深入了解STL中set与hash_set,hash表基础
一,set和hash_set简介
在STL中,set是以红黑树(RB-Tree)作为底层数据结构的,hash_set是以哈希表(Hash table)作为底层数据结构的。set可以在时间复杂度为O(logN)的情况下插入,删除和查找数据。hash_set操作的时间度则比较复杂,取决于哈希函数和哈希表的负载情况。
二,SET使用范例(hash_set类似)
#include <set>
#include <ctime>
#include <cstdio>
using namespace std; int main()
{
const int MAXN = ;
int a[MAXN];
int i;
srand(time(NULL));
for (i = ; i < MAXN; ++i)
a[i] = rand() % (MAXN * ); set<int> iset;
set<int>::iterator pos; //插入数据 insert()有三种重载
iset.insert(a, a + MAXN); //当前集合中个数 最大容纳数据量
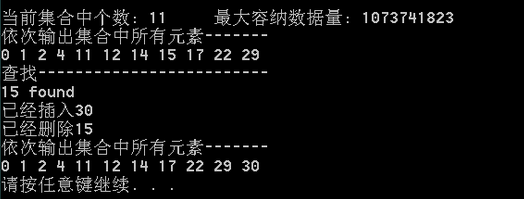
printf("当前集合中个数: %d 最大容纳数据量: %d\n", iset.size(), iset.max_size()); //依次输出
printf("依次输出集合中所有元素-------\n");
for (pos = iset.begin(); pos != iset.end(); ++pos)
printf("%d ", *pos);
putchar('\n'); //查找
int findNum = MAXN;
printf("查找 %d是否存在-----------------------\n", findNum);
pos = iset.find(findNum);
if (pos != iset.end())
printf("%d 存在\n", findNum);
else
printf("%d 不存在\n", findNum); //在最后位置插入数据,如果给定的位置不正确,会重新找个正确的位置并返回该位置
pos = iset.insert(--iset.end(), MAXN * );
printf("已经插入%d\n", *pos); //删除
iset.erase(MAXN);
printf("已经删除%d\n", MAXN); //依次输出
printf("依次输出集合中所有元素-------\n");
for (pos = iset.begin(); pos != iset.end(); ++pos)
printf("%d ", *pos);
putchar('\n');
return ;
}
运行结果
三,SET与HASH_SET性能对比
#include <set>
#include <hash_set>
#include <iostream>
#include <ctime>
#include <cstdio>
#include <cstdlib>
using namespace std;
using namespace stdext; //hash_set // MAXN个数据 MAXQUERY次查询
const int MAXN = , MAXQUERY = ;
int a[MAXN], query[MAXQUERY]; void PrintfContainertElapseTime(char *pszContainerName, char *pszOperator, long lElapsetime)
{
printf("%s 的%s操作 用时 %d毫秒\n", pszContainerName, pszOperator, lElapsetime);
} int main()
{
printf("set VS hash_set 性能测试 数据容量 %d个 查询次数 %d次\n", MAXN, MAXQUERY);
const int MAXNUM = MAXN * ;
const int MAXQUERYNUM = MAXN * ;
printf("容器中数据范围 [0, %d) 查询数据范围[0, %d)\n", MAXNUM, MAXQUERYNUM); //随机生成在[0, MAXNUM)范围内的MAXN个数
int i;
srand(time(NULL));
for (i = ; i < MAXN; ++i)
a[i] = (rand() * rand()) % MAXNUM;
//随机生成在[0, MAXQUERYNUM)范围内的MAXQUERY个数
srand(time(NULL));
for (i = ; i < MAXQUERY; ++i)
query[i] = (rand() * rand()) % MAXQUERYNUM; set<int> nset;
hash_set<int> nhashset;
clock_t clockBegin, clockEnd; //insert
printf("-----插入数据-----------\n"); clockBegin = clock();
nset.insert(a, a + MAXN);
clockEnd = clock();
printf("set中有数据%d个\n", nset.size());
PrintfContainertElapseTime("set", "insert", clockEnd - clockBegin); clockBegin = clock();
nhashset.insert(a, a + MAXN);
clockEnd = clock();
printf("hash_set中有数据%d个\n", nhashset.size());
PrintfContainertElapseTime("hase_set", "insert", clockEnd - clockBegin); //find
printf("-----查询数据-----------\n"); int nFindSucceedCount, nFindFailedCount;
nFindSucceedCount = nFindFailedCount = ;
clockBegin = clock();
for (i = ; i < MAXQUERY; ++i)
if (nset.find(query[i]) != nset.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clockEnd = clock();
PrintfContainertElapseTime("set", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount); nFindSucceedCount = nFindFailedCount = ;
clockBegin = clock();
for (i = ; i < MAXQUERY; ++i)
if (nhashset.find(query[i]) != nhashset.end())
++nFindSucceedCount;
else
++nFindFailedCount;
clockEnd = clock();
PrintfContainertElapseTime("hash_set", "find", clockEnd - clockBegin);
printf("查询成功次数: %d 查询失败次数: %d\n", nFindSucceedCount, nFindFailedCount);
return ;
}
运行结果如下:
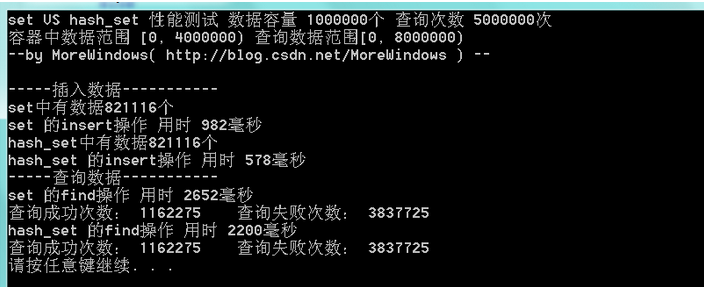
由于查询的失败次数太多,这次将查询范围变小使用再测试下:
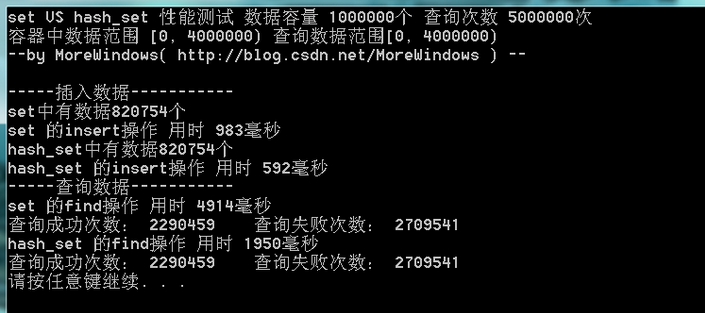
由于结点过多,80多万个结点,set的红黑树树高约为19(2^19=524288,2^20=1048576),查询起来还是比较费时的。hash_set在时间性能上比set要好一些,并且如果查询成功的几率比较大的话,hash_set会有更好的表现。
四,深入分析hash_set
1. hash table
hash_set的底层数据结构是哈希表,因此要深入了解hash_set,必须先分析哈希表。 hash表的出现主要是为了对内存中数据的快速、随机的访问。它主要有三个关键点:Hash表的大小、Hash函数、冲突的解决。哈希表是根据关键码值(Key-Value)而直接进行访问的数据结构,它用哈希函数处理数据得到关键码值,关键码值对应表中一个特定位置再由应该位置来访问记录,这样可以在时间复杂性度为O(1)内访问到数据。但是很有可能出现多个数据经哈希函数处理后得到同一个关键码——这就产生了冲突,解决冲突的方法也有很多,各大数据结构教材及考研辅导书上都会介绍大把方法。这里采用最方便最有效的一种——链地址法,当有冲突发生时将具同一关键码的数据组成一个链表。下图展示了链地址法的使用:
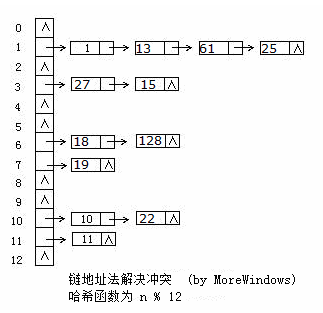
2. 关于Hash表的大小
Hash表的大小一般是定长的,如果太大,则浪费空间,如果太小,冲突发生的概率变大,体现不出效率。所以,选择合适的Hash表的大小是Hash表性能的关键。
对于Hash表大小的选择通常会考虑两点:
第一,确保Hash表的大小是一个素数。常识告诉我们,当除以一个素数时,会产生最分散的余数,可能最糟糕的除法是除以2的倍数,因为这只会屏蔽被除数中的位。由于我们通常使用表的大小对hash函数的结果进行模运算,如果表的大小是一个素数,就可以获得最佳的结果。
第二,创建大小合理的hash表。这就涉及到hash表的一个概念:装填因子。设装填因子为a,则:
a=表中记录数/hash表表长
通常,我们关注的是使hash表的平均查找长度最小,而平均查找长度是装填因子的函数,而不是表长n的函数。a的取值越小,产生冲突的机会就越小,但如果a取值过小,则会造成较大的空间浪费,通常,只要a的取值合适,hash表的平均查找长度就是一个常数,即hash表的平均查找长度为O(1)。
当然,根据不同的数据量,会有不同的哈希表的大小。对于数据量时多时少的应用,最好的设计是使用动态可变尺寸的哈希表,那么如果你发现哈希表尺寸太小了,比如其中的元素是哈希表尺寸的2倍时,我们就需要扩大哈希表尺寸,一般是扩大一倍。
下面是哈希表尺寸大小的可能取值(素数,后边是前边的2倍左右):
17, 37, 79, 163, 331, 673, 1361, 2729, 5471, 10949, 21911, 43853, 87719, 175447, 350899,701819, 1403641, 2807303, 5614657, 11229331, 22458671, 44917381, 89834777, 179669557, 359339171, 718678369, 1437356741, 2147483647
那么C++的STL中hash_set是如何实现动态增加哈希表长度的呢?
首先来看看VS2008中hash_set是如何实现动态的增加表的大小,hash_set是在hash_set.h中声明的,在hash_set.h中可以发现hash_set是继承_Hash类的,hash_set本身并没有太多的代码,只是对_Hash作了进一步的封装,这种做法在STL中非常常见,如stack栈和queue单向队列都是以deque双向队列作底层数据结构再加一层封装。
_Hash类的定义和实现都在xhash.h类中,微软对_Hash类的第一句注释如下——
hash table -- list with vector of iterators for quick access。
这说明_Hash实际上就是由vector和list组成哈希表。再阅读下代码可以发现_Hash类增加空间由_Grow()函数完成,当空间不足时就倍增(或者近2被的素数),并且表中原有数据都要重新计算hash值以确定新的位置。也就是重新申请一个更大的空间,同时将原来hash_set中的值逐个放到新的hash_set中。
3. 哈希函数
|
关键字
|
内部编码
|
内部编码的平方值
|
H(k)关键字的哈希地址
|
|
KEYA
|
11050201
|
122157778355001
|
778
|
|
KYAB
|
11250102
|
126564795010404
|
795
|
|
AKEY
|
01110525
|
001233265775625
|
265
|
|
BKEY
|
02110525
|
004454315775625
|
315
|
参考文章
http://blog.csdn.net/morewindows/article/details/7029587
http://blog.csdn.net/morewindows/article/details/7330323
http://blog.csdn.net/qll125596718/article/details/6997850
http://baike.baidu.com/view/329976.htm?fromtitle=%E6%95%A3%E5%88%97%E8%A1%A8&fromid=10027933&type=syn
深入了解STL中set与hash_set,hash表基础的更多相关文章
- STL中的vector实现邻接表
/* STL中的vector实现邻接表 2014-4-2 08:28:45 */ #include <iostream> #include <vector> #include ...
- STL中vector怎么实现邻接表
最近,同期的一位大佬给我出了一道题目,改编自 洛谷 P2783 有机化学之神偶尔会做作弊 这道题好坑啊,普通链表过不了,只能用vector来存边.可能更快一些吧? 所以,我想记录并分享一下vector ...
- hash表的理解
哈希表 先从数组说起 任何一个程序员,基本上对数组都不会陌生,这个最常用的数据结构,说到它的优点,最明显的就是两点: 简单易用,数组的简易操作甚至让大多数程序员依赖上了它,在资源富足的情况下,我们甚至 ...
- 6.数组和Hash表
当显示多条结果时,存储在变量中非常智能,变量类型会自动转换为一个数组. 在下面的例子中,使用GetType()可以看到$a变量已经不是我们常见的string或int类型,而是Object类型,使用-i ...
- 数组和Hash表
数组和Hash表 当显示多条结果时,存储在变量中非常智能,变量类型会自动转换为一个数组. 在下面的例子中,使用GetType()可以看到$a变量已经不是我们常见的string或int类型,而是Obje ...
- 四种方式带你层层递进解剖算法---hash表不一定适合寻找重复数据
一.题目描述 找出数组中重复的数字 > 在一个长度为 n 的数组 nums 里的所有数字都在 0-n-1 的范围内.数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次. ...
- STL中set底层实现方式
Q:STL中set底层实现方式? 为什么不用hash? A: 第一个问题:set底层实现方式为RB树(即红黑树). 第二个问题: 首先set,不像map那样是key-value对,它的key与valu ...
- C++ STL中哈希表Map 与 hash_map 介绍
0 为什么需要hash_map 用过map吧?map提供一个很常用的功能,那就是提供key-value的存储和查找功能.例如,我要记录一个人名和相应的存储,而且随时增加,要快速查找和修改: 岳不群-华 ...
- stl源码分析之hash table
本文主要分析g++ stl中哈希表的实现方法.stl中,除了以红黑树为底层存储结构的map和set,还有用哈希表实现的hash_map和hash_set.map和set的查询时间是对数级的,而hash ...
随机推荐
- BestCoder Round #87 1001
GCD is Funny Accepts: 524 Submissions: 1147 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 655 ...
- Linq to sql 语法方法示例
联表查询,判断追加条件,对集合分页 ) { var data = from m in _db.AppArticleComment join o in _db.AppArticle on m.Artic ...
- [ACM] poj 1064 Cable master (二分查找)
Cable master Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 21071 Accepted: 4542 Des ...
- Linux内核分析之操作系统是如何工作的
在本周的课程中,孟老师主要讲解了操作系统是如何工作的,我根据自己的理解写了这篇博客,请各位小伙伴多多指正. 一.知识点总结 1. 三个法宝 存储程序计算机:所有计算机基础性的逻辑框架. 堆栈:高级语言 ...
- 上线踩坑引发的处理方式---lsof,strace
两个跟踪进程的linux命令 lsof -p pidstrace -p pid快速跟踪进程出现问题的地方.由于进程本身运行良好,但是内部一直等待第三方哪个应答,导致进程假死.引用自:http://li ...
- hdu - 3952 Fruit Ninja(简单几何)
思路来自于:http://www.cnblogs.com/wuyiqi/archive/2011/11/06/2238530.html 枚举两个多边形的两个点组成的直线,判断能与几个多边形相交 因为最 ...
- 修改VNC分辨率大小
实验系统是centos6.5,在被连接的机器上需要安装vncserver. 1.第一种方法:使用geometry参数进行调整使用man命令获得关于geometry参数的描述[root@secdb ~] ...
- 讨厌的 StorageFolder.GetFileAsync 异常。
我们在做WinRT开发的时候,会偶到这样一个场景. 获取一个文件,当他不存在的时候,我们做一些事情. 如果当不存在,我们就创建这么一个文件,那就很好办了. var file = Application ...
- [WinAPI] API 4 [注册][创建][消息][第一个框架类窗口]
首先注册了窗口类,然后创建了一个窗口,创建窗口时指定的窗口的属性和窗口消息的处理函数.函数消息的处理函数大多调用系统默认函数来处理. #include<windows.h> /*全局变量* ...
- dpkg 被中断,您必须手工运行 sudo dpkg -configure -a 解决
E: dpkg 被中断,您必须手工运行 sudo dpkg --configure -a 解决此问题. E: dpkg 被中断,您必须手工运行 sudo dpkg --configure -a 解决此 ...