【译】调优Apache Kafka集群
今天带来一篇译文“调优Apache Kafka集群”,里面有一些观点并无太多新颖之处,但总结得还算详细。该文从四个不同的目标出发给出了各自不同的参数配置,值得大家一读~ 原文地址请参考:https://www.confluent.io/blog/optimizing-apache-kafka-deployment/
==========================================
Apache Kafka是当前最好的企业级流式处理平台。把你的应用程序链接到Kafka集群,剩下的所有事情Kafka都可以帮你做了:自动帮你完成负载均衡,自动实现Zero-Copy的数据传输、消费者组成员变动时自动的rebalance以及应用状态持久化存储的自动备份以及分区leader自动的故障转移等——运维人员的梦想终于成真了!
————笔者:最近在看Apache Flink。说到streaming这部分,Flink可一点都不比Kafka streams差。至于是不是最好的流式处理平台,仁者见仁吧~~
使用默认的Kafka参数配置你就能够从零搭建起一个Kafka集群环境用于开发及测试之用,但默认配置通常都不匹配你的生产环境,因此必须要做某种程度的调优。毕竟不同的使用场景有着不同的使用需求和性能指标。而Kafka提供的各种参数就是为了优化这些需求和指标的。Kafka提供了很多配置供用户设置以确保搭建起来的Kafka环境是能够满足需求目标的,因此详细地去调研这些参数的含义以及针对不同参数值进行测试是非常重要的。所有这些工作都应该在Kafka正式上生产环境前就做好,并且各种参数的配置要考虑未来集群规模的扩展。
执行优化的流程如下图所示:

- 明确调优目标
- 有针对性地配置Kafka server端和clients端参数
- 执行性能测试,监控各个指标以确定是否满足需求以及是否有进一步调优的可能
一、确立目标
第一步就是要明确性能调优目标,主要从4个方面考虑:吞吐量(throughput)、延时(latency)、持久性(durability)和可用性(availability)。根据实际的使用场景来确定要达到这4个中的哪个(或哪几个)目标。有时候我们可能很难确定自己到底想要什么,那么此时可以尝试采用这样的方法:让你的团队坐下来讨论一下原本的业务使用场景然后看看主要的业务目标是什么。确立目标的原因主要有两点:
- “鱼和熊掌不可兼得”——你没有办法最大化所有目标。这4者之间必然存在着权衡(tradeoff)。常见的tradeoff包括:吞吐量和延时权衡、持久性和可用性之间权衡。但是当我们考虑整个系统时通常都不能孤立地只考虑其中的某一个方面,而是需要全盘考量。虽然它们之间不是互斥的,但使所有目标同时达到最优几乎肯定是不可能的
- 我们需要不断调整Kafka配置参数以实现这些目标,并确保我们对Kafka的优化是满足用户实际使用场景的需要
下面的这些问题可以帮助你确立目标:
- 是否期望着Kafka实现高吞吐量(TPS,即producer生产速度和consumer消费速度),比如几百万的TPS?由于Kafka自身良好的设计,生产超大数量的消息并不是什么难事。比起传统的数据库或KV存储而言,Kafka要快得多,而且使用普通的硬件就能够做到这点
- 是否期望着Kafka实现低延时(即消息从被写入到被读取之间的时间间隔越小越好)? 低延时的一个实际应用场景就是平时的聊天程序,接收到某一条消息越快越好。其他的例子还包括交互性网站中用户期望实时看到好友动态以及物联网中的实时流处理等
- 是否期望着Kafka实现高持久性,即被成功提交的消息永远不能丢失?比如事件驱动的微服务数据管道使用Kafka作为底层数据存储,那么就要求Kafka不能丢失事件。再比如streaming框架读取持久化存储时一定要确保关键的业务事件不能遗漏等
- 是否期望着Kafka实现高可用?即使出现崩溃也不能出现服务的整体宕机。Kafka本身是分布式系统,天然就是能够对抗崩溃的。如果高可用是你的主要目标,配置特定的参数确保Kafka可以及时从崩溃中恢复就显得至关重要了
二、配置参数
下面我们将分别讨论这四个目标的优化以及对应的参数设置。这些参数涵盖了producer端、broker端和consumer端的不同配置。如前所述,很多配置都提现了某种程度的tradeoff,在使用时一定要弄清楚这些配置的真正含义,做到有的放矢。
producer端
- batch.size
- linger.ms
- compression.type
- acks
- retries
- max.in.flight.requests.per.connection
- buffer.memory
Broker端
- default.replication.factor
- num.replica.fetchers
- auto.create.topics.enable
- min.insync.replicas
- unclean.leader.election.enable
- broker.rack
- log.flush.interval.messages
- log.flush.interval.ms
- unclean.leader.election.enable
- min.insync.replicas
- num.recovery.threads.per.data.dir
Consumer端
- fetch.min.bytes
- auto.commit.enable
- session.timeout.ms
1 调优吞吐量
Producer端
- batch.size = 100000 - 200000(默认是16384,通常都太小了)
- linger.ms = 10 - 100 (默认是0)
- compression.type = lz4
- acks = 1
- retries = 0
- buffer.memory:如果分区数很多则适当增加 (默认是32MB)
Consumer端
- fetch.min.bytes = 10 ~ 100000 (默认是1)
2 调优延时
Producer端
- linger.ms = 0
- compression.type = none
- acks = 1
Broker端
- num.replica.fetchers:如果发生ISR频繁进出的情况或follower无法追上leader的情况则适当增加该值,但通常不要超过CPU核数+1
Consumer端
- fetch.min.bytes = 1
3 调优持久性
Producer端
- replication.factor = 3
- acks = all
- retries = 相对较大的值,比如5 ~ 10
- max.in.flight.requests.per.connection = 1 (防止乱序)
Broker端
- default.replication.factor = 3
- auto.create.topics.enable = false
- min.insync.replicas = 2,即设置为replication factor - 1
- unclean.leader.election.enable = false
- broker.rack: 如果有机架信息,则最好设置该值,保证数据在多个rack间的分布性以达到高持久化
- log.flush.interval.messages和log.flush.interval.ms: 如果是特别重要的topic并且TPS本身也不高,则推荐设置成比较低的值,比如1
Consumer端
- auto.commit.enable = false 自己控制位移
4 调优高可用
Broker端
- unclean.leader.election.enable = true
- min.insync.replicas = 1
- num.recovery.threads.per.data.dir = log.dirs中配置的目录数
Consumer端
- session.timeout.ms:尽可能地低
三、指标监控
1 操作系统级指标
- 内存使用率
- 磁盘占用率
- CPU使用率
- 打开的文件句柄数
- 磁盘IO使用率
- 带宽IO使用率
2 Kafka常规JMX监控
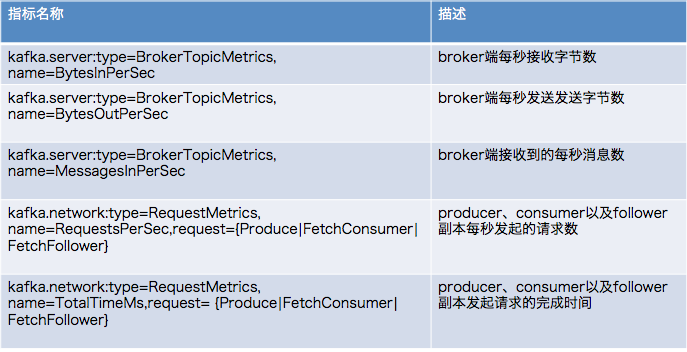
3 易发现瓶颈的JMX监控

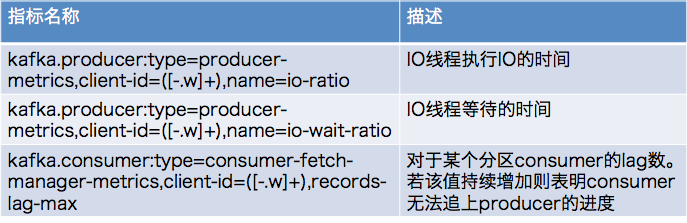
4 clients端常用JMX监控
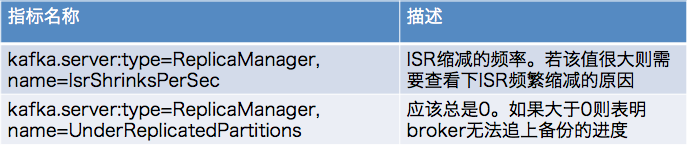
5 broker端ISR相关的JMX监控
==========================================
以上就是这篇原文的简要译文。还是那句话,里面的很多参数设置都已经司空见惯了,并无太多新意。不过这篇文章从吞吐量、延时、持久化和可用性4个方面给出了不同的思考。从这一点上来说还是值得一读的。
【译】调优Apache Kafka集群的更多相关文章
- Apache Kafka 集群部署指南
公众号关注 「开源Linux」 回复「学习」,有我为您特别筛选的学习资料~ Kafka基础 消息系统的作用 应该大部分小伙伴都清楚,用机油装箱举个例子. 所以消息系统就是如上图我们所说的仓库,能在中间 ...
- Linux性能调优、Linux集群与存储等
http://freeloda.blog.51cto.com/ 51cto
- 《Apache Kafka实战》读书笔记-调优Kafka集群
<Apache Kafka实战>读书笔记-调优Kafka集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.确定调优目标 1>.常见的非功能性要求 一.性能( ...
- 单机简单搭建一个kafka集群(没有进行内核参数和JVM的调优)
1.JDK安装 在我的部署单节点kafka的博客里有相关的方法.(https://www.cnblogs.com/ToBeExpert/p/9789486.html )zookeeper和kafka的 ...
- 《Apache kafka实战》读书笔记-管理Kafka集群安全之ACL篇
<Apache kafka实战>读书笔记-管理Kafka集群安全之ACL篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 想必大家能看到这篇博客的小伙伴,估计你对kaf ...
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
- window环境搭建zookeeper,kafka集群
为了演示集群的效果,这里准备一台虚拟机(window 7),在虚拟机中搭建了单IP多节点的zookeeper集群(多IP节点的也是同理的),并且在本机(win 7)和虚拟机中都安装了kafka. 前期 ...
- 利用新版本自带的Zookeeper搭建kafka集群
安装简要说明新版本的kafka自带有zookeeper,其实自带的zookeeper完全够用,本篇文章以记录使用自带zookeeper搭建kafka集群.1.关于kafka下载kafka下载页面:ht ...
- kafka集群原理介绍
目录 kafka集群原理介绍 (一)基础理论 二.配置文件 三.错误处理 kafka集群原理介绍 @(博客文章)[kafka|大数据] 本系统文章共三篇,分别为 1.kafka集群原理介绍了以下几个方 ...
随机推荐
- js if判断 遍历 替换图片地质
<script> $(document).ready(function() { var s = "The rain in Spain falls mainly in the pl ...
- [转]Android精品开源项目整理
前言: 无论你是android的初学者,还有是android开发多年的高手,可能都会有很多想法和经验希望与人分享交流,渴望能够接触到更多的实战项目,正所谓所谓与高手论道才能互补所长,与英雄 ...
- UltraCompare 激活
UltraCompare安装包.注册机下载地址: 链接:https://pan.baidu.com/s/1eSu8Pbk 密码:fkkh 1.安装UltraCompare 2. 3. 打开注册机,填入 ...
- Maven项目模板
maven 使用 Archetype 概念为用户提供不同类型的项目模板,它是一个非常大的列表(614个数字). maven 使用下面的命令来帮助用户快速开始构建一个新的 Java 项目. mvn ar ...
- Python 中 __all__ 的作用
1.测试文件foo.py # -*- coding: utf-8 -*- # import sys # reload(sys) # sys.setdefaultencoding('gbk') __al ...
- Linux 用户与用户组管理
Linux 是一个多用户多任务的分是操作系统,用户是实现操作系统资源分配,同时也是安全权限模型的核 心要素之一:用户组是一个容纳很多用户的容器,可以分配权限组,进一步优化了权限分配. 一.用户管理 用 ...
- MySQL谨慎使用"replace into"
From: http://blog.xupeng.me/2013/10/11/mysql-replace-into-trap/ MySQL 对 SQL 有很多扩展,有些用起来很方便,但有一些被误用之后 ...
- [mysql]ERROR 1364 (HY000): Field 'ssl_cipher' doesn't have a default value
From: http://m.blog.csdn.net/blog/langkeziju/13511411 我的MySQL版本为5.6.14版本,是二进制包安装的(虽然是二进制包安装的,但是以下问题同 ...
- KONG基础使用
KONG是一个基于Nginx的API Gateway.提供了诸如身份认证,权限控制,流量控制,日志等一系列API相关的组件,可谓相当方便.KONG项目首页KONG入门KONG的Github地址KONG ...
- POI-PPT官方文档
注意 请注意,XSLF仍然处于早期开发阶段,并且将来会在发行版中发生不兼容的更改. 特征索引 创建新的演示文稿 阅读现有演示文稿 使用预定义的布局创建幻灯片 删除幻灯片 重新订购幻灯片 更改幻灯片大小 ...