MapReduce分组
- 分组:相同key的value进行分组
例子:如下输入输出,右边的第一列没有重复值,第二列取得是当第一列相同时第二例取最大值
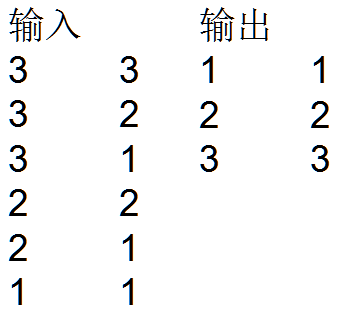
分析:首先确定<k3,v3>,k3的选择两种方式,
方法1.前两列都作为k3
方法2.两列分别是k3和v3,此种情况的k2和v2分别是那些,第一列为k2,第二列为v2,但是最后如何无法转化为k3,v3呢,思路是从v2s中取值最大的,此种情况不能取值。
第一部分:方法二达到任务目的
(1)自定义Mapper
private static class MyMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{
IntWritable k2= new IntWritable();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
k2.set(Integer.parseInt(splited[0]));
v2.set(Integer.parseInt(splited[1]));
context.write(k2, v2);
}
}
(2)自定义Reduce
//按照k2進行排序,分組(分为3各组,reduce函数被调用3次,分几组调用几次)
//分组为3-{3,2,1}, 2-{2,1},1-{1}
private static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
IntWritable v3 = new IntWritable();
@Override
protected void reduce(IntWritable k2, Iterable<IntWritable> v2s,
Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
context.write(k2, v3);
}
}
(3)组合MapReduce
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), GroupTest.class.getSimpleName());
job.setJarByClass(GroupTest.class);
//1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//2.自定义mapper
//job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(TrafficWritable.class);
//3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘
job.waitForCompletion(true);
}
由此,完整的代码如下:
package Mapreduce; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class GroupTest {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(), GroupTest.class.getSimpleName());
job.setJarByClass(GroupTest.class);
//1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//2.自定义mapper
//job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(TrafficWritable.class); //3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//job.setOutputFormatClass(TextOutputFormat.class);//对输出的数据格式化并写入磁盘 job.waitForCompletion(true);
}
private static class MyMapper extends Mapper<LongWritable, Text, IntWritable, IntWritable>{
IntWritable k2= new IntWritable();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
k2.set(Integer.parseInt(splited[0]));
v2.set(Integer.parseInt(splited[1]));
context.write(k2, v2);
}
}
//按照k2進行排序,分組(分为3各组,reduce函数被调用3次,分几组调用几次)
//分组为3-{3,2,1}, 2-{2,1},1-{1}
private static class MyReducer extends Reducer<IntWritable, IntWritable, IntWritable, IntWritable>{
IntWritable v3 = new IntWritable();
@Override
protected void reduce(IntWritable k2, Iterable<IntWritable> v2s,
Reducer<IntWritable, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
context.write(k2, v3);
}
}
}
最值得MapReduce代码
(4)测试代码运行结果
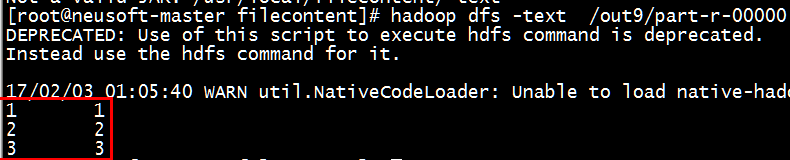
- [root@neusoft-master filecontent]# hadoop jar GroupTest.jar /neusoft/twoint /out9
- [root@neusoft-master filecontent]# hadoop jar -text /out9/part-r-00000
- [root@neusoft-master filecontent]# hadoop dfs -text /out9/part-r-00000
第二部分:方法一达到任务目的
前两列都作为k3,无v3,由此类推,k2也是前两列
但是如果采用默认分组的话,上述数据集分为6组,无法达到同样的数值取得最大值的目的。
由此,利用Mapreduce的自定义分组规则,使得第一列相同的数值可以在一个组里面,从而正确的分组。
MapReduce提供了job.setGroupingComparatorClass(cls);其中cls是自定义分组的类
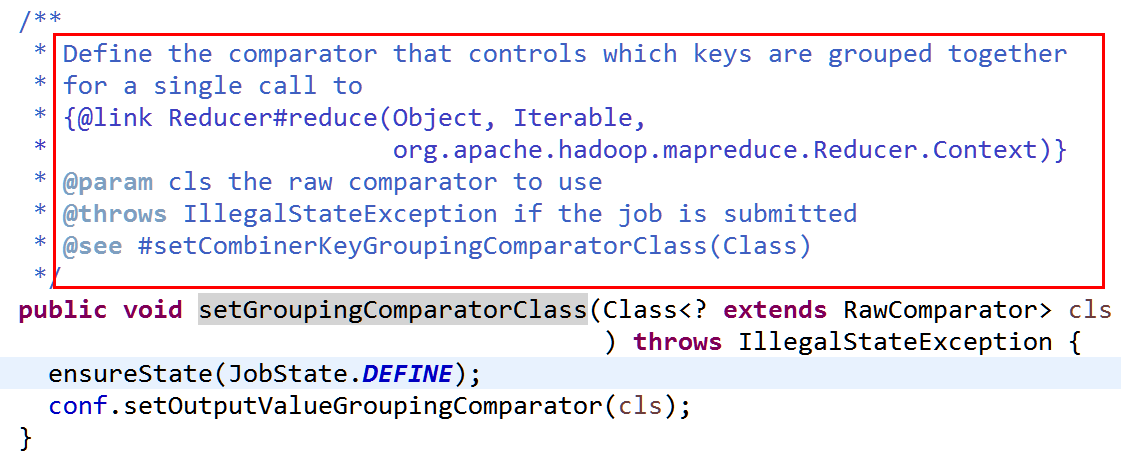
(1) 从源代码可知,该类需要继承RawComparator类,自定义分组代码如下:
//分组比较--自定义分组
private static class MyGroupingComparator implements RawComparator {
public int compare(Object o1, Object o2) {
return 0;//默认的比较方法
}
//byte[] b1 表示第一个参数的输入字节表示,byte[] b2表示第二个参数的输入字节表示
//b1 The first byte array. 第一个字节数组,
//b1表示前8个字节,b2表示后8个字节,字节是按次序依次比较的
//s1 The position index in b1. The object under comparison's starting index.第一列开始位置
//l1 The length of the object in b1.第一列长度 ,在这里表示长度8
//提供的数据集中的k2一共48个字节,k2的每一行的TwoInt类型表示8字节(t1和t2分别为4字节)
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//compareBytes是按字节比较的方法,其中k2表示的是两列,第一列比较,第二例不比较
//第一个字节数组的前四个字节和第二个字节数组的前四个字节比较
//{3,3},{3,2},{3,1},{2,2},{2,1},{1,1}
//比较上述六组的每组的第一个数字,也就是比较twoint中得t1数值
//现在就根据t1可分成3个组了{3,(3,2,1)}{2,(2,1)}{1,1}
//之后再从v2中取出最大值
return WritableComparator.compareBytes(b1, s1, l1-4, b2, s2, l2-4);
} }
(2)主函数中调用
//当没有下面的自定义分组的话,会调用k2的compareto方法执行k2的比较,如果自定义了分组类则使用自定义分组类
job.setGroupingComparatorClass(MyGroupingComparator.class);
(3)根据比较函数个字段的含义,可以得到v2的类型为intwritable,而不是nullwritable,v2是由第二列的数组成的集合
Mapper函数如下:
private static class MyMapper extends
Mapper<LongWritable, Text, TwoInt, IntWritable> {
//这里的v2需要改为IntWritable而不是nullwritable
TwoInt K2 = new TwoInt();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, TwoInt, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
K2.set(Integer.parseInt(splited[0]), Integer.parseInt(splited[1]));
v2.set(Integer.parseInt(splited[1])); //要比较第二列,需要将第二列的值赋值为v2
context.write(K2, v2);
}
}
(4)k3和v3的类型为reduce输出的类型,均为intwritable类型,但是如何根据得到的v2去统计其中相同key的value中得最大值呢?
private static class MyReducer extends
Reducer<TwoInt, IntWritable, IntWritable, IntWritable> {//k2,v2s,k3,v3
IntWritable k3 = new IntWritable();
IntWritable v3 = new IntWritable();
@Override
protected void reduce(
TwoInt k2,
Iterable<IntWritable> v2s,
Reducer<TwoInt, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
k3.set(k2.t1);//k2的第一列作为k3,因为k2为Twoint类型
context.write(k3,v3);
}
}
最终的代码如下:
package Mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Group2Test {
public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration(),
Group2Test.class.getSimpleName());
job.setJarByClass(Group2Test.class);
// 1.自定义输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 2.自定义mapper
job.setMapperClass(MyMapper.class);
//这里的k2,v2和k3,v3不同,需要显式定义k2和v2类型
job.setMapOutputKeyClass(TwoInt.class);
job.setMapOutputValueClass(IntWritable.class); //当没有下面的自定义分组的话,会调用k2的compareto方法执行k2的比较,如果自定义了分组类则使用自定义分组类
job.setGroupingComparatorClass(MyGroupingComparator.class); // 3.自定义reduce
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
// 4.自定义输出路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
//分组比较--自定义分组
private static class MyGroupingComparator implements RawComparator {
public int compare(Object o1, Object o2) {
return 0;//默认的比较方法
}
//byte[] b1 表示第一个参数的输入字节表示,byte[] b2表示第二个参数的输入字节表示
//b1 The first byte array. 第一个字节数组,
//b1表示前8个字节,b2表示后8个字节,字节是按次序依次比较的
//s1 The position index in b1. The object under comparison's starting index.第一列开始位置
//l1 The length of the object in b1.第一列长度 ,在这里表示长度8
//提供的数据集中的k2一共48个字节,k2的每一行的TwoInt类型表示8字节(t1和t2分别为4字节)
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
//compareBytes是按字节比较的方法,其中k2表示的是两列,第一列比较,第二例不比较
//第一个字节数组的前四个字节和第二个字节数组的前四个字节比较
//{3,3},{3,2},{3,1},{2,2},{2,1},{1,1}
//比较上述六组的每组的第一个数字,也就是比较twoint中得t1数值
//现在就根据t1可分成3个组了{3,(3,2,1)}{2,(2,1)}{1,1}
//之后再从v2中取出最大值
return WritableComparator.compareBytes(b1, s1, l1-4, b2, s2, l2-4);
} } private static class MyMapper extends
Mapper<LongWritable, Text, TwoInt, IntWritable> {
//这里的v2需要改为IntWritable而不是nullwritable
TwoInt K2 = new TwoInt();
IntWritable v2= new IntWritable();
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, TwoInt, IntWritable>.Context context)
throws IOException, InterruptedException {
String[] splited = value.toString().split("\t");
K2.set(Integer.parseInt(splited[0]), Integer.parseInt(splited[1]));
v2.set(Integer.parseInt(splited[1]));
context.write(K2, v2);
}
} private static class MyReducer extends
Reducer<TwoInt, IntWritable, IntWritable, IntWritable> {//k2,v2s,k3,v3
IntWritable k3 = new IntWritable();
IntWritable v3 = new IntWritable();
@Override
protected void reduce(
TwoInt k2,
Iterable<IntWritable> v2s,
Reducer<TwoInt, IntWritable, IntWritable, IntWritable>.Context context)
throws IOException, InterruptedException {
int max=Integer.MIN_VALUE;
for (IntWritable v2 : v2s) {
if (v2.get()>max) {
max=v2.get();
}
}
//每个组求得一个最大值可得到结果的序列
v3.set(max);
k3.set(k2.t1);//k2的第一列作为k3,因为k2为Twoint类型
context.write(k3,v3);
}
} private static class TwoInt implements WritableComparable<TwoInt> {
public int t1;
public int t2; public void write(DataOutput out) throws IOException {
out.writeInt(t1);
out.writeInt(t2);
} public void set(int t1, int t2) {
this.t1 = t1;
this.t2 = t2;
} public void readFields(DataInput in) throws IOException {
this.t1 = in.readInt();
this.t2 = in.readInt();
} public int compareTo(TwoInt o) {
if (this.t1 == o.t1) { // 當第一列相等的時候,第二列升序排列
return this.t2 - o.t2;
}
return this.t1 - o.t1;// 當第一列不相等的時候,按第一列升序排列
}
@Override
public String toString() {
return t1 + "\t" + t2;
}
}
}
方法1求最值
测试并运行结果如下:
[root@neusoft-master filecontent]# hadoop dfs -text /out9/part-r-00000
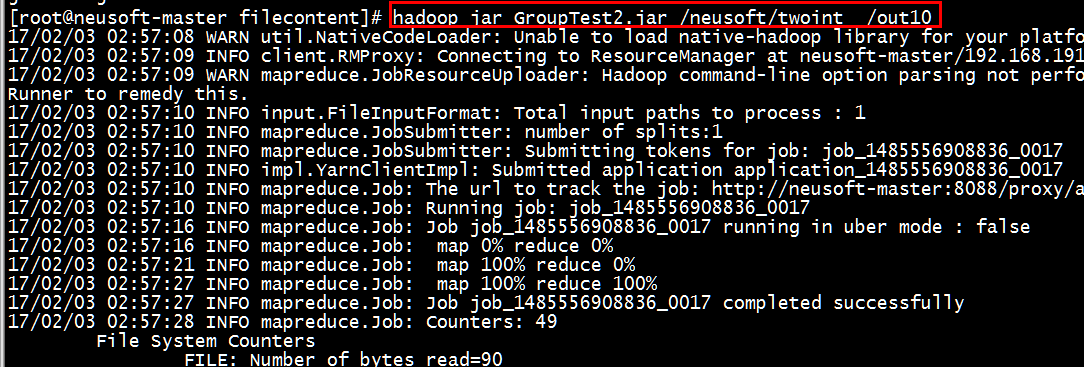
[root@neusoft-master filecontent]# hadoop dfs -text /out10/part-r-00000
结果是正确无误的。
END~
MapReduce分组的更多相关文章
- MongoDB 的 MapReduce 大数据统计统计挖掘
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- MongoDB的MapReduce用法及php示例代码
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- mongo14-----group,aggregate,mapReduce
group,aggregate,mapReduce 分组统计: group() 简单聚合: aggregate() 强大统计: mapReduce() db.collection.group(docu ...
- 关于MapReduce中自定义分组类(三)
Job类 /** * Define the comparator that controls which keys are grouped together * for a single ...
- Hadoop学习笔记—11.MapReduce中的排序和分组
一.写在之前的 1.1 回顾Map阶段四大步骤 首先,我们回顾一下在MapReduce中,排序和分组在哪里被执行: 从上图中可以清楚地看出,在Step1.4也就是第四步中,需要对不同分区中的数据进行排 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- Hadoop Mapreduce分区、分组、二次排序
1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了partitioner以将map的结果送往指定reducer的过程: map - partiti ...
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- C#使用MapReduce实现对分片数据的分组
事由:mongodb已经进行数据分片,这样就不能使用一些方法就不能使用,例如eval,$group如果尝试使用mongodb会提示 Error: { , "errmsg" : &q ...
随机推荐
- trim思考
今天发现后台订单商品名称没有的时候出现了HTML代码,然后看了一下源代码(下图是简化版本的) <?php $name = trim('<span style="font-weig ...
- Apache 配置文件详解
0x01 禁止目录列表访问 () 备份httpd.conf配置文件,修改内容: <Directory "/web"> Options FollowSymLinks Al ...
- iOS开发-VFL初窥
VFL是苹果为了简化Autolayout的编码而推出的抽象语言,在上一篇博客中我们发现如果使用NSLayoutConstraint来添加约束是非常繁琐的. 一个简单的Frame需要添加四个NSLayo ...
- iOS开发-- 使用VVDocumenter-Xcode添加代码注释
在开发Java代码过程中,我们只需在Eclipse中敲/**即可生成字段.方法对应的文档,简单便捷. 在Xcode如果想添加文档注释,需要花费很多时间,有没有简单.快速的方法搞定这一切? 在网上搜索了 ...
- 解决“Connection to https://dl-ssl.google.com refused”问题
相信一些人刚开始搞android的安装开发环境的时候会遇到:Failed to fectch URl https://dl-ssl.google.com/android/repository/addo ...
- php-fpm配置文件
php-fpm配置文件 1.php-5.2的php-fpm <?xml version="1.0" ?> <configuration> <secti ...
- .net 将DLL程序集生成到指定目录中
.在程序集右键属性 .在程序集属性界面中找到生成事件 在预先生成事件命令行添加: IF NOT EXIST "$(ProjectDir)..\Bin" MD "$(Pro ...
- 【Linux】 基于centos7.2 安装 LAMP
服务器选择的阿里云ecs服务器,系统centos7.2版 一.连接服务器,检查当前系统环境 1.查看centos版本 [root@iZuf682jnxmszwd2gdvzh0Z ~]# cat /et ...
- HTTP协议剖析 (附HttpWatch工具监控网络请求)
工具:HttpWatch Prov7.2.13破解版(带正版key) HTTP协议概述 思考2个要点: 第一:浏览器和服务器是通过什么连接的 第二:这种连接方式是怎么实现的 通过Interne ...
- sencha touch 扩展官方NavigationView 灵活添加按钮组,导航栏,自由隐藏返回按钮(2014-5-15)
扩展视频讲解:http://www.cnblogs.com/mlzs/p/3652094.html官方NavigationView详解:http://www.cnblogs.com/mlzs/p/35 ...