MapReduce:汇总学生表和成绩表为----学生成绩表
已知两张数据表,其中表一存储的是学生编号、学生姓名;表二存储的是学生编号、考试科目、考试成绩;编写mapreduce程序,汇总两张表数据为一张统一表格。
表一:
A001 zhangsan
A002 lisi
A003 wangwu
A004 zhaoliu
A005 tianqi
表二:
A001 math
A002 math
A003 math
A004 math
A005 math
A001 english
A002 english
A003 english
A004 english
A005 english
A001 computer
A002 computer
A003 computer
A004 computer
A005 computer
正确结果:
执行java程序,打印出part-r-00000中数据:
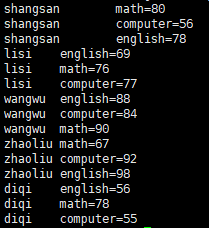
代码如下(由于水平有限,不保证完全正确,如果发现错误欢迎指正):
package com; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration config = new Configuration();
config.set("fs.defaultFS", "hdfs://192.168.0.100:9000");
config.set("yarn.resourcemanager.hostname", "192.168.0.100"); FileSystem fs = FileSystem.get(config); Job job = Job.getInstance(config); job.setJarByClass(Test.class); //设置所用到的map类
job.setMapperClass(myMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class); //设置用到的reduce类
job.setReducerClass(myReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); //设置输入输出地址
FileInputFormat.addInputPath(job, new Path("/day19/")); Path path = new Path("/output5/"); if(fs.exists(path)){
fs.delete(path, true);
} //指定文件的输出地址
FileOutputFormat.setOutputPath(job, path); //启动处理任务job
boolean completion = job.waitForCompletion(true);
if(completion){
System.out.println("Job Success!");
}
} public static class myMapper extends Mapper<Object, Text, Text, Text> { // 实现map函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String temp=new String();// 左右表标识
String values=value.toString();
String words[]=values.split("\t"); String mapkey = new String();
String mapvalue = new String(); //左表:A001,zhangsan
if (words.length==) {
mapkey = words[];
mapvalue =words[];
temp = ""; }else{
//右表:A001,math,80
mapkey = words[];
mapvalue =words[]+"="+words[];
temp = "";
} // 输出左右表
//左表:(A001,1+zhangsan)
//右表:(A001,2+math=80)
context.write(new Text(mapkey), new Text(temp + "+"+ mapvalue));
System.out.println("key:"+mapkey+"---value:"+mapvalue);
}
} //reduce解析map输出,将value中数据按照左右表分别保存
public static class myReducer extends Reducer<Text, Text, Text, Text> {
// 实现reduce函数
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //学生的数组
List<String> people =new ArrayList<String>(); //成绩的数组
List<String> score =new ArrayList<String>(); //(A001,{1+zhangsan,2+math=80})
for(Text value:values){
// 取得左右表标识
char temp = (char) value.charAt(); //
String words[] = value.toString().split("[+]"); //1,zhangsan
if(temp == ''){
people.add(words[]);
} if(temp == ''){
score.add(words[]);
}
} //遍历两次,求出笛卡尔积
for (String p : people) {
for (String s : score) {
context.write(new Text(p), new Text(s));
}
}
}
}
}
如果您认为这篇文章还不错或者有所收获,您可以通过右边的“打赏”功能 打赏我一杯咖啡【物质支持】,也可以点击下方的【好文要顶】按钮【精神支持】,因为这两种支持都是使我继续写作、分享的最大动力!
MapReduce:汇总学生表和成绩表为----学生成绩表的更多相关文章
- java例题_50 题目:有五个学生,每个学生有 3 门课的成绩,从键盘输入以上数据(包括学生号,姓名,三门课成 绩),计算出平均成绩,将原有的数据和计算出的平均分数存放在磁盘文件"stud"中。
1 /*50 [程序 50 文件 IO] 2 题目:有五个学生,每个学生有 3 门课的成绩,从键盘输入以上数据(包括学生号,姓名,三门课成 3 绩),计算出平均成绩,将原有的数据和计算出的平均分数存放 ...
- 《MySQL数据操作与查询》- 维护学生信息、老师信息和成绩信息 支持按多种条件组合查询学生信息和成绩信息
综合项目需求 一.系统整体功能 系统需支持以下功能: 维护学生信息.老师信息和成绩信息 支持按多种条件组合查询学生信息和成绩信息 学生 Student(id,班级id,学号,姓名,性别,电话,地址,出 ...
- Java基础知识强化之集合框架笔记49:键盘录入5个学生信息(姓名,语文成绩,数学成绩,英语成绩)按照总分从高到低输出到控制台
1. 键盘录入5个学生信息(姓名,语文成绩,数学成绩,英语成绩)按照总分从高到低输出到控制台: 分析: A: 定义学生类 B: 创建一个TreeSet集合 C: 总分从高到底如何实现 ...
- /* * 有五个学生,每个学生有3门课的成绩,从键盘输入以上数据 *(包括学生号,姓名,三门课成绩),计算出平均成绩, *将原有的数据和计算出的平均分数存放在磁盘文件"stud"中。 */
1.Student类:类中有五个变量,分别是学号,姓名,三门成绩 package test3; public class Student { private int num; private Stri ...
- 代码实现:有五个学生,每个学生有3门课的成绩,从键盘输入以上数据 (包括学生号,姓名,三门课成绩),计算出平均成绩,将原有的数据和计算出的平均分数存放在磁盘文件"stud"中。
import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; import java.ut ...
- 【HIVE高级笔试必备题型】(组内topN、相邻行的值比较问题)求语文大于数学_/_求文科大于理科成绩的学生
Hive SQL练习之成绩分析 数据:[id, 学号,班级,科目,成绩] 1,1,1,yuwen,80 2,1,1,shuxue,85 3,2,1,yuwen,75 4,2,1,shuxue,70 5 ...
- Mybatis高级:Mybatis注解开发单表操作,Mybatis注解开发多表操作,构建sql语句,综合案例学生管理系统使用接口注解方式优化
知识点梳理 课堂讲义 一.Mybatis注解开发单表操作 *** 1.1 MyBatis的常用注解 之前我们在Mapper映射文件中编写的sql语句已经各种配置,其实是比较麻烦的 而这几年来注解开发越 ...
- 【JAVA】【作业向】第一题:本学期一班级有n名学生,m门课程。现要求对每门课程的成绩进行统计:平均成绩、最高成绩、最低成绩,并统计考试成绩的分布律。
1.预备知识:动态数组Array实现: 2.解题过程需要理解的知识:吧唧吧唧吧唧吧唧 不想做了 就用了最简单的方法 和c语言类似 java版本 `import java.util.Scanner; / ...
- Java初学者作业——编写Java程序,输入一个学生的5门课程的成绩,求其平均分。
返回本章节 返回作业目录 需求说明: 编写Java程序,输入一个学生的5门课程的成绩,求其平均分.计算平均成绩,需要将每一门课程的成绩逐步累加到总成绩中,使用 for 循环实现,然后求出平均分. 实现 ...
随机推荐
- Web API中的模型验证Model Validation
数据注释 在ASP.NET Web API中,您可以使用System.ComponentModel.DataAnnotations命名空间中的属性为模型上的属性设置验证规则. using System ...
- Spring框架中的AOP技术----注解方式
利用AOP技术注解的方式对功能进行增强 CustomerDao接口 package com.alphajuns.demo1; public interface CustomerDao { public ...
- ios在数字键盘左下角添加“完成”按钮的实现原理
本文转载至 http://www.itnose.net/detail/6145865.html 最近要在系统弹出的数字键盘上的左下角额外添加一个自定制的完成按钮,于是研究了一下系统自带键盘添加自定制按 ...
- c++ new(不断跟新)
1.基础知识 /* 可以定义大小是0的数组,但不能引用,因为没有指向任何对象 new string[10]调用类的默认构造函数 new int[10]没有初始化,但new int[10]()会将数组初 ...
- Appcompat实现Action Bar的兼容性处理
Appcompat实现Action Bar时,如果使用到split action bar或者Navigating Up with the App Icon需要考虑兼容性.下面介绍下split acti ...
- hdu5861(Road)
题目链接:传送门 题目大意:有n个点 组成n-1段,每一段开着的时候都有花费Vi,有m组要求,对于每组要求 [x,y]之间可达,对于每一段你有一次开关的机会(最初都是关闭的) 问怎样安排段落得开闭时间 ...
- iOS 计算某个月的天数 计算某天的星期
// 某年某月的天数 - (NSInteger)dayCount:(NSInteger)years { NSInteger count = ; ; i <= ; i++) { == i) { = ...
- RPC远程过程调用概念及实现
RPC框架学习笔记 >>什么是RPC RPC 的全称是 Remote Procedure Call 是一种进程间通信方式. 它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过 ...
- 『浅入浅出』MySQL 和 InnoDB
作为一名开发人员,在日常的工作中会难以避免地接触到数据库,无论是基于文件的 sqlite 还是工程上使用非常广泛的 MySQL.PostgreSQL,但是一直以来也没有对数据库有一个非常清晰并且成体系 ...
- swift UITextField
var textField = UITextField(frame: CGRectMake(10,160,200,30)) //设置边框样式为圆角矩形 textField.borderStyle = ...