Jmeter 处理Unicode编码转为中文
对于接口中返回报文,有的接口返回信息是Unicode编码,写断言的时候,要么就Response Assertion就写成Unicode编码的断言,如下图:
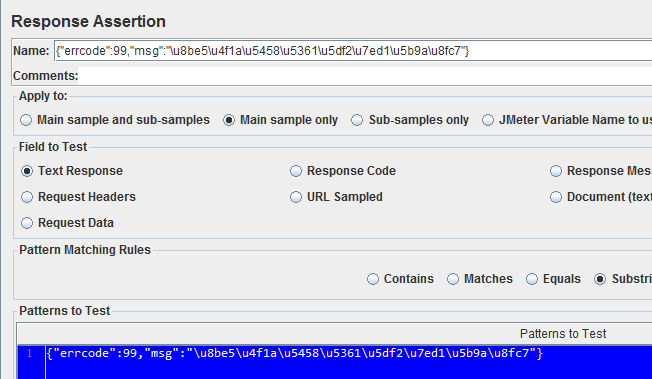
真心不觉得返回报文加密能有多安全,别人将报文复制到
http://tool.chinaz.com/tools/unicode.aspx
站点,一查不就清楚了么,如下图:
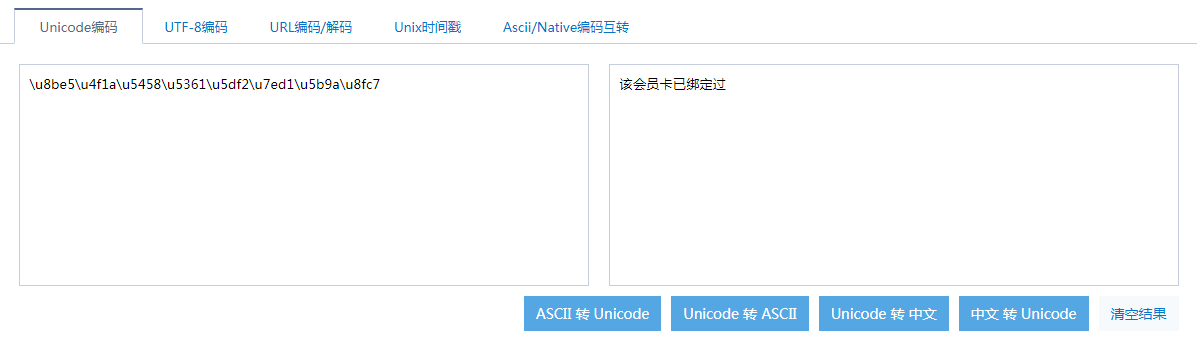
秉承着学习的态度,我还是试了试Jmeter能否对响应报文中Unicode编码转中文。
思想1: 用BeanShell PostProcessor将响应报文中Unicode编码直接转中文。
操作: Step1: 将请求中添加BeanShell后置处理器,张贴下面代码,保存。运行,返回信息如下。

Step2: 可能会遇到的问题:
1,中文显示????乱码怎么办? 修改jmeter.properties中默认编码格式为UTF-8,保存,重启Jmeter生效。
# The encoding to be used if none is provided (default ISO-8859-1)
sampleresult.default.encoding=UTF-8
2,没有转码为中文怎么办? 查看代码,看看Java中运行能否成功。
代码如下:
String s=new String(prev.getResponseData(),"UTF-8");
char aChar;
int len= s.length();
StringBuffer outBuffer=new StringBuffer(len);
for(int x =0; x <len;){
aChar= s.charAt(x++);
if(aChar=='\\'){
aChar= s.charAt(x++);
if(aChar=='u'){
int value =0;
for(int i=0;i<4;i++){
aChar= s.charAt(x++);
switch(aChar){
case'0':
case'1':
case'2':
case'3':
case'4':
case'5':
case'6':
case'7':
case'8':
case'9':
value=(value <<4)+aChar-'0';
break;
case'a':
case'b':
case'c':
case'd':
case'e':
case'f':
value=(value <<4)+10+aChar-'a';
break;
case'A':
case'B':
case'C':
case'D':
case'E':
case'F':
value=(value <<4)+10+aChar-'A';
break;
default:
throw new IllegalArgumentException(
"Malformed \\uxxxx encoding.");}}
outBuffer.append((char) value);}else{
if(aChar=='t')
aChar='\t';
else if(aChar=='r')
aChar='\r';
else if(aChar=='n')
aChar='\n';
else if(aChar=='f')
aChar='\f';
outBuffer.append(aChar);}}else
outBuffer.append(aChar);}
prev.setResponseData(outBuffer.toString());
Jmeter 处理Unicode编码转为中文的更多相关文章
- jmeter beanshell处理请求响应结果时Unicode编码转为中文
在Test Plan下创建一个后置BeanShell PostProcessor,粘贴如下代码即可: String s=new String(prev.getResponseData()," ...
- php将unicode编码转为utf-8方法
介绍 在前端开发中,为了让中文在不同的环境下都能很好的显示,一般是将中文转化为unicode格式,即\u4f60,比如:"你好啊"的 unicode编码为"\u4f60\ ...
- 中文转换成Unicode编码 和 Unicode编码转换为中文
前几天,遇到一个问题,就是在浏览器地址栏传递中文时,出现乱码,考虑了一下,解决方式有很多,我还是采用了转换编码的方式,将中文转换为Unicode编码,然后再解码成中文,以下是实现的过程,非常简单! p ...
- Jmeter查看结果树Unicode编码转中文方法
本文为转载微信公众号文章,如作者发现后不愿意,请联系我进行删除 在jmeter工具的使用中,不管是测试接口还是调试性能时,查看结果树必不可少,然而在查看响应数据时,其中的中文经常以Unicode的编码 ...
- JavaScript为unicode编码转换为中文
代码laycode - v1.1 关于这样的数据转换为中文问题,常用的以下方法. 1. eval解析或new Function("'+ str +'")() str = eval ...
- Unicode编码与中文互转
/** * unicode编码转换为汉字 * @param unicodeStr 待转化的编码 * @return 返回转化后的汉子 */ public static String UnicodeTo ...
- PHP解码unicode编码的中文字符
问题背景:晚上在抓取某网站数据,结果在数据包中发现了这么一串编码的数据:"......\u65b0\u6d6a\u5fae\u535a......www.jinyuanbao.cn" ...
- scrapy 爬虫返回json格式内容unicode编码转换为中文的问题解决
最近在基于python3.6.5 的环境使用scrapy框架爬虫获取json数据,返回的数据是unicode格式的,在spider里面的parse接口中打印response.text出来如下: cla ...
- VS2015解决非Unicode编码包含中文字段无法编译的问题
用VS2015打开并编译,定位到编译错误的文件(.cs而不是可视化编辑视图) 文件--高级保存选项--编码 改为 Unicode-代码页1200 这样不论用VS2015/2013/2012/2010 ...
随机推荐
- 浏览器 extension和plugin的区别[来自知乎]
"扩展"和"插件",其实都是软件组件的一种形式,Chrome 只不过是把两种类型的组件分别给与了专有名称,一个叫"扩展",另一个叫" ...
- 【weka】分类,cross-validation,数据
一.分类classifier 如何利用weka里的类对数据集进行分类,要对数据集进行分类,第一步要指定数据集中哪一列做为类别,如果这一步忘记了(事实上经常会忘记)会出现“Class index is ...
- selenium-python:登录网站并签到
测试网站的图像验证码统一设置成了:121 Elements中定位元素比较费眼睛~~ import time from selenium import webdriver # import os use ...
- 梯度消失与梯度爆炸 ==> 如何选择随机初始权重
梯度消失与梯度爆炸 当训练神经网络时,导数或坡度有时会变得非常大或非常小,甚至以指数方式变小,这加大了训练的难度 这里忽略了常数项b.为了让z不会过大或者过小,思路是让w与n有关,且n越大,w应该越小 ...
- 2.keras实现-->深度学习用于文本和序列
1.将文本数据预处理为有用的数据表示 将文本分割成单词(token),并将每一个单词转换为一个向量 将文本分割成单字符(token),并将每一个字符转换为一个向量 提取单词或字符的n-gram(tok ...
- cmd重启服务器,有时不想去机房,并且远程桌面连接登录不上了
有时不想去机房,并且远程桌面连接登录不上了,需要远程重启服务器的,这时可以使用命令行方式远程重启.在cmd命令行状态下输入:shutdown -r -m \\192.168.1.10 -t 0 -f ...
- mysql套接字文件
- 原生http模块与使用express框架对比
node的http创建服务与利用Express框架有何不同 原生http模块与使用express框架对比: const http = require("http"); let se ...
- GIC400简介
GIC400是arm公司的中断控制IP,提供axi4接口,主要功能: 1)中断的使能(enable,mask); 中断的优先级(poriority); 中断的触发条件(level-sensitive ...
- zw版【转发·台湾nvp系列Delphi例程】HALCON SigmaImage1
zw版[转发·台湾nvp系列Delphi例程]HALCON SigmaImage1 procedure TForm1.Button1Click(Sender: TObject);var img, im ...