Hadoop 权限管理(转)
如下图,hadoop访问控制分为两级,其中ServiceLevel Authorization为系统级,用于控制是否可以访问指定的服务,例如用户/组是否可以向集群提交Job,它是最基础的访问控制,优先于文件权限和mapred队列权限验证。Access Control on Job Queues在job调度策略层之上,控制mapred队列的权限。DFSPermmision用户控制文件权限。目前版本中,连接到hadoop集群的用户/组信息取决于客户端环境,即客户端主机中`whoami`和`bash –c groups`取到的用户名和组名,没有uid和gid,用户属组列表中只要有一个与集群配置的用户组相同即拥有该组权限。
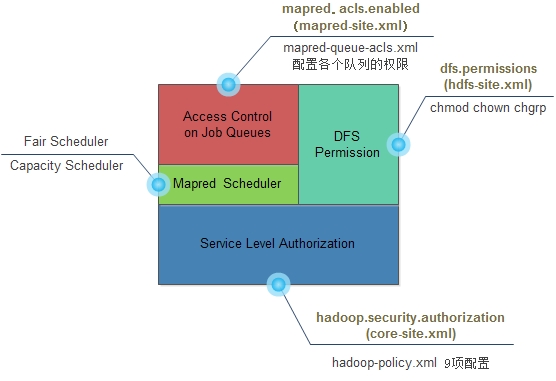
1、 配置Service Level Authorization
修改core-site.xml
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
hadoop.security.authorization=true则开启ServiceLevel Authorization,若为false则不经过任何验证,所有用户拥有全部权限。(修改此配置需要重启hadoop)
Service LevelAuthorization有9个可配置的属性,每个属性可指定拥有相应访问权限的用户或者用户组。这9个ACL属性如下(hadoop-policy.xml):
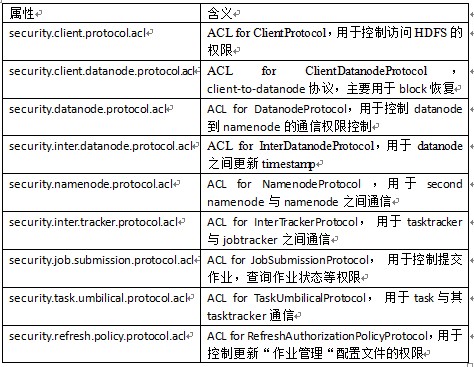
这9个属性的配置方法相同,具体如下:
每个可配置多个用户,用户之间用“,”分割;可配置多个用户组,分组之间用“,”分割,用户和分组之间用空格分割,如果只有分组,前面保留一个空格,如:
<property>
<name>security.job.submission.protocol.acl</name>
<value>alice,bobgroup1,group2</value>
</property>
默认情况下,这9个属性不对任何用户和分组开放。
该配置文件可使用以下命令动态加载:
(1) 更新namenode相关属性:bin/hadoop dfsadmin –refreshServiceAcl
(2) 更新jobtracker相关属性:bin/hadoopmradmin –refreshServiceAcl
2、 调度器配置
修改mapred-site.xml
<property>
<name>mapred.jobtracker.taskScheduler</name>
<value>org.apache.hadoop.mapred.CapacityTaskScheduler</value>
</property>
启用Access Contol onJob Queues需选择一个支持多队列管理的调度器,所以mapred.jobtracker.taskScheduler只能为CapacityTaskScheduler或FairScheduler。
在mapred-site.xml里配置队列,如:
<property>
<name>mapred.queue.names</name>
<value>default,hadoop,stat,query</value>
</property>
3、 Access Contol on JobQueues配置
Access Contol on Job Queues开关在mapred-site.xml,如下:
<property>
<name>mapred.acls.enabled</name>
<value>true</value>
</property>
mapred.acls.enabled=true开启,为false关闭。
具体ACL属性在mapred-queue-acl.xml里,如:
<property>
<name>mapred.queue.stat.acl-submit-job</name>
<value>user1,user2 group1,group2</value>
</property>
表示user1,user2和group1,group2可以向stat queue提交job。
4、 DFS permission配置
修改hdfs-site.xml
<property>
<name> dfspermission </name>
<value>true</value>
</property>
dfs.permission是否开启文件权限验证,true开启,false不进行读写权限验证。(注:dfs.permission开启与否dfs permission信息都不会改变后丢失,chown、chgrp、chmod操作也始终会验证权限,dfspermission信息只在namenode里,并不在danode里与blocks关联)
用chown、chgrp、chmod修改文件/目录的属主、属组和权限。
补:Job ACL
Job ACL默认值配置在mapred-site.xml里,如下:

<property>
<name>mapreduce.job.acl-view-job</name>
<value>user1</value>
</property>
<property>
<name>mapreduce.job.acl-modify-job</name>
<value>user1</value>
</property>
表示,默认情况下,user1用户拥有job的查看和修改权限。
Job提交者可以指定mapreduce.job.acl-view-job和mapreduce.job.acl-modify-job值,提交时指定的值会覆盖默认值。
Job提交者、superuser、集群管理员(mapreduce.cluster.administrators)、JobQueue管理员始终拥有该权限。
转自 http://blog.csdn.net/cheersu/article/details/8080162
参考资料:
《Service Level Authorization Guide》
Hadoop 权限管理(转)的更多相关文章
- Hadoop权限管理
1.Hadoop权限管理包括以下几个模块: (1) 用户分组管理.用于按组为单位组织管理,某个用户只能向固定分组中提交作业,只能使用固定分组中配置的资源:同时可以限制每个用户提交的作业数,使用的资源量 ...
- Hadoop 权限管理
Hadoop的权限管理同Linux的很像,有用户,用户组之分,同时Hadoop提供了权限管理命令,主要包括: chmod [-R] mode file … 只有文件的所有者或者超级用户才有权限改变文件 ...
- HADOOP docker(七):hive权限管理
1. hive权限简介1.1 hive中的用户与组1.2 使用场景1.3 权限模型1.3 hive的超级用户2. 授权管理2.1 开启权限管理2.2 实现超级用户2.3 实现hiveserver2用户 ...
- Spark SQL Thrift Server 配置 Kerberos身份认证和权限管理
转载请注明出处:http://www.cnblogs.com/xiaodf/ 之前的博客介绍了通过Kerberos + Sentry的方式实现了hive server2的身份认证和权限管理功能,本文主 ...
- 【linux相识相知】用户及权限管理
linux系统是多用户(Multi-users)和多任务(Multi-tasks)的,这样的目的是为了一台linux主机可以给很多用户提供服务同时运行多种服务,但是我们是怎么区分每个用户呢?作为一个管 ...
- Linux命令-用户及权限管理
一.权限管理linux系统中对文件权限的描述机制: u g od r w x r w x r - x (r读,w写,x执行)文件 所有者 所属组 其他人可以表示为二进制: 111 111 101也可以 ...
- 【Hive学习之七】Hive 运行方式&权限管理
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop-3.1.1 apache-hive-3.1.1 ...
- Hive 系列(二)权限管理
Hive 系列(二)权限管理 一.关于 Hive Beeline 问题 启动 hiveserver2 服务,启动 beeline -u jdbc:hive2:// 正常 ,启动 beeline -u ...
- HDFS权限管理用户指南
原文地址:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_permissions_guide.html 概述 用户身份 理解系统的实现 文件系统API变更 S ...
随机推荐
- [CSP-S模拟测试]:密州盛宴(贪心)
江城子·密州出猎老夫聊发少年狂,左牵黄,右擎苍,锦帽貂裘,千骑卷平冈.为报倾城随太守,亲射虎,看孙郎.酒酣胸胆尚开张,鬓微霜,又何妨!持节云中,何日遣冯唐?会挽雕弓如满月,西北望,射天狼.(这首词通过 ...
- python and 用法
>>> 1 and [] and [1] [] >>> 1 and [2] and [1] [1] >>> 0 and [1] and [2] 0
- Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2) 解决方法
可以通过如下命令来解决,具体就是先关闭服务器,然后再重启服务器: cd /etc/init.d sudo service mysql stop sudo service mysql start
- jquery 合并两个 json 对象
jQuery.extend( [ deep ], target, object1, [ objectN ] )合并对象到第一个对象 //deep为boolean类型,其它参数为object类型 var ...
- python 3.x上安裝web.py
python 3.x上安裝web.py 查询之后,安装时使用pip3 install web.py==0.40.dev0 最終可以运行 app.py import weburls=( '/',' ...
- Linux随笔 - linux 多个会话同时执行命令后history记录不全的解决方案【转载】
基本认识linux默认配置是当打开一个shell终端后,执行的所有命令均不会写入到~/.bash_history文件中,只有当前用户退出后才会写入,这期间发生的所有命令其它终端是感知不到的. 问题场景 ...
- 测开之路四十七:Django之请求静态资源与模板
框架必要的配置 import sysfrom django.conf.urls import urlfrom django.conf import settingsfrom django.http i ...
- androidmanifest.xml 解码工具又来一发
背景: 最近这几天在研究facebook的协议,但是facebook的采用 SSL Pinning 技术,正常通过fiddler是不能解开SSL观察协议. 听说facebook app在 manife ...
- pixi与lottie-web的benchmark测试
生产版本 "dependencies": { "lottie-web": "^5.5.7", "pixi-spin ...
- 哪些文件在vue项目中很重要,哪些可以删掉
是时候告诉你重要文件是哪些了,这是一个陆游,所以 需要路由配置 index.js 路由配置文件是index.js注意这个文件最开始就在集成路由了 然后最开始集成路由的地方可以不写后缀名字,因此注意这个 ...