BeautifulSoup模块学习文档
一、BeautifulSoup简介
1.BeautifulSoup模块
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式
2.安装
在python3版本中安装BeautifulSoup
pip install BeautifulSoup4
也可以通过下载BS4的源码,通过setup.py来安装
3.Beautiful解析器安装
主要的几个解析器:
bs4的HTML解析器-->BeautifulSoup(mk,'html.parser')-->安装bs4库
lxml的HTML解析器-->BeautifulSoup(mk,'lxml')-->pip install lxml
lxml的XML解析器-->BeautifulSoup(mk,'xml')-->pip install lxml
html5lib的解析器-->BeautifulSoup(mk,'html5lib')-->pip installl html5lib
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | 1.Python的内置标准库2.执行速度适中3.文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 1.速度快2.文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"])/BeautifulSoup(markup, "xml") | 1.速度快2.唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 1.最好的容错性2.以浏览器的方式解析文档3.生成HTML5格式的文档 | 1.速度慢2.不依赖外部扩展 |
推荐使用lxml作为解析器,效率高。
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml。
pip install lxml
二、BeautifulSoup快速使用
1.beautifulSoup使用方法
解析原理:
实例化一个BeautifulSoup对象,且将即将被解析的页面源码加载到该对象中
使用该对象中的属性或方法进行标签定位和数据提取
解析方式:
BeautifulSoup(fp,"lxml"),lxml指定解析器,将本地存储的html文档加载到该对象中
BeautifulSoup(page_text,"lxml"),将互联网上获取的html源码加载到该对象中
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>data</p>', 'html.parser')
2.BeautifulSoup库的基本元素
BeautifulSoup类和html文档标签树的关系

BeautifulSoup库是解析、遍历、维护“标签树”的功能库
BeautifulSoup对象和文档树是对应的
BeautifulSoup类的基本元素
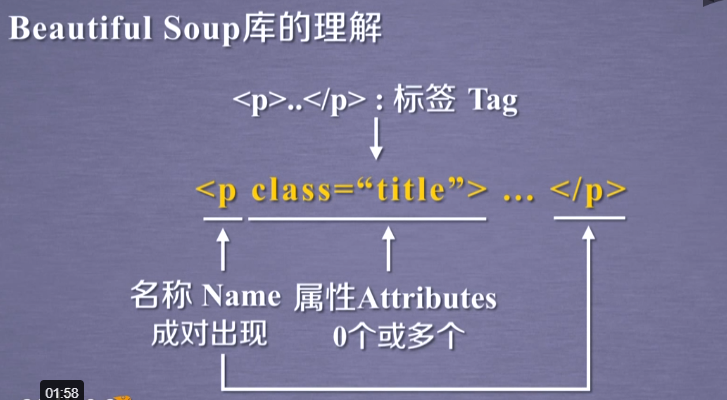
Tag:标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾
Name:标签的名字,<p>…</p>的名字是'p',格式:<tag>.name
Attributes:标签的属性,字典形式组织,格式:<tag>.attrs
NavigableString:标签内非属性字符串,<>…</>中字符串,格式:<tag>.string
Comment:标签内字符串的注释部分,一种特殊的Comment类型
3.BeautifulSoup对象标签定位
本地文件test.html
<html lang="en">
<head>
<meta charset="utf-8"/>
<title>测试bs4</title>
</head>
<body>
<div>
<p>百里守约</p>
</div>
<div class="song">
<p>李清照</p>
<p>王安石</p>
<p>苏轼</p>
<p>柳宗元</p>
<a href="http://www.song.com/" target="_self" title="赵匡胤">
<span>this is span</span>
宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
<a class="du" href="">总为浮云能蔽日,长安不见使人愁</a>
<img alt="" src="http://www.baidu.com/meinv.jpg"/>
</div>
<div class="tang">
<ul>
<li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
<li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
<li><a alt="qi" href="http://www.126.com">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
<li><a class="du" href="http://www.sina.com">杜甫</a></li>
<li><a class="du" href="http://www.dudu.com">杜牧</a></li>
<li><b>杜小月</b></li>
<li><i>度蜜月</i></li>
<li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
</ul>
</div>
</body>
</html>
test.html
利用lxml解析成soup对象
from bs4 import BeautifulSoup
fp = open("./test.html","r",encoding="utf-8")
soup = BeautifulSoup(fp,"lxml")
TagName
Tag 对象与XML或HTML原生文档中的tag相同
soup.tagName:返回的是页面中第一次出现的tagName标签,(一个单数)
tag = soup.title
type(tag)
# <title>测试bs4</title>
标签对象的那么属性:每个tag都有自己的名字,通过 .name 来获取
tag.name
# u'title'
soup.find方法:属性定位
一个tag可能有很多个属性. tag <b class="boldest"> 有一个 “class” 的属性,值为 “boldest” . tag的属性的操作方法与字典相同
soup.find("tagName",attrName="value")
注意:返回的是单数
tag = soup.find("div",class_="song") # 因为class为关键字,所以改为class_
tag对象可以直接“点”取属性,比如:.attrs
tag.attrs
# {u'class': u'song'}
soup.find_all()方法
soup.find_all("tagName"):定位所有的tagName的标签
soup.find_all("tagName",attrName="value"):属性定位
注意:返回值是列表
soup.find_all("div")
soup.find_all("div",class_="song")
soup.select()方法
select("选择器"):根据选择器进行标签定位且返回的是复数(列表)
标签选择器,id选择器,类选择器,属性选择器,层级选择器
层级选择器:>表示一个层级,空格表示多个层级
soup.select(".tang")
层级选择
# soup.select(".tang li")
soup.select(".tang > ul > li") # 两者效果相同
4.BeautifulSoup对象数据提取
string和text
string:获取找到的标签中第一个标签的文本
soup.p.string # 获取第一个p标签的文本 # '百里守约'
text:获取找到的标签中第一个标签的文本
soup.p.text # 获取第一个p标签的文本
# '百里守约'
区别:
string获取的是标签中只存在文本的直系文本内容,
text获取的是标签中所有的文本内容
获取标签属性
tag["attrName"]
for a in soup.select(".tang > ul > li > a"):
print(a["href"])
http://www.baidu.com
http://www.163.com
http://www.126.com
http://www.sina.com
http://www.dudu.com
http://www.haha.com
bs4库的html输出格式
bs4的prettify方法:为html文内容添加换行符,是文本格式更加清晰
soup.prettify
三、BeautifulSoup遍历方法
html基本格式

1.标签树的下行遍历
.contents:子节点的列表,将<tag>所有儿子节点存入列表 .children:子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 .descendants:子孙节点的迭代类型,包含所有子孙节点,用于循环遍历
for child in soup.body.children: # 遍历儿子节点
print(child)
for child in soup.body.descendants: # 遍历子孙节点
print(child)
2.标签树的上行遍历
.parent:节点的父亲标签 .parents:节点先辈标签的迭代类型,用于循环遍历先辈节点
代码框架
soup = BeautifulSoup(demo, "html.parser")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
3.标签树的平行遍历
.next_sibling:返回按照HTML文本顺序的下一个平行节点标签 .previous_sibling:返回按照HTML文本顺序的上一个平行节点标签 .next_siblings:迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 .previous_siblings:迭代类型,返回按照HTML文本顺序的前续所有平行节点标签

四、信息组织与提取方法
1.信息标记的三种形式:
1.XML:eXtensible Markup Language


标签内容的表达形式:
<name> … </name> 标签中有内容
<name/> 标签中没有内容
<!-- --> 注释表达方式
2.JSON:JavsScript Object Notation
有类型的键值对 key:value,"name":"北京理工大学"
键值对的值有多个:"name":["北京理工大学","延安自然科学院"]
键值对的嵌套使用

3.YAML:YAML Ain't Markup Language
无类型键值对key:value name:北京理工大学
键值对的值有多个:“-”表达并列关系
键值对的嵌套使用:用缩进表达所属关系
| 表达整块数据,#表示注释

2.三种信息标记形式的比较
XML:最早的通用信息标记语言,可扩展性好,但繁琐
Internet上的信息交互与传递
JSON:信息有类型,适合程序处理(js),较XML简洁
移动应用云端和节点的信息通信,无注释,优势:在经过传输后能够作为程序代码的一部分,缺点:无法体现注释
YAML:信息无类型,文本信息比例最高,可读性好
用于各类系统的配置文件,有注释易读
3.信息提取的一般方法
方法一:完整解析信息的标记形式,在提取关键信息
标记解析器解析:XML JSON YAML
需要标记解析器,如:bs4库的标签树遍历
优点:信息解析准确
提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息
搜索:对信息的文本产找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关
融合方法:结合形式解析和搜索方法,提取关键信息
需要表及解析器及文本查找函数
实例:
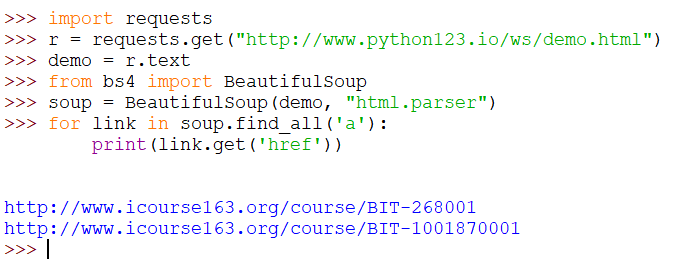
提取HTML中所有URL链接
思路:
搜索到所有<a>标签
解析<a>标签格式,提取herf后的链接内容
BeautifulSoup模块学习文档的更多相关文章
- 2013 最新的 play web framework 版本 1.2.3 框架学习文档整理
Play framework框架学习文档 Play framework框架学习文档 1 一.什么是Playframework 3 二.playframework框架的优点 4 三.Play Frame ...
- soapUI学习文档(转载)
soapUI 学习文档不是前言的前言记得一个搞开发的同事突然跑来叫能不能做个WebService 性能测试,当时我就凌乱了,不淡定啊,因为我是做测试的,以前连WebService 是什么不知道,毕竟咱 ...
- NodeJS-001-Nodejs学习文档整理(转-出自http://www.cnblogs.com/xucheng)
Nodejs学习文档整理 http://www.cnblogs.com/xucheng/p/3988835.html 1.nodejs是什么: nodejs是一个是javascript能在后台运行的平 ...
- Ext JS 6学习文档-第4章-数据包
Ext JS 6学习文档-第4章-数据包 数据包 本章探索 Ext JS 中处理数据可用的工具以及服务器和客户端之间的通信.在本章结束时将写一个调用 RESTful 服务的例子.下面是本章的内容: 模 ...
- Vue 学习文档
Vue 学习文档 vue 起步 引包 启动 new Vue(options) options: el 目的地(可以用类名.标签名等,也可以直接用mod元素) #elementId .elementCl ...
- Openstack api 学习文档 & restclient使用文档
Openstack api 学习文档 & restclient使用文档 转载请注明http://www.cnblogs.com/juandx/p/4943409.html 这篇文档总结一下我初 ...
- Openstack python api 学习文档 api创建虚拟机
Openstack python api 学习文档 转载请注明http://www.cnblogs.com/juandx/p/4953191.html 因为需要学习使用api接口调用openstack ...
- help python(查看模块帮助文档)
查看模块帮助文档: help(len) -- docs for the built in len function (note here you type "len" not &q ...
- .Net 官方学习文档
.Net 官方学习文档:https://docs.microsoft.com/zh-cn/dotnet/articles/welcome
随机推荐
- python 如何解决高并发下的库存问题??
python 提供了2种方法解决该问题的问题:1,悲观锁:2,乐观锁 悲观锁:在查询商品储存的时候加锁 select_for_update() 在发生事务的commit或者是事务的rollback时 ...
- ThinkPHP5 支付宝支付扩展库(超级简单,超级好用!)
ThinkPHP5 支付宝支付扩展库, 一个静态方法的调用就可以实现,包括手机网站支付.电脑网站支付.支付查询.退款.退款查询.对账单所有功能,而且是2017年7月20日最新版~我的想法是,调用一个静 ...
- git error: failed to push some refs to 'git@github.com:xxx/xxx.git'
本地仓库中和远程仓库不一致,缺少readme.md文件 解决方式参见:https://blog.csdn.net/qq_37281252/article/details/79044798
- order by关键字优化
1.ORDER BY子句,尽量使用Index方式排序,避免使用FileSort方式排序 2.建表SQL CREATE TABLE tblA( id int primary key not null a ...
- mkpasswd - 为用户产生新口令
总览 SYNOPSIS mkpasswd [ args ] [ user ] 介绍 INTRODUCTION mkpasswd 为用户产生口令并自动应用.它是基于O'Reilly的书<Explo ...
- 如何利用scrapy新建爬虫项目
抓取豆瓣top250电影数据,并将数据保存为csv.json和存储到monogo数据库中,目标站点:https://movie.douban.com/top250 一.新建项目 打开cmd命令窗口,输 ...
- linux c 的main 函数中的return 和 查看返回参数 argv 与 argc 作用
hello.c #include <stdio.h> int main(int argv, char* argc[]) { printf("hello word!\n" ...
- Linux 安装 Composer
Linux 安装 Composer 入门 练习环境: 虚拟机:Oracle VM VirtualBox. 系统:CentOS 7. 安装方式一: 参考网址:https://learnku.com/c ...
- shell中通过读取输入yes no判断下一步如何处理
if [ -d $r_item_rmgit ];then read -p "$r_item_rmgit exit, replace it ...
- 第二组_学生会管理系统_APP端个人感想
一:相关链接 1.相关源码链接: 1.学生会管理系统APP端:Code 2.学生会管理系统WEB端:Code 3.学生会管理系统后台:COde 2.相关文档和博客: 1.前期接口文档以及需求文档Doc ...