独做)得到每一类的score,并进行softmax得到每类的最终得分,并用于计算损失
- 损失函数:和Faster R-CNN类似,由分类loss和回归loss组成,分类用交叉熵损失(log loss),回归用L1-smooth损失
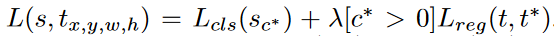
- 训练的样本选择策略:online hard example mining(OHEM)。主要思想就是对样本按loss进行排序,选择前面loss较小的,这个策略主要用来对负样本进行筛选,是的正负样本更加平衡。
- 训练细节:
- decay = 0.0005
- momentum = 0.9
- single-scale training: images are resized such that the scale (shorter side of image) is 600 pixels [6, 18].
- 8 GPUs (so the effective mini-batch size is 8×), each GPU holds 1 image and selects B = 128 RoIs for backprop.
- fine-tune learning rate = 0.001 for 20k mini-batches, 0.0001 for 10k mini-batches on VOC.
- the 4-step alternating training between training RPN and training R-FCN.(类似于Faster RCNN)
- 使用atrous(hole算法)

实验结果
VOC2007和VOC2010上与Faster R-CNN的对比:R-FCN比Faster RCNN好!



深度影响对比:101深度最好!

候选区域选择算法对比:RPN比SS,EB好!

COCO库上与Faster R-CNN的对比:R-FCN比Faster RCNN好!

效果示例:

总结
- R-FCN是在Faster R-CNN的框架上进行改造,第一,把base的VGG16换车了ResNet,第二,把Fast R-CNN换成了先用卷积做prediction,再进行ROI pooling。由于ROI pooling会丢失位置信息,故在pooling前加入位置信息,即指定不同score map是负责检测目标的不同位置。pooling后把不同位置得到的score map进行组合就能复现原来的位置信息。
目标检测之R-FCN的更多相关文章
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet,语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类;目标检测只有两类,目标和非目标,就是在一张图片中找到并用box标注出所有的目标.
from:https://blog.csdn.net/u012931582/article/details/70314859 2017年04月21日 14:54:10 阅读数:4369 前言 在这里, ...
- 目标检测网络之 Mask R-CNN
Mask R-CNN 论文Mask R-CNN(ICCV 2017, Kaiming He,Georgia Gkioxari,Piotr Dollár,Ross Girshick, arXiv:170 ...
- 使用Caffe完成图像目标检测 和 caffe 全卷积网络
一.[用Python学习Caffe]2. 使用Caffe完成图像目标检测 标签: pythoncaffe深度学习目标检测ssd 2017-06-22 22:08 207人阅读 评论(0) 收藏 举报 ...
- 全卷积目标检测:FCOS
全卷积目标检测:FCOS FCOS: Fully Convolutional One-Stage Object Detection 原文链接:https://arxiv.org/abs/1904.01 ...
- GPU端到端目标检测YOLOV3全过程(上)
GPU端到端目标检测YOLOV3全过程(上) Basic Parameters: Video: mp4, webM, avi Picture: jpg, png, gif, bmp Text: doc ...
- 不带Anchors和NMS的目标检测
前言: 目标检测是计算机视觉中的一项传统任务.自2015年以来,人们倾向于使用现代深度学习技术来提高目标检测的性能.虽然模型的准确性越来越高,但模型的复杂性也增加了,主要是由于在训练和NMS后处理过 ...
- 目标检测方法总结(R-CNN系列)
目标检测方法系列--R-CNN, SPP, Fast R-CNN, Faster R-CNN, YOLO, SSD 目录 相关背景 从传统方法到R-CNN 从R-CNN到SPP Fast R-CNN ...
- [目标检测]YOLO原理
1 YOLO 创新点: 端到端训练及推断 + 改革区域建议框式目标检测框架 + 实时目标检测 1.1 创新点 (1) 改革了区域建议框式检测框架: RCNN系列均需要生成建议框,在建议框上进行分类与回 ...
- 目标检测之R-CNN系列
Object Detection,在给定的图像中,找到目标图像的位置,并标注出来. 或者是,图像中有那些目标,目标的位置在那.这个目标,是限定在数据集中包含的目标种类,比如数据集中有两种目标:狗,猫. ...
- 利用更快的r-cnn深度学习进行目标检测
此示例演示如何使用名为“更快r-cnn(具有卷积神经网络的区域)”的深度学习技术来训练对象探测器. 概述 此示例演示如何训练用于检测车辆的更快r-cnn对象探测器.更快的r-nnn [1]是r-cnn ...
随机推荐
- MySQL 错误号码 1449
出现类似的问题是由于权限问题,授权给root所有sql权限即可: mysql> grant all privileges on *.* to root@"%" identif ...
- C#非常规调试场景总结
场景1:类库独立调试. 方法:可以将类库项目修改成控制台程序,然后增加一个静态的main函数的方式来调试 场景2:程序需要连接数据库,本机调试的时候因为权限问题无法连接上数据库,只能 ...
- poj 3246 Balanced Lineup(线段树)
Balanced Lineup Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 38942 Accepted: 18247 ...
- 第一百三十八节,JavaScript,封装库--插件
JavaScript,封装库--插件 库主要是用来封装一般JavaScript的常规操作代码,而拖拽这种特效代码属于功能性代码,并不是必须的,所以这种类型的代码,我们建议另外封装,在需要的时候作为插件 ...
- 【BZOJ】2016: [Usaco2010]Chocolate Eating(二分)
http://www.lydsy.com/JudgeOnline/problem.php?id=2016 这些最大最小显然是二分. 但是二分细节挺多的...这里注意二分的区间,可以累计所有的可能,然后 ...
- Oozie安装与部署
原创文章,转载请注明: 转载自http://www.cnblogs.com/tovin/p/3885162.html 安装基础环境: Hadoop – 2.2.0 Linux – Centos 6. ...
- Chrome 新建自定义标签
刚开始用Chrome让我最不爽的地方有2个: 1.不能双击关闭标签 2.新建的标签不能是自定义网页 第一个问题通过插件解决了,第二个问题今天也总算找到解决的方法了. 这个方法是自定义插件,需要2个文件 ...
- 最近5年133个Java面试问题列表
Java 面试随着时间的改变而改变.在过去的日子里,当你知道 String 和 StringBuilder 的区别就能让你直接进入第二轮面试,但是现在问题变得越来越高级,面试官问的问题也更深入. 在我 ...
- 数据结构 + 算法 -> 收集
董的博客:数据机构与算法合集 背包问题应用(2011-08-26) 数据结构之红黑树(2011-08-20) 素数判定算法(2011-06-26) 算法之图搜索算法(一)(2011-06-22) 算法 ...
- JZOJ.5235【NOIP2017模拟8.7】好的排列
Description 对于一个1->n的排列 ,定义A中的一个位置i是好的,当且仅当Ai-1>Ai 或者Ai+1>Ai.对于一个排列A,假如有不少于k个位置是好的,那么称A是一个好 ...