字符串模式匹配算法--BF和KMP详解
1,问题描述
字符串模式匹配:串的模式匹配 ,是求第一个字符串(模式串:str2)在第二个字符串(主串:str1)中的起始位置。
注意区分:
- 子串:要求连续 (如:abc 是abcdef的子串)
- 子序列:可以不连续 (如:acd是abcdef的子序列)
2,简单字符串模式匹配(BF算法)
2.1 简单匹配思路描述
简单字符串模式匹配算法,也就是了BF(Brute Force 蛮力,暴力)算法,俗称暴力法。
基本思路:
- (1) 从主串S指定的字符开始(一般为第1个)和模式串P的第一个字符比较,若相等,则继续逐个比较后续字符,直到P中的每个字符依次和S中的一个连续字符序列相等,则称匹配成功;
- (2)如果比较过程中有某对字符串不相等,则从主串S的下一个字符起再重新和T的第一个字符比较。如果S中的字符都比完了仍然没有匹配 成功,则称匹配不成功。
简单模式匹配算法--举例:
主串str1: a b a b c a b c a c b a b
模式串str2: a b c a c (i=0
第一趟匹配:a b a b c a b c a c b a b
a b c
(j=2 (i=1
第二趟匹配: a b a b c a b c a c b a b
a
(j=0 (i=2
第三趟匹配: a b a b c a b c a c b a b
a b c a c
(j=4 (i=3
第四趟匹配:a b a b c a b c a c b a b
a
(j=0 (i=4
第五趟匹配:a b a b c a b c a c b a b
a
(j=0 (i=5 (i=10
第六趟匹配:a b a b c a b c a c b a b
a b c a c
(j=0 (j=5
2.2 时间复杂度
设串S和P的长度分别为m,n,则它在最坏情况下的时间复杂度是O(m*n)。BF算法的最坏时间复杂度虽然不好,但它易于理解和编程,在实际应用中,一般还能达到近似于O(m+n)的时间度(最坏情况不是那么容易出现的),因此,还在被大量使用。
2.3 BF代码实现
#include <iostream>
#include <vector> using namespace std; int BF_strMatch(vector<char> v1, vector<char> v2) {
//v1是主串,v2是模式串
//如果匹配成功,返回子串在主串中的起始位置;否则,返回-1;
int i = , j = ;
int n = v1.size(), m = v2.size();
while (i < n && j < m) {
if (v1[i] == v2[j]) {
++i;
++j;
}
else {
i = i - j + ;//通过观察下标变换的关系得出
j = ;
}
}
return (j == m) ? (i - m) : -;
} void main() {
vector<char> s1 = { 'a','b','a','b','c','a','b','c','a','c','b','a','b'};
vector<char> s2 = { 'a','b','c','a','c' };
cout << BF_strMatch(s1, s2) << endl;
}
3,经典KMP匹配算法
3.1 KMP算法基本思想
KMP算法可以在O(n+m)的时间数量级上完成串的模式匹配操作。其改进在于:每当一趟匹配过程中出现字符比较不等时,不需回溯 i 指针( i 只增不减),而是利用已经得到的“部分匹配”的结果将模式串向右滑动尽可能远一段距离后,继续进行比较。
3.2 KMP算法关键点
KMP算法加速原因:让前面匹配过的信息指导后面。
KMP算法理解的关键点:
- 1.求解最长公共子串(next数组),只跟模式串 str2 有关,而与主串 str1 无关(有的参考书没有讲解清楚这一点,导致容易混淆);
- 2.最长公共子串,大多数的参考书称为最长公共前缀,这里我称之为最长公共子串,是为了避免与下面两个概念混淆。这里对最长公共子串的定义:最长前缀和最长后缀的最长公共子串。
- 最长前缀:从第一个字符的起的连续一串字符,不含最后一个字符;
- 最长后缀:不含第一个字符,从中间某一个字符其到最后一个字符的连续一串字符;
例1:对于模式串“a b c a b c d”,求字符d的最长公共子串。
解:设length为字符d最长公共子串的长度,根据定义,length的可能取值为1~5:
a b c a b c d
length = 1 : a != c
length = 2 : ab != bc
length = 3 : abc == abc
length = 4 : abca != cabc
length = 5 : abcab != bcabc
显然,字符d的最长公共子串的长度为3 例2:对于模式串“a a a a a b”,求字符b的最长公共子串。
同理,length可能的取值为1~4:
length = 1 : a == a
length = 2 : aa == aa
length = 3 : aaa == aaa
length = 4 : aaaa == aaaa
显然,字符b的最长公共子串的长度为4
3.3 求解next数组
next数组的求解,实际是对每个位置找到最长的公共子串:
一般地,对于模式串str2="P0P1P2…Pm-1",长度为m,其next数组的定义:
- 当j=0时,即str2中的第一个字符,其前没有字符,人为规定 next[0] = -1;
- 当j=1时,即str2中的第二字符,其前只有一个字符,人为规定 next[1] = 0;
- 当 2<= j =< m-1:
- Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"}不空时,next[j] = Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"},
- Max{ k | 1<= k =< j-1 且 “P0…Pk-1” == "Pj-k…Pj-1"}为空时,next[j] = 0 ;
求解next数组的代码:
vector<int> getNext(vector<char> v) {
//模式串str2 与 模式串str2 (自己跟自己) 做KMP匹配
int m = v.size();//v字符串长度
vector<int> next(m, );
int i = ;
int j = ;
if (m == ) return next;
next[] = -;
if (m == ) return next;
next[] = ;
while (i < m) {
if (v[i - ] == v[j]) {
++j;
next[i] = j;
++i;
}
else if(j>){
j = next[j];
}
else {
next[i++] = ;
}
}
return next;//放对位置
}
//test
void main() {
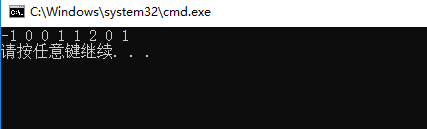
vector<char> s3 = { 'a','b','a','a','b','c','a','c' };
for (auto c : getNext(s3)) {
cout << c << " ";
}
cout << endl;
}
求解next数组的经典方法(最好理解记住):
# 获取next[]数组
def getNext(str):
next = [-1]*len(str) # next[0]=-1
if len(str)>=1:
next[1] = 0
i, j =1, 0
while(i<len(str)-1):
if j==-1 or str[i]==str[j]:
i += 1
j += 1
next[i] = j
else:
next[i] = next[j]
return next
3.4 完整的KMP算法代码
#include <iostream>
#include <vector> using namespace std; int KMP_strMatch(vector<char> v1, vector<char> v2,vector<int> next) {
//v1是主串,v2是模式串
//如果匹配成功,返回子串在主串中的起始位置;否则,返回-1;
int i = , j = ;
int n = v1.size(), m = v2.size();
while (i < n && j < m) {
if (v1[i] == v2[j]) {
++i;
++j;
}
else {
if (j == ) ++i; //j回到模式串头部还不匹配,i加1
j = next[j]; //使用next数组提供指导
}
}
return (j == m) ? (i - m) : -;
} vector<int> getNext(vector<char> v) {
//模式串str2 与 模式串str2 (自己跟自己) 做KMP匹配
int m = v.size();//v字符串长度
vector<int> next(m, );
int i = ;
int j = ; if (m == ) return next;
next[] = -;
if (m == ) return next;
next[] = ; while (i < m) {
if (v[i - ] == v[j]) {
++j;
next[i] = j;
++i;
}
else if(j>){
j = next[j];
}
else {
next[i++] = ;
} }
return next;//放对位置
} void main() {
vector<char> s1 = { 'a','b','a','b','c','a','b','c','a','c','b','a','b'};
vector<char> s2 = { 'a','b','c','a','c' }; for (auto c : getNext(s2)) {
cout << c << " ";
}
cout << endl;
cout << KMP_strMatch(s1, s2,getNext(s2)) << endl;
}
4,KMP算法进深理解
4.1 BF和KMP执行流程对比
- 当str1[i] == str2[j]时,操作一样,++i,++j;
- 当str1[i] != str2[j],即不匹配时:
- BF:i = i - j + 2, j = 0;
- KMP:i 不动(不回溯),j = next[j];
4.2 next数组要求最大公共子串的原因
str1:a b k a b a b k a b x
str2:a b k a b a b k a b y //i=10,j=10 不匹配,j=next[10]=5(不是j=0,减少了5次比较),继续比较
a b k a b a b k a b F //i=10,j=5 不匹配,j=next[5]=2(不是j=0,减少了2次比较),继续比较
a b k a b a b k a b F //i=10,j=2 不匹配,j=next[2]=0(才是j=0,较少了0次比较),继续比较
a b k a b a b k a b F //i=10,j=0 不匹配,++i(此时i才加1),j=0
分析:
(1)加速的原因:减少了不必要的比较次数。
(2)为什么模式串可以向右滑动尽可能远一段距离后,再继续比较: 正如上面的例子:前面都是相等的,到了x与y匹配时才不相等——
(W--------------Q)
[i|-----k---|j |x] //红色部分是滑过的距离,即不必要的比较次数,这里指的i……j之间的位置不可能匹配出str2
(-a-b-k-a-b)(-a-b-k-a-b) (W--------------Q)
(-a-b-k-a-b)(-a-b-k-a-b)
[0| |j |y] 假设从k字符起可以配出str2,那么必然会存在更长的子串(W-------Q)比y位置的最长子串(a-b-k-a-b)更长,如果next数组求解正确,这是不可能。出现矛盾,假设不成立。
因为next数组求的就是每一个字符的最长公共子串。
参考资料:
1.《数据结构考研复习指导》--王道单科书
2.https://www.cnblogs.com/zzqcn/p/3508442.html#_labelTop 字符串模式匹配算法1 - BF和KMP算法
3. https://www.nowcoder.com/courses/semester/senior 《牛客高级项目课——(牛客网)》--大牛·左程云
字符串模式匹配算法--BF和KMP详解的更多相关文章
- Aho-Corasick 多模式匹配算法、AC自动机详解
Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多. Aho-Corasick算法对应的数据结构是Aho-Corasick自动机,简称AC自动机. 搞编程的一般都应该知道自动机 ...
- [转] 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 转载自:http://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boy ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法一网打尽
字符串模式匹配算法——BM.Horspool.Sunday.KMP.KR.AC算法一网打尽 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 ...
- 字符串模式匹配算法——BM、Horspool、Sunday、KMP、KR、AC算法
ref : https://dsqiu.iteye.com/blog/1700312 本文内容框架: §1 Boyer-Moore算法 §2 Horspool算法 §3 Sunday算法 §4 KMP ...
- Java经典设计模式之十一种行为型模式(附实例和详解)
Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:Java经典设计模式之 ...
- Java经典设计模式之七大结构型模式(附实例和详解)
博主在大三的时候有上过设计模式这一门课,但是当时很多都基本没有听懂,重点是也没有细听,因为觉得没什么卵用,硬是要搞那么复杂干嘛.因此设计模式建议工作半年以上的猿友阅读起来才会理解的比较深刻.当然,你没 ...
- Java设计模式之七大结构型模式(附实例和详解)
博主在大三的时候有上过设计模式这一门课,但是当时很多都基本没有听懂,重点是也没有细听,因为觉得没什么卵用,硬是要搞那么复杂干嘛.因此设计模式建议工作半年以上的猿友阅读起来才会理解的比较深刻.当然,你没 ...
- Java设计模式之十一种行为型模式(附实例和详解)
Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:J设计模式之五大创建型 ...
- (转)Java经典设计模式(3):十一种行为型模式(附实例和详解)
原文出处: 小宝鸽 Java经典设计模式共有21中,分为三大类:创建型模式(5种).结构型模式(7种)和行为型模式(11种). 本文主要讲行为型模式,创建型模式和结构型模式可以看博主的另外两篇文章:J ...
随机推荐
- ElasticSearch 2.0以后的改动导致旧的资料和书籍需要订正的部分
id原先是可以通过path指定字段的 "thread": { "_id" : { "path" : "thread_id" ...
- Machine Learning分类:监督/无监督学习
从宏观方面,机器学习可以从不同角度来分类 是否在人类的干预/监督下训练.(supervised,unsupervised,semisupervised 以及 Reinforcement Learnin ...
- codeforces 269C Flawed Flow(网络流)
Emuskald considers himself a master of flow algorithms. Now he has completed his most ingenious prog ...
- 静态类型&动态类型
何时使用:使用存在继承关系的类型时,必须将一个变量或其他表达式的静态类型与该表达式表示对象的动态类型区分开来 静态类型:表达式的静态类型在编译时总是已知的,它是变量声明时的类型或表达式生成的类型 动态 ...
- Thunder团队第五周 - Scrum会议7
Scrum会议7 小组名称:Thunder 项目名称:i阅app Scrum Master:苗威 工作照片: 参会成员: 王航:http://www.cnblogs.com/wangh013/ 李传康 ...
- maven把项目打包成jar包后找不到velocity模板的bug
使用springmvc 开发时候要实现发送velcotiy模板邮件,在配置正常后,在本地测试正常后,使用maven打包成jar包后,报以下错误, Caused by: org.apache.veloc ...
- spring学习(一)——控制反转简单例子
spring框架是一个开源的轻量级的基于IOC与AOP核心技术的容器框架,主要是解决企业的复杂操作实现. 那IOC与AOP,到底如何解释呢,在看spring视频中,两个专业术语一定必须要懂得. IOC ...
- 3DMAX2016安装教程【图文】
下载安装包之后,双击setup.exe. 下面是安装图片教程: 点击安装 点击下一步. 如图输入序列号和产品密钥. 填写安装路径,然后下一步. 开始安装,等待. 安装成功.
- YaoLingJump开发者日志(四)
这么有意思的游戏没有剧情怎么行?开始剧情的搭建. 用到了LGame中的AVGScreen,确实是个好东西呢,只需要准备图片和对话脚本就行了. 经过不断的ps,yy,ps,yy,游戏开头的剧 ...
- SIM卡是什么意思?你所不知道的SIM卡知识扫盲(详解)【转】
原文链接:http://www.jb51.net/shouji/359262.html 日常我们使用手机,SIM卡是手机的必须,没有了它就不能接入网络运营商进行通信服务.SIM卡作为网络运营商对于我们 ...