MapReduce分组
- 分组:相同key的value进行分组
例子:如下输入输出,右边的第一列没有重复值,第二列取得是当第一列相同时第二例取最大值
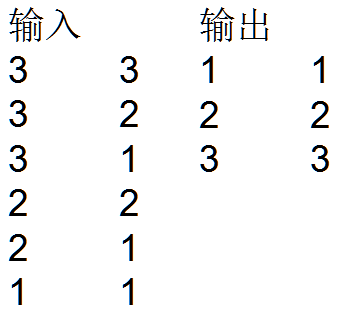
分析:首先确定<k3,v3>,k3的选择两种方式,
方法1.前两列都作为k3
方法2.两列分别是k3和v3,此种情况的k2和v2分别是那些,第一列为k2,第二列为v2,但是最后如何无法转化为k3,v3呢,思路是从v2s中取值最大的,此种情况不能取值。
第一部分:方法二达到任务目的
(1)自定义Mapper
private static class MyMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{
IntWritable k2= new IntWritable();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
k2.set(Integer.parseInt(splited[0]));
v2.set(Integer.parseInt(splited[1]));
context.write(k2, v2);
}
}
(2)自定义Reduce
//按照k2進行排序,分組(分为3各组,reduce函数被调用3次,分几组调用几次)
//分组为3-{3,2,1}, 2-{2,1},1-{1}
private static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
IntWritable v3 = new IntWritable();
@Override
protected void reduce(IntWritable k2, Iterable<IntWritable> v2s,
Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
context.write(k2, v3);
}
}
(3)组合MapReduce
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), GroupTest.class.getSimpleName());
job.setJarByClass(GroupTest.class);
//1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//2.自定义mapper
//job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(TrafficWritable.class);
//3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘
job.waitForCompletion(true);
}
由此,完整的代码如下:
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class GroupTest {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), GroupTest.class.getSimpleName());
job.setJarByClass(GroupTest.class);
//1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//2.自定义mapper
//job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(TrafficWritable.class); //3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘 job.waitForCompletion(true);
}
private static class MyMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{
IntWritable k2= new IntWritable();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
k2.set(Integer.parseInt(splited[0]));
v2.set(Integer.parseInt(splited[1]));
context.write(k2, v2);
}
}
//按照k2進行排序,分組(分为3各组,reduce函数被调用3次,分几组调用几次)
//分组为3-{3,2,1}, 2-{2,1},1-{1}
private static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
IntWritable v3 = new IntWritable();
@Override
protected void reduce(IntWritable k2, Iterable<IntWritable> v2s,
Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
context.write(k2, v3);
}
}
}
最值得MapReduce代码
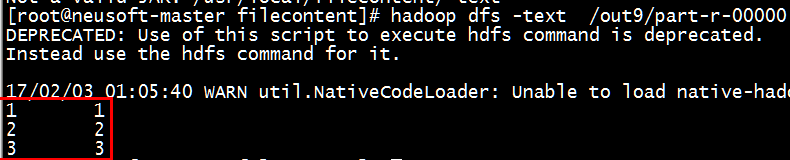
(4)测试代码运行结果
- [root@neusoft-master filecontent]# hadoop jar GroupTest.jar /neusoft/twoint /out9
- [root@neusoft-master filecontent]# hadoop jar -text /out9/part-r-00000
- [root@neusoft-master filecontent]# hadoop dfs -text /out9/part-r-00000
第二部分:方法一达到任务目的
前两列都作为k3,无v3,由此类推,k2也是前两列
但是如果采用默认分组的话,上述数据集分为6组,无法达到同样的数值取得最大值的目的。
由此,利用Mapreduce的自定义分组规则,使得第一列相同的数值可以在一个组里面,从而正确的分组。
MapReduce提供了job.setGroupingComparatorClass(cls);其中cls是自定义分组的类
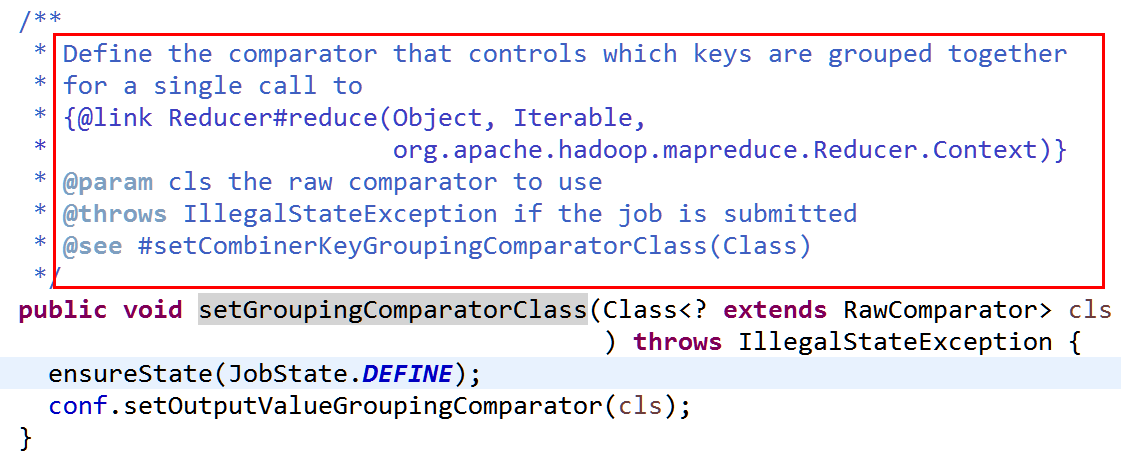
(1) 从源代码可知,该类需要继承RawComparator类,自定义分组代码如下:
//分组比较--自定义分组
private static class MyGroupingComparator implements RawComparator {
public int compare(Object o1, Object o2) {
return 0;//默认的比较方法
}
//byte[] b1 表示第一个参数的输入字节表示,byte[] b2表示第二个参数的输入字节表示
//b1 The first byte array. 第一个字节数组,
//b1表示前8个字节,b2表示后8个字节,字节是按次序依次比较的
//s1 The position index in b1. The object under comparison's starting index.第一列开始位置
//l1 The length of the object in b1.第一列长度 ,在这里表示长度8
//提供的数据集中的k2一共48个字节,k2的每一行的TwoInt类型表示8字节(t1和t2分别为4字节)
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//compareBytes是按字节比较的方法,其中k2表示的是两列,第一列比较,第二例不比较
//第一个字节数组的前四个字节和第二个字节数组的前四个字节比较
//{3,3},{3,2},{3,1},{2,2},{2,1},{1,1}
//比较上述六组的每组的第一个数字,也就是比较twoint中得t1数值
//现在就根据t1可分成3个组了{3,(3,2,1)}{2,(2,1)}{1,1}
//之后再从v2中取出最大值
return WritableComparator.compareBytes(b1, s1, l1-4, b2, s2, l2-4);
} }
(2)主函数中调用
//当没有下面的自定义分组的话,会调用k2的compareto方法执行k2的比较,如果自定义了分组类则使用自定义分组类
job.setGroupingComparatorClass(MyGroupingComparator.class);
(3)根据比较函数个字段的含义,可以得到v2的类型为intwritable,而不是nullwritable,v2是由第二列的数组成的集合
Mapper函数如下:
private static class MyMapper extends
Mapper<LongWritable, Text, TwoInt, IntWritable> {
//这里的v2需要改为IntWritable而不是nullwritable
TwoInt K2 = new TwoInt();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, TwoInt, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
K2.set(Integer.parseInt(splited[0]), Integer.parseInt(splited[1]));
v2.set(Integer.parseInt(splited[1])); //要比较第二列,需要将第二列的值赋值为v2
context.write(K2, v2);
}
}
(4)k3和v3的类型为reduce输出的类型,均为intwritable类型,但是如何根据得到的v2去统计其中相同key的value中得最大值呢?
private static class MyReducer extends
Reducer<TwoInt, IntWritable, IntWritable, IntWritable> {//k2,v2s,k3,v3
IntWritable k3 = new IntWritable();
IntWritable v3 = new IntWritable();
@Override
protected void reduce(
TwoInt k2,
Iterable<IntWritable> v2s,
Reducer<TwoInt, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
k3.set(k2.t1);//k2的第一列作为k3,因为k2为Twoint类型
context.write(k3,v3);
}
}
最终的代码如下:
package Mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Group2Test {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(),
Group2Test.class.getSimpleName());
job.setJarByClass(Group2Test.class);
// 1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 2.自定义mapper
job.setMapperClass(MyMapper.class);
//这里的k2,v2和k3,v3不同,需要显式定义k2和v2类型
job.setMapOutputKeyClass(TwoInt.class);
job.setMapOutputValueClass(IntWritable.class); //当没有下面的自定义分组的话,会调用k2的compareto方法执行k2的比较,如果自定义了分组类则使用自定义分组类
job.setGroupingComparatorClass(MyGroupingComparator.class); // 3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
// 4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
//分组比较--自定义分组
private static class MyGroupingComparator implements RawComparator {
public int compare(Object o1, Object o2) {
return 0;//默认的比较方法
}
//byte[] b1 表示第一个参数的输入字节表示,byte[] b2表示第二个参数的输入字节表示
//b1 The first byte array. 第一个字节数组,
//b1表示前8个字节,b2表示后8个字节,字节是按次序依次比较的
//s1 The position index in b1. The object under comparison's starting index.第一列开始位置
//l1 The length of the object in b1.第一列长度 ,在这里表示长度8
//提供的数据集中的k2一共48个字节,k2的每一行的TwoInt类型表示8字节(t1和t2分别为4字节)
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//compareBytes是按字节比较的方法,其中k2表示的是两列,第一列比较,第二例不比较
//第一个字节数组的前四个字节和第二个字节数组的前四个字节比较
//{3,3},{3,2},{3,1},{2,2},{2,1},{1,1}
//比较上述六组的每组的第一个数字,也就是比较twoint中得t1数值
//现在就根据t1可分成3个组了{3,(3,2,1)}{2,(2,1)}{1,1}
//之后再从v2中取出最大值
return WritableComparator.compareBytes(b1, s1, l1-4, b2, s2, l2-4);
} } private static class MyMapper extends
Mapper<LongWritable, Text, TwoInt, IntWritable> {
//这里的v2需要改为IntWritable而不是nullwritable
TwoInt K2 = new TwoInt();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, TwoInt, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
K2.set(Integer.parseInt(splited[0]), Integer.parseInt(splited[1]));
v2.set(Integer.parseInt(splited[1]));
context.write(K2, v2);
}
} private static class MyReducer extends
Reducer<TwoInt, IntWritable, IntWritable, IntWritable> {//k2,v2s,k3,v3
IntWritable k3 = new IntWritable();
IntWritable v3 = new IntWritable();
@Override
protected void reduce(
TwoInt k2,
Iterable<IntWritable> v2s,
Reducer<TwoInt, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
k3.set(k2.t1);//k2的第一列作为k3,因为k2为Twoint类型
context.write(k3,v3);
}
} private static class TwoInt implements WritableComparable<TwoInt> {
public int t1;
public int t2; public void write(DataOutput out) throws IOException {
out.writeInt(t1);
out.writeInt(t2);
} public void set(int t1, int t2) {
this.t1 = t1;
this.t2 = t2;
} public void readFields(DataInput in) throws IOException {
this.t1 = in.readInt();
this.t2 = in.readInt();
} public int compareTo(TwoInt o) {
if (this.t1 == o.t1) { // 當第一列相等的時候,第二列升序排列
return this.t2 - o.t2;
}
return this.t1 - o.t1;// 當第一列不相等的時候,按第一列升序排列
}
@Override
public String toString() {
return t1 + "\t" + t2;
}
}
}
方法1求最值
测试并运行结果如下:
[root@neusoft-master filecontent]# hadoop dfs -text /out9/part-r-00000
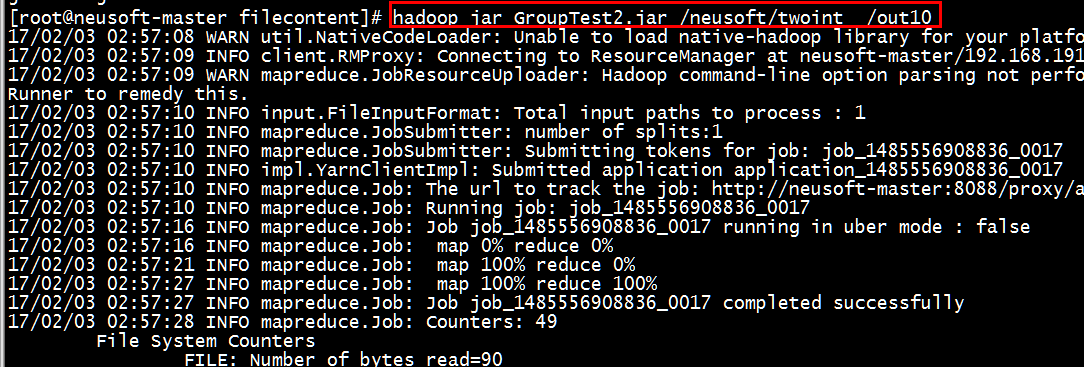
[root@neusoft-master filecontent]# hadoop dfs -text /out10/part-r-00000
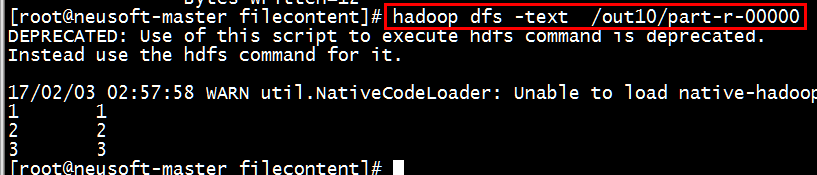
结果是正确无误的。
END~
MapReduce分组的更多相关文章
- MongoDB 的 MapReduce 大数据统计统计挖掘
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- MongoDB的MapReduce用法及php示例代码
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- mongo14-----group,aggregate,mapReduce
group,aggregate,mapReduce 分组统计: group() 简单聚合: aggregate() 强大统计: mapReduce() db.collection.group(docu ...
- 关于MapReduce中自定义分组类(三)
Job类 /** * Define the comparator that controls which keys are grouped together * for a single ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- C#使用MapReduce实现对分片数据的分组
事由:mongodb已经进行数据分片,这样就不能使用一些方法就不能使用,例如eval,$group如果尝试使用mongodb会提示 Error: { , "errmsg" : &q ...
随机推荐
- selenium +chrome headless Manual 模式渲染网页
可以看看这个里面的介绍,写得很好.https://duo.com/blog/driving-headless-chrome-with-python from selenium import webdr ...
- [scala] scala 对象(六)
1.单例对象和伴生对象 2.定义单利对象的apply方法可不通过构造器直接创建对象 3.extends 来扩展单例对象 4.枚举实现 /** * 单例对象 * * @author xuejz * @d ...
- android:versionCode和android:versionName 用途(转)
转自:http://blog.csdn.net/wh_19910525/article/details/8660416 Android的版本可以在androidmainfest.xml中定义,主要有a ...
- XMPP协议实现即时通讯底层书写 (一)--从RFC6121阅读開始
Extensible Messaging and Presence Protocol (XMPP): Instant Messaging and Presence ok,额瑞巴蒂,说好的阅读RFC61 ...
- 8 -- 深入使用Spring -- 1...1Bean后处理器
8.1.1 Bean后处理器(BeanPostProcessor) Bean后处理器主要负责对容器中其他Bean执行后处理,例如为容器中的目标Bean生成代理等. Bean后处理器会在Bean实例创建 ...
- Weblogic集群部署
有些事情不去尝试,注定是失败,如果预知90%的失败仍然去尝试了,那也会从中学到很多,何况仅靠那10%的可能性也会成功 weblogic安装后 1.打开Configuration Wizard 2.创建 ...
- 【代码审计】Cscms_v4.1 任意文件删除漏洞实例
环境搭建: CSCMS :http://www.chshcms.com/ 网站源码版本:Cscms_v4.1正式版(发布日期:2017-06-05) 程序源码下载:https://github.com ...
- 【RF库XML测试】Get Elements
Name:Get ElementsSource:XML <test library>Arguments:[ source | xpath ]Returns a list of elemen ...
- 使用 requests 配置代理服务
(1) 如果我们一直用同一个IP去请求同一个网站上的网页,久了之后可能会被该网站服务器屏蔽,因此我们可以使用代理IP来发起请求,代理实际上指的就是代理服务器(2) 当我们使用代理IP发起请求时,服务器 ...
- weblogic12C出现“java.lang.ArrayIndexOutOfBoundsException: 48188”
最近将10G的一个项目转移到12C出现数组越界的问题: 解决办法: jaxen-1.1.1.jarxom-1.0.jaricu4j-2.6.1.jar 把项目中这三个jar包删除后就可以正常部署了 ...