索引快速扫描(index fast full scan)
一、索引快速扫描(index fast full scan)
索引快速全扫描(INDEX FAST FULL SCAN)和索引全扫描(INDEX FULL SCAN)极为类似,它也适用于所有类型的B树索引(包括唯一性索引和非唯一性索引)。和索引全扫描一样,索引快速全扫描也需要扫描目标索引所有叶子块的所有索引行。
索引快速全扫描与索引全扫描相比有如下三点区别。
(1)索引快速全扫描只适用于CBO。
(2)索引快速全扫描可以使用多块读,也可以并行执行。
(3)索引快速全扫描的执行结果不一定是有序的。这是因为索引快速全扫描时Oracle是根据索引行在磁盘上的物理存储顺序来扫描,而不是根据索引行的逻辑顺序来扫描的,所以扫描结果才不一定有序(对于单个索引叶子块中的索引行而言,其物理存储顺序和逻辑存储顺序一致;但对于物理存储位置相邻的索引叶子块而言,块与块之间索引行的物理存储顺序则不一定在逻辑上有序)。
Fast full index scans are an alternative to a full table scan when the index contains all the columns that are needed for the query(组合索引中的列包含了需要查询的所有列), and at least one column in the index key has the NOT NULL constraint(至少有一个有非空约束). A fast full scan accesses the data in the index itself, without accessing the table. It cannot be used to eliminate a sort operation, because the data is not ordered by the index key. It reads the entire index using multiblock reads, unlike a full index scan, and can be parallelized.
You can specify fast full index scans with the initialization parameter OPTIMIZER_FEATURES_ENABLE or the INDEX_FFS hint. Fast full index scans cannot be performed against bitmap indexes.
A fast full scan is faster than a normal full index scan in that it can use multiblock I/O(一次可以读多个块,跟全表扫描一样) and can be parallelized just like a table scan.
二、例子
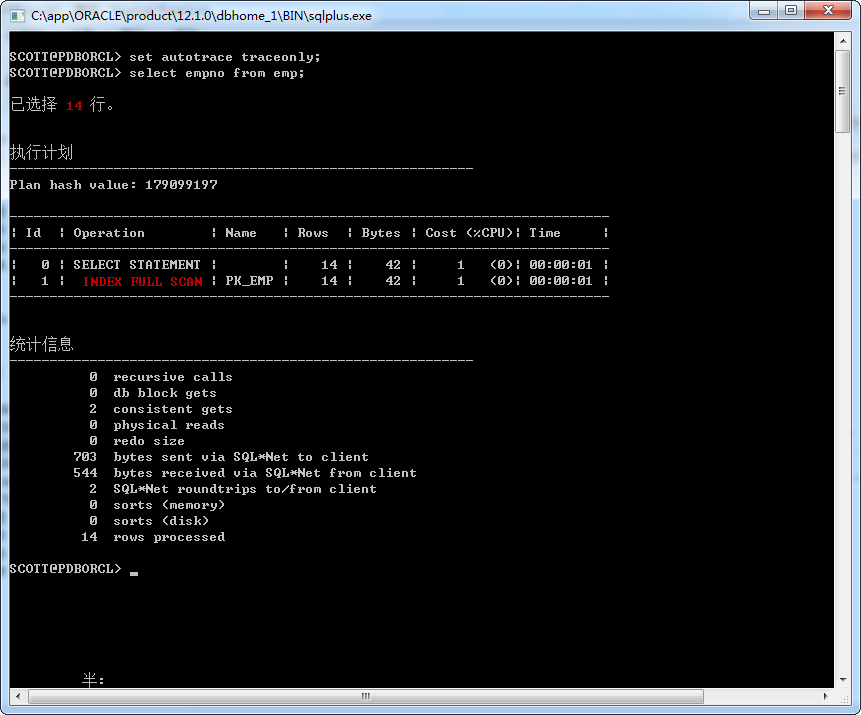
1、针对scott的emp表
select empno from emp;
继续插入数据
BEGIN
FOR I IN 0..1000 LOOP
INSERT INTO EMP(EMPNO,ENAME) VALUES(
I,CONCAT('TBL',I));
END LOOP;
END;
对表EMP及主键索引重新收集一下统计信息:
analyze table emp compute statistics for table for all columns for all indexes;
重新执行
select empno from emp;
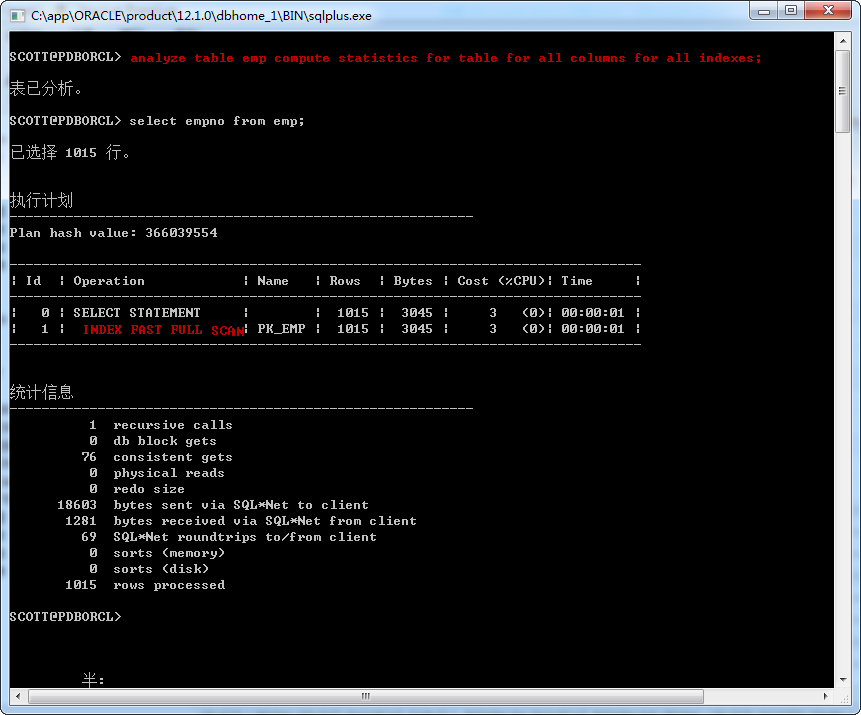
加载策略变成了Fast Full Index Scans
三、对比Index Fast Full Scans与Index Fast Full Scans
INDEX FULL SCAN 与 INDEX FAST FULL SCAN两个长相差不多,乃是一母同胞,因此既有其共性,也有其个性。两者来说其共性是不用扫描
表而是通过索引就可以直接返回所需要的所有数据。这对提高查询性能而言,无疑是一个难得的数据访问方式之一,因为索引中存储的数据通常
是远小于原始表的数据。下面具体来看看两者之间的异同。
我们对比一下 Index Fast Full Scans与Index Fast Full Scans
select /*+ index_ffs(emp pk_emp) */empno from emp;
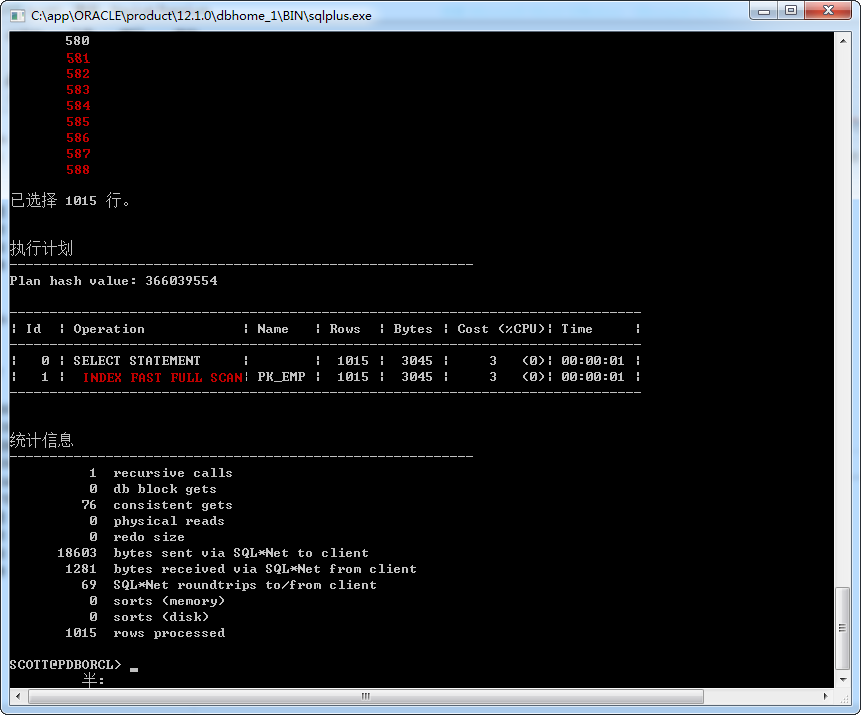
select /*+ index(emp pk_emp) */empno from emp;
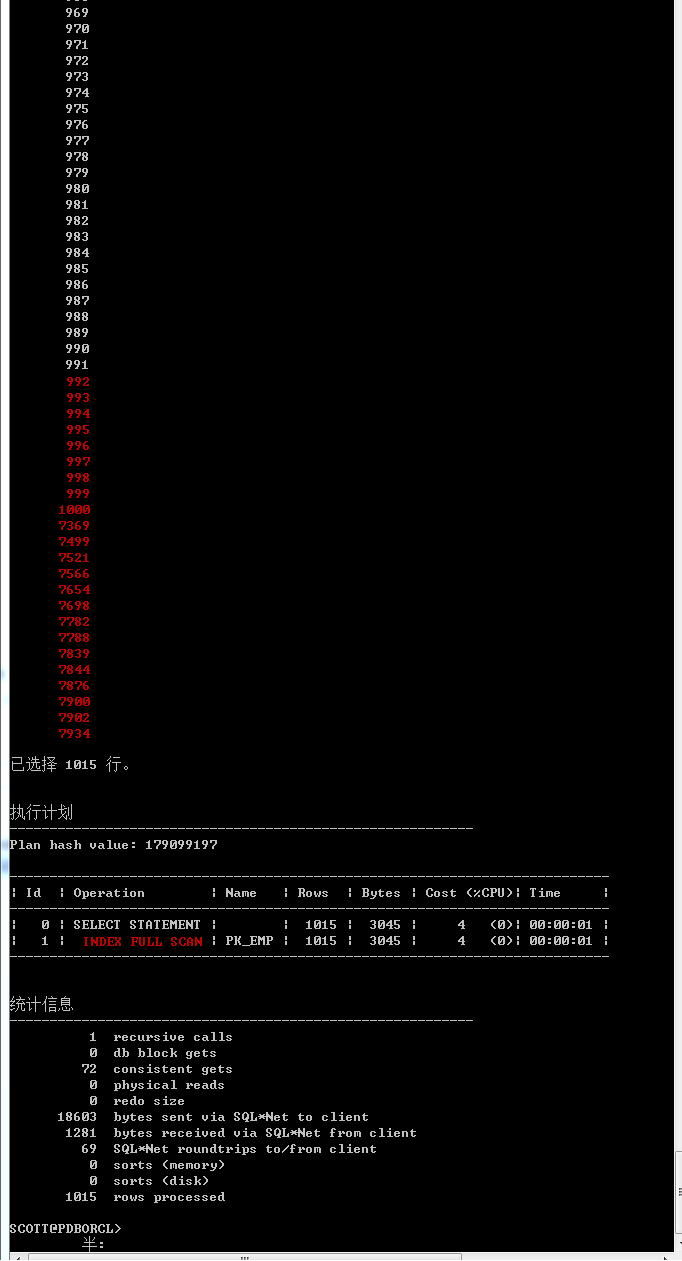
和index full scan不同,index fast full scan的执行结果并没有按照主键索引PK_EMP的索引键值前导列EMPNO来排序,即索引快速全扫描的执行结果确实不一定是有序的。
四、结论
- 当select和where中出现的列都存在索引是发生index full scan与index fast full scan的前提
- index fast full scan使用多块读的方式读取索引块,产生db file scattered reads 事件,读取时高效,但为无序读取
- index full scan使用单块读方式有序读取索引块,产生db file sequential reads事件,当采用该方式读取大量索引全扫描,效率低下
参考
INDEX FULL SCAN vs INDEX FAST FULL SCAN
索引快速扫描(index fast full scan)的更多相关文章
- 为什么不走INDEX FAST FULL SCAN呢
INDEX FULL SCAN 索引全扫描.单块读 .它扫描的结果是有序的,因为索引是有序的.它通常发生在 下面几种情况(注意:即使SQL满足以下情况 不一定会走索引全扫描) 1. SQL语句有ord ...
- INDEX FAST FULL SCAN和INDEX FULL SCAN
INDEX FULL SCAN 索引全扫描.单块读 .它扫描的结果是有序的,因为索引是有序的.它通常发生在 下面几种情况(注意:即使SQL满足以下情况 不一定会走索引全扫描) 1. SQL语句有ord ...
- index range scan,index fast full scan,index skip scan发生的条件
源链接:https://blog.csdn.net/robinson1988/article/details/4980611 index range scan(索引范围扫描): 1.对于unique ...
- index full scan和index fast full scan区别
触发条件:只需要从索引中就可以取出所需要的结果集,此时就会走索引全扫描 Full Index Scan 按照数据的逻辑顺序读取数据块,会发生单块读事件, Fast Full Index Scan ...
- Oracle 11G INDEX FULL SCAN 和 INDEX FAST FULL SCAN 对比分析
SQL> drop table test; 表已删除. SQL> create table test as select * from dba_objects where 1!=1; 表已 ...
- index full scan/index fast full scan/index range scan
**************************1************************************* 索引状态: valid. N/A . ...
- 索引唯一性扫描(INDEX UNIQUE SCAN)
索引唯一性扫描(INDEX UNIQUE SCAN)是针对唯一性索引(UNIQUE INDEX)的扫描,它仅仅适用于where条件里是等值查询的目标SQL.因为扫描的对象是唯一性索引,所 ...
- 索引范围扫描(INDEX RANGE SCAN)
索引范围扫描(INDEX RANGE SCAN)适用于所有类型的B树索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围查询(谓词条件为 BETWEEN.<.>等): ...
- oracle中索引快速全扫描和索引全扫描的区别
当进行index full scan的时候 oracle定位到索引的root block,然后到branch block(如果有的话),再定位到第一个leaf block, 然后根据leaf bloc ...
随机推荐
- Activity间用Intent、Bundle、onActivityResult进行传值
其实Activity间的传值就是通过Bundle,intent中也是自动生成了Bundle来传值,里面还有个onActivityResult()方法也可以传送数值. 如果一个Activity是由sta ...
- [Web 前端] Jquery实现可直接编辑的表格
cp from :https://www.cnblogs.com/sjqq/p/6392001.html?utm_source=itdadao&utm_medium=referral 文实例讲 ...
- Excel 2016 Power View选项卡不显示的问题
https://zhuanlan.zhihu.com/p/43543442 PowerView是Excel中的Power系列插件之一,可以基于excel制作交互式仪表板. 初学者在使用Power Vi ...
- mysqldump参数详细说明
Mysqldump参数大全(参数来源于mysql5.5.19源码) 参数 参数说明 --all-databases , -A 导出全部数据库. mysqldump -uroot -p --al ...
- Chapter 5 -- ImmutableCollections
Example publicstatic final ImmutableSet<String> COLOR_NAMES =ImmutableSet.of( "red" ...
- MFC中如何显示颜色选择对话框
其实很简单,使用MFC现有的类CColorDialog 即可实现 核心代码如下: void CCColorDialogView::OnGraphSetting() { CColorDialog m_s ...
- Pycharm安装详细教程
今天小编给大家分享如何在本机上下载和安装Pycharm,具体的教程如下: 1.首先去Pycharm官网,或者直接输入网址:http://www.jetbrains.com/pycharm/downlo ...
- Android -- Toolbar跟随ListView滑动隐藏和显现
布局 <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:too ...
- 在SAE分布式服务上开发需要解决的问题
这是在开发“幸运猜数”微信游戏的时候遇到的问题 对游戏感兴趣的,可以关注微信公众ID: EasyTool 回复[幸运猜数]开始游戏 之前提供的功能:[黄金][双色球][记事]等,都是无状态服务 而开发 ...
- kaggle预测
两个预测kaggle比赛 一 .https://www.kaggle.com/c/web-traffic-time-series-forecasting/overview Arthur Suilin• ...