第三章——供机器读取的数据(XML)
本书使用的文件、代码:https://github.com/huangtao36/data_wrangling
第三章使用的数据文件:
XML数据

XML中有两个位置可以保存数据:
1、两个标签之间:<Display>71</Display>
2、标签的属性:<Dim Category="SEX" Code="BTSX"/>——其中Category的属性值是“SEX”,Code的属性值是"BTSX"。
XML的属性可以保存特定标签的额外信息,这些标签又嵌套在另一个标签中。
实现代码(基于Python3)
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == 'Numeric':
rec_key = 'NUMERIC'
rec_value = item.attrib['Numeric']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib['Code']
record[rec_key] = rec_value
all_data.append(record)
print (all_data)
输出(部分):

(输出的是单行数据,为了直观,这里进行了处理。)
代码解释
from xml.etree import ElementTree as ET
本例中使用的是ElementTree、还可以使用lxml、minidom这两种库来解析XML文件,在此不做说明
获取Observation元素中的内容
由上面的样本可知,我们使用的数据是包含在一个<Data>...</Data>中的,这里使用根元素的find方法可以利用标签名来搜索子元素。
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
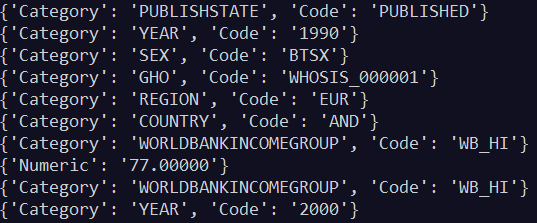
for observation in data:
for item in observation:
print(item.attrib)
输出(部分):
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
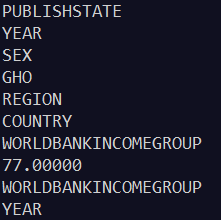
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
rec_key = item.attrib[lookup_key]
print(rec_key)
上面代码得到了数据的键,但还没有取得相应的值。
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
from xml.etree import ElementTree as ET
tree = ET.parse('data-text.xml')
root = tree.getroot() #获取树的根元素
data = root.find('Data')
all_data = []
for observation in data:
record = {}
for item in observation:
lookup_key_List = list(item.attrib.keys())
lookup_key = lookup_key_List[0]
if lookup_key == 'Numeric':
rec_key = 'NUMERIC'
rec_value = item.attrib['Numeric']
else:
rec_key = item.attrib[lookup_key]
rec_value = item.attrib['Code']
print(rec_key,rec_value)

第三章——供机器读取的数据(XML)的更多相关文章
- 第三章——供机器读取的数据(CSV与JSON)
本书使用的文件.代码:https://github.com/huangtao36/data_wrangling 机器可读(machine readable)文件格式: 1.逗号分隔值(Comma-Se ...
- python数据处理(一)之供机器读取的数据 csv,json,xml
代码与资料 https://github.com/jackiekazil/data-wrangling 1 csv 1.1导入csv数据 1.2将代码保存到文件中并在命令行中运行 2.json 2 导 ...
- 第三章:使用ListView展示数据
一.ImageList:存储图像集合 Images 存储的所有图像 ImageSize 图像的大小 ColorDepth 颜色数 TransparentColor 被视为透明的颜色 先设置ColorD ...
- 数据库-第三章 关系数据库标准语言SQL-3.3 数据查询
数据查询 例: 一.单表查询 1.定义 是指仅涉及一个表的查询 2.选择表中的若干列 查询指定列 例: 查询全部列 例: 查询经过计算的值 例: 3.选择表中的若干元组 消除取值重复的行 例: 查询满 ...
- SQL SERVER 2012 第三章 使用INSERT语句添加数据
INSERT [TOP (<expression>) [PERCENT] [INTO] <tabular object>[(column list)][OUTPUT <o ...
- (第二章第三部分)TensorFlow框架之读取二进制数据
系列博客链接: (第二章第一部分)TensorFlow框架之文件读取流程:https://www.cnblogs.com/kongweisi/p/11050302.html (第二章第二部分)Tens ...
- Laxcus大数据管理系统2.0(5)- 第三章 数据存取
第三章 数据存取 当前的很多大数据处理工作,一次计算产生几十个GB.或者几十个TB的数据已是正常现象,驱动数百.数千.甚至上万个计算机节点并行运行也已经不足为奇.但是在数据处理的后面,对于这种在网络间 ...
- CentOS6安装各种大数据软件 第三章:Linux基础软件的安装
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- (第二章第二部分)TensorFlow框架之读取图片数据
系列博客链接: (第二章第一部分)TensorFlow框架之文件读取流程:https://www.cnblogs.com/kongweisi/p/11050302.html 本文概述: 目标 说明图片 ...
随机推荐
- Waltz of love
Waltz of love Love me tenderly Love me softly Close your eyes,fling to the dangcing hall Follow your ...
- English_phonetic symbol
Introduction 本人学习了奶爸课程---45天的搞定发音课,结合自己的英语水平,为自己撰写的一个系统的英语发音课,不只是音标,还有音标辨析.连读.音调等. 重点:英语发音时一个持续一生的东西 ...
- python逻辑判断 () not and or
python逻辑判断 () not and or 优先级关系:()>not>and>or 运算符示意 not –表示取反运算. and –表示取与运算. or –表示取或运算. or ...
- HyperLedger Fabric 1.4 官方End-2-End运行(8)
8.1 End-2-End案例简介 Fabric官方提供了实现点对点的Fabric网络示例,该网络有两个组织(organizations),一个组织有两种节点(Peer),通过Kafka ...
- 北京Uber优步司机奖励政策(1月19日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 成都Uber优步司机奖励政策(3月2日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 成都Uber优步司机奖励政策(1月9日)
1月9日 奖励政策 滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblog ...
- [数据结构]_[C/C++]_[链表的最佳创建方式]
场景 1.链表在C/C++里使用非常频繁, 因为它非常使用, 可作为天然的可变数组. push到末尾时对前面的链表项不影响. 反观C数组和std::vector, 一个是静态大小, 一个是增加多了会对 ...
- CakePHP中回调函数的使用
我们知道模型主要是用来处理数据的,有时我们想在模型操作之前或之后做一些额外逻辑处理,这时候就可以使用回调函数. 回调函数有很多种,beforeFind,afterFind,beforeValidate ...
- Linux命令非常全
最近都在和Linux打交道,感觉还不错.这也是很多人喜欢linux的原因,比较短小但却功能强大.我将我了解到的命令列举一下,仅供大家参考: 系统信息 arch 显示机器的处理器架构(1) uname ...