train_test_split, 关于随机抽样和分层抽样
https://zhuanlan.zhihu.com/p/49991313
在将样本数据分成训练集和测试集的时候,应当谨慎地考虑一下是采用纯随机抽样,还是分层抽样。
通常,数据集如果足够大,纯随机抽样的方式,将样本数据分成两个子集是没有太大的问题。
如果不是,纯随机抽样肯可能会导致抽样数据偏差,影响训练效果,降低预测模型预测的准确性。
设想调查公司需要做1000份抽样调查,调查的问题和性别可能有较大的相关性。如果想让调查结果代表全国男性和女性对这些问题的看法,假设全国人口男女比例大致为60:40,那么在1000份问卷也应当尽量保持男女比例达到同样的比例,即参加问卷调查的男女数差不多是600和400。
这个就是分层抽样。
如果参加问卷的男女数比例很不一样,比如女性占到了60%或更多,那么调查结伦就会出现重大偏差。
使用sklearn.model_selection.train_test_split,参数stratify即用来指定按照某一特征进行分层抽样,生成训练集和测试集。
看一下随机抽样和分层抽样时,按照某一特征的取值,在训练集的占比情况。
income_count = housing['income_cat'].value_counts().sort_index()
print('\nAfter categorized:\n{}'.format(income_count))
income_count.plot.bar()
plt.show()
print('Overall dataset, distribution of each category: (%)')
print(income_count/len(housing)*100)
# random split
train_set, test_set = train_test_split(housing, random_state=42)
train_set_income_count = train_set['income_cat'].value_counts().sort_index()
print('\nRandom split train dataset, distribution: (%)')
print(train_set_income_count/len(train_set)*100)
# stratify split
train_set, test_set = train_test_split(housing,
stratify=housing['income_cat'], random_state=42)
train_set_income_count = train_set['income_cat'].value_counts().sort_index()
print('\nStartify split train dataset, distribution: (%)')
print(train_set_income_count/len(train_set)*100)
得到结果如下:
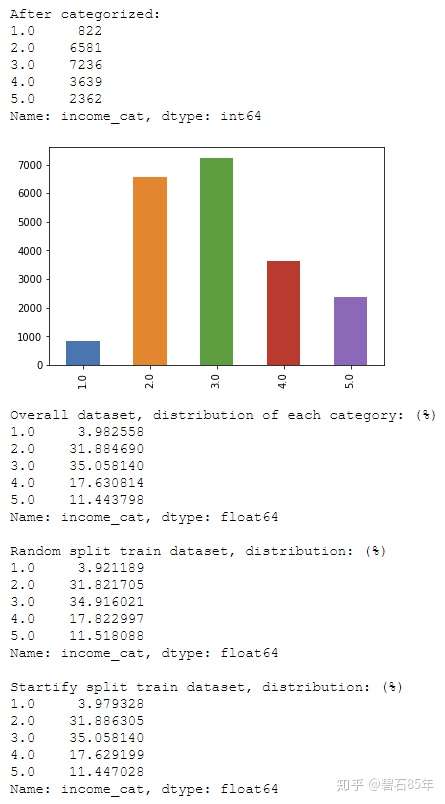
可以看到分层抽样所分出来的训练集(和测试集)数据在关键特征上具有和总体数据集上基本一致的分布。
因此采用分层抽样来生成训练集和测试集将会更严谨。
train_test_split, 关于随机抽样和分层抽样的更多相关文章
- (数据科学学习手札27)sklearn数据集分割方法汇总
一.简介 在现实的机器学习任务中,我们往往是利用搜集到的尽可能多的样本集来输入算法进行训练,以尽可能高的精度为目标,但这里便出现一个问题,一是很多情况下我们不能说搜集到的样本集就能代表真实的全体,其分 ...
- 【机器学习算法-python实现】採样算法的简单实现
1.背景 採样算法是机器学习中比較经常使用,也比較easy实现的(出去分层採样).经常使用的採样算法有下面几种(来自百度知道): 一.单纯随机抽样(simple random samp ...
- SAS随机抽样以及程序初始环境
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本来转载于SAS随机抽样 在统计研究中,针对容 ...
- 随机抽样一致性算法(RANSAC)示例及源代码
作者:王先荣 大约在两年前翻译了<随机抽样一致性算法RANSAC>,在文章的最后承诺写该算法的C#示例程序.可惜光阴似箭,转眼许久才写出来,实在抱歉.本文将使用随机抽样一致性算法来来检测直 ...
- 随机抽样一致性算法(RANSAC)
本文翻译自维基百科,英文原文地址是:http://en.wikipedia.org/wiki/ransac,如果您英语不错,建议您直接查看原文. RANSAC是"RANdom SAmple ...
- sklearn.model_selection 的 train_test_split作用
train_test_split函数用于将数据划分为训练数据和测试数据. train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train_data和test_data ...
- train_test_split数据切分
train_test_split 数据切分 格式: X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_d ...
- sklearn 的train_test_split
train_test_split函数用于将矩阵随机划分为训练子集和测试子集,并返回划分好的训练集测试集样本和训练集测试集标签. 格式: from sklearn.model_selection imp ...
- 训练集测试集划分 train_test_split(X, y, stratify=y)
from sklearn.model_selecting import train_test_spilt() 参数stratify: 依据标签y,按原数据y中各类比例,分配给train和test,使得 ...
随机推荐
- python与VScode
用VScode写python是非常方便的.vscode是一个功能非常强大的编辑器,下面介绍大致的使用方法: 下载安装python,配置环境变量. 下载安装VScode(vscode会自动连接pytho ...
- Python easyGUI 登录框 非空验证
import easygui as g msg='欢迎注册' title='注册' fieldNames=['*用户名','*密码','*重复密码','真实姓名','手机号','QQ','e-mail ...
- 【GIS】Cesium GLTF
cd D:\GISSoft\3DsMax2017\COLLADA2GLTF-v2.1.4-windows-Release-x64 COLLADA2GLTF-bin.exe -f tree05.DAE ...
- 【代码审计】iCMS_v7.0.7 admincp.app.php页面存在SQL注入漏洞分析
0x00 环境准备 iCMS官网:https://www.icmsdev.com 网站源码版本:iCMS-v7.0.7 程序源码下载:https://www.icmsdev.com/downloa ...
- 【代码审计】eduaskcms_v1.0.7前台存储型XSS漏洞分析
0x00 环境准备 eduaskcms官网:https://www.eduaskcms.xin 网站源码版本:eduaskcms-1.0.7 程序源码下载:https://www.eduaskcm ...
- Kafka(一)-- 初体验
一.概念 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据. 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素. 这些 ...
- IOS音频1:之采用四种方式播放音频文件(一)AudioToolbox AVFoundation OpenAL AUDIO QUEUE
本文转载至 http://blog.csdn.net/u014011807/article/details/40187737 在本卷你可以学到什么? 采用四种方法设计应用于各种场合的音频播放器: 基于 ...
- Eclipse新建动态web工程项目出现红叉解决方案
问题描述:之前新建动态web工程一直没有问题,今天新建一个项目后项目名称上突然出现小红叉,子目录文件没有红叉. 解决过程:一开始想到的就是编译器的level设置,调整了一下,仍然没有解决. 然后在标记 ...
- bigdecimal 与long int 之间转换
BigDecimal与Long.int之间的互换 在实际开发过程中BigDecimal是一个经常用到的数据类型,它和int Long之间可以相互转换. 转换关系如下代码展示: int 转换成 BigD ...
- source.android.google && developer.android.google
https://source.android.google.cn/ https://developer.android.google.cn/ https://source.android.com/co ...