GlusterFS ——分布式卷
GlusterFS概述
全部部署GlusterFS文件系统地址:https://www.cnblogs.com/Mercury-linux/p/12050389.html
GlusterFS系统是一个可扩展的网络文件系统,相比其他分布式文件系统,GlusterFS具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。
文件存储
通常支持POSIX接口(如glusterfs,但GFS、HDFS是非POSIX接口的),可以像普通文件系统(如ext4)那样访问,但又比普通文件系统多了并行化访问的能力和冗余机制。主要的分布式文件存储系统有TFS、cephfs、glusterfs和HDFS等。主要存储非结构化数据,如普通文件、图片、音视频等。可以采用NFS和CIFS等协议访问,共享方便。NAS是文件存储类型。
块存储
这种接口通常以QEMU Driver或者Kernel Module的方式存在,主要通过qemu或iscsi协议访问。主要的块存储系统有ceph块存储、sheepdog等。主要用来存储结构化数据,如数据库数据。数据共享不方便。DAS和SAN都是块存储类型。
对象存储
对象存储系统综合了NAS和SAN的优点,同时具有SAN的高速直接访问和NAS的数据共享等优势。以对象作为基本的存储单元,向外提供RESTful数据读写接口,常以网络服务的形式提供数据访问。主要的对象存储系统有AWS、swift和ceph对象存储。主要用来存储非结构化数据
分布式Glusterfs卷
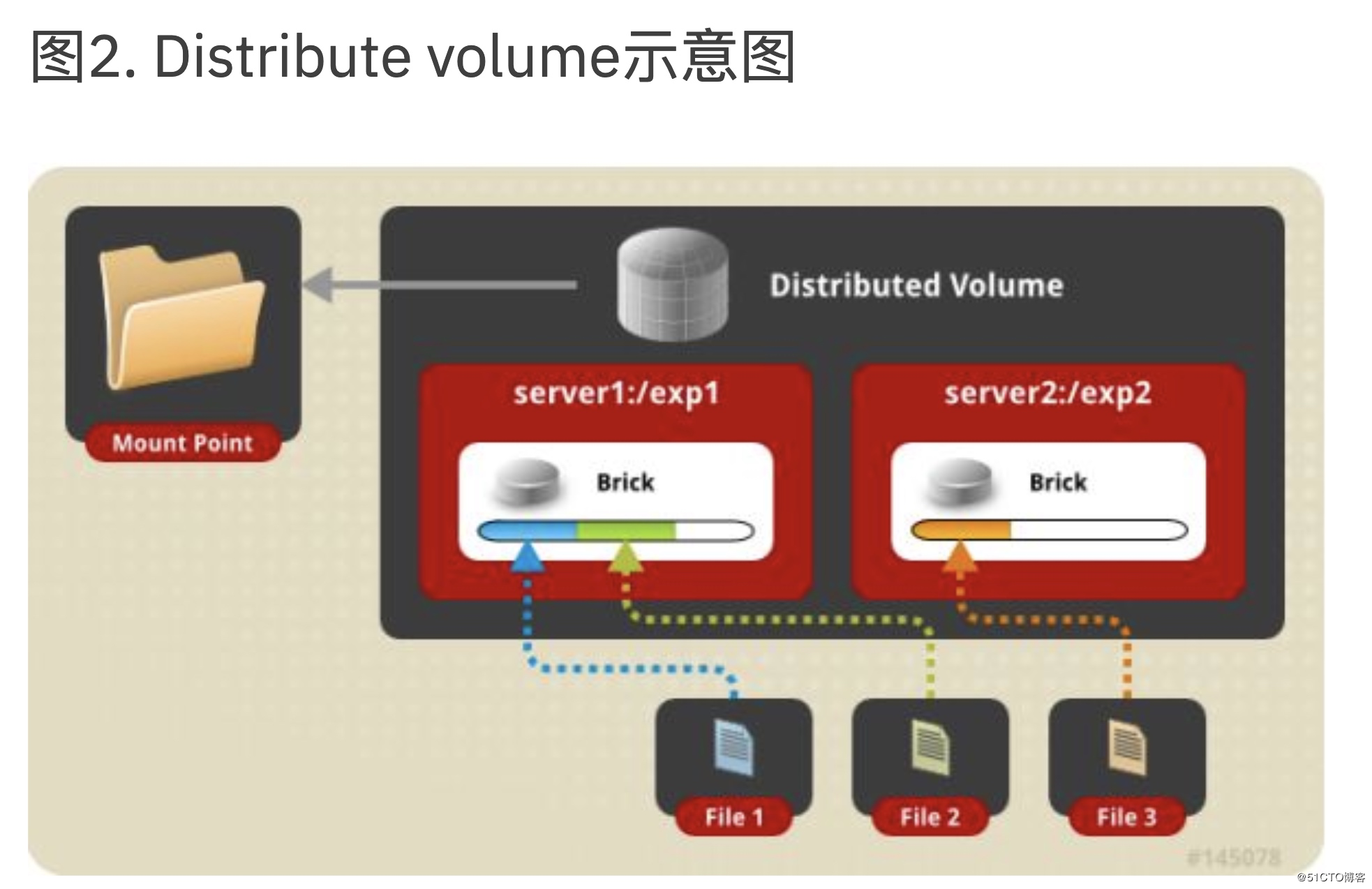
这是默认的glusterfs卷,即,如果未指定卷的类型,则在创建卷时,默认选项是创建分布式卷。在这里,文件分布在卷中的各个块之间。因此,file1只能存储在brick1或brick2中,而不能存储在两者中。因此,没有数据冗余。这种存储卷的目的是轻松而便宜地缩放卷大小。但是,这也意味着砖块故障将导致数据完全丢失,并且必须依靠底层硬件来提供数据丢失保护。(数据一但丢了也就丢了)
环境准备
| 操作系统 | ip | 主机名 | 硬盘数量(两块) |
| centos 7.6 | 10.0.0.11 | node01 | sdb: 20G sdc: 20G |
| centos 7.6 | 10.0.0.12 | node02 | sdb: 20G sdc: 20G |
| centos 7.6 | 10.0.0.13 | node03 | sdb: 20G sdc: 20G |
| centos 7.6 | 10.0.0.14 | node04 | sdb: 20G sdc: 20G |
| centos 7.6 | 10.0.0.7 | web01(client) | sda: 50G |
| ...... |
GlusterFS客户端常用命令
| 命令 | 功能 |
| gluster peer probe | 添加节点 |
| gluster peer detach | 移除节点 |
| gluster volume create | 创建卷 |
| gluster volume start $VOLUME_NAFME | 启动卷 |
| gluster volume stop $VOLUME_NAME | 停止卷 |
| gluster volume delete $VOlUME_NAME | 删除卷 |
| gluster volume quota enable | 开启卷配额 |
| gluster volume quota disable | 关闭卷配额 |
| gluster volume quota limitusage | 设定卷配额 |
#以下部分在node主机上面操作
服务端部署
. 安装GlusterFS源
[root@gs-node1 ~]# yum install centos-release-gluster -y . 安装GlusterFS
[root@gs-node1 ~]# yum install -y glusterfs-server . 启动GlusterFS
[root@gs-node1 ~]# systemctl start glusterfsd glusterfssharedstorage
[root@gs-node1 ~]# systemctl enable glusterfsd glusterfssharedstorage . 检查端口是否存在24007
[root@gs-node1 ~]# netstat -lntup
netstat -lntup | grep
tcp 0.0.0.0: 0.0.0.0:* LISTEN /glusterd . 查看GlusterFS版本
[root@node01 ~]# glusterfs -V
glusterfs 6.6
Repository revision: git://git.gluster.org/glusterfs.git
Copyright (c) - Red Hat, Inc. <https://www.gluster.org/>
GlusterFS comes with ABSOLUTELY NO WARRANTY.
It is licensed to you under your choice of the GNU Lesser
General Public License, version or any later version (LGPLv3
or later), or the GNU General Public License, version (GPLv2),
in all cases as published by the Free Software Foundation. . hosts文件解析
注:node01~node04所有的主机hosts文件均为此内容;同时全部修改为对应的主机名,centos7修改主机名方式:#hostnamectl set-hostname 主机名 (即为临时和永久生效)可以使用#hostnamectl status 查看系统基本信息 [root@gs-node1 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
:: localhost localhost.localdomain localhost6 localhost6.localdomain6
10.0.0.11 node01
10.0.0.12 node02
10.0.0.13 node03
10.0.0.14 node04
10.0.0.7 web
#查看版本
[root@node01 ~]# cat /etc/redhat-release
CentOS Linux release 7.6. (Core)
创建受信任地址池
主机node01添加
#在node01添加完个gluterfs服务端后不需要在其他主机上进行添加,它们是一个互联的关系,关系同等相互之间可以通信了。
[root@node01 ~]# gluster peer probe node02
[root@node01 ~]# gluster peer probe node03
[root@node01 ~]# glutser peer probe node04
查看地址池信息
#在主机node02上面查看
[root@node02 ~]# gluster peer status
Number of Peers: Hostname: node01
Uuid: f86a4fad-3c98-4e36-9d8e-d0e01db6b9d3
State: Peer in Cluster (Connected) Hostname: node03
Uuid: 61d970f4-11d8-4b39-a16a-7c9070a14ac7
State: Peer in Cluster (Connected) Hostname: node04
Uuid: 81f83924-b480-4a70-868c-59ebb1ab1583
State: Peer in Cluster (Connected)
格式化磁盘挂载
#node全部主机格式化磁盘
如果磁盘大于4T的话就使用parted命令进行分区
#查看所有主机的磁盘
[root@node ~]# fdisk -l
#格式化全部主机分区
[root@node ~]# mkfs.xfs /dev/sdb
[root@node ~]# mkfs.xfs /dev/sdc
挂载分区
#在xshell下选择全部会话进行创建
[root@node ~]# mkdir -p /data/gv{..5}
[root@node ~]# mount /dev/sdb /data/gv1
[root@node ~]# mount /dev/sdc /data/gv2
[root@node ~]# df -h
/dev/sdb 20G 33M 20G % /data/gv1
/dev/sdc 20G 33M 20G % /data/gv2
创建卷
#在node01上面操作
[root@node01 /]# gluster volume create gv1 node03:/data/gv1 node02:/data/gv2 force
volume create: gv1: success: please start the volume to access data
# 创建分布式卷,卷名是gv1 [root@node01 /]# gluster volume info gv1 #查看gv1卷的状态
Volume Name: gv1 #卷名:gv1
Type: Distribute #类型:分布式卷
Volume ID: 4dad3829--488e-812e-9a2b1833bc3b #卷的ID
Status: Created #状态:创建
Snapshot Count: #快照计数:
Number of Bricks: #块的数量:
Transport-type: tcp #传输类型:tcp协议
Bricks: #以下是哪些主机块的信息
Brick1: node03:/data/gv1
Brick2: node02:/data/gv2
Options Reconfigured: #选项配置
transport.address-family: inet
nfs.disable: on #nfs禁用:开启
客户端操作
Gluster Native Client 是基于FUSE的,所以需要保证客户安装了FUSE。这个官方推荐的客户端,支持高并发和高效的写性能。
客户端部署
#安装客户端软件
[root@web01 /]# yum install glusterfs-client -y
创建挂载目录
[root@web01 /]# mkdir /gv1
#这个目录需要挂载分布式文件系统服务 [root@web01 /]# mount.glusterfs node01:/gv1 /gv1
#进行挂载 `df -h` 命令会显示 [root@web01 /]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 49G .9G 47G % /
devtmpfs 476M 476M % /dev
tmpfs 487M 487M % /dev/shm
tmpfs 487M 7.7M 479M % /run
tmpfs 487M 487M % /sys/fs/cgroup
/dev/sda1 197M 105M 93M % /boot
tmpfs 98M 98M % /run/user/
node01:gv2 40G 475M 40G % /gv1
创建文件检验
#在目录创建目录
[root@web01 /]# cd /gv1
[root@web01 /gv1]# touch {..}
#node主机查看
[root@node02 /data/gv1]# ls [root@node03 /data/gv1]# ls
https://blog.csdn.net/w20010106/article/details/87994374参考:
GlusterFS ——分布式卷的更多相关文章
- GlusterFS 分布式文件系统的使用入门-管理GlusterFS卷
GlusterFS 分布式文件系统的使用入门-管理GlusterFS卷 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.卷的扩容 您可以根据需要在群集联机且可用时扩展卷.例如,您 ...
- GlusterFS分布式文件系统的使用
glusterfs是一款开源的分布式文件系统. 它具备高扩展.高可用及高性能等特性,由于其无元数据服务器的设计,使其真正实现了线性的扩展能力,使存储总容量可轻松达到PB级别,支持数千客户端并发访问. ...
- GlusterFS分布式文件系统部署及基本使用(CentOS 7.6)
GlusterFS分布式文件系统部署及基本使用(CentOS 7.6) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Gluster File System 是一款自由软件,主要由 ...
- GlusterFS六大卷模式說明
GlusterFS六大卷說明 第一,分佈卷 在分布式卷文件被随机地分布在整个砖的体积.使用分布式卷,你需要扩展存储,冗余是重要或提供其他硬件/软件层.(簡介:分布式卷,文件通过hash算法随机的分 ...
- Linux实战教学笔记52:GlusterFS分布式存储系统
一,分布式文件系统理论基础 1.1 分布式文件系统出现 计算机通过文件系统管理,存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量 ...
- GlusterFS分布式文件系统部署
GlusterFS是一个可伸缩的网络文件系统,使用常见的现成的硬件,您可以创建大型分布式存储流媒体解决方案.数据分析.和其他数据相关的任务.GlusterFS是自由和开源软件. 详细参考官网:http ...
- 【转载】GlusterFS六大卷模式說明
本文转载自翱翔的水滴<GlusterFS六大卷模式說明> GlusterFS六大卷說明 第一,分佈卷 在分布式卷文件被随机地分布在整个砖的体积.使用分布式卷,你需要扩展存储,冗余是重要或提 ...
- GlusterFS分布式文件系统高速管理
TaoCloud XDFS基于GlusterFS开源分布式文件系统,进行了系统优化.project化.定制化和产品化工作,五年以上的实践积累了大量实践经验,包含客户案例.最佳实践.定制开发.咨询服务和 ...
- GlusterFS分布式存储系统
一,分布式文件系统理论基础 1.1 分布式文件系统出现 计算机通过文件系统管理,存储数据,而现在数据信息爆炸的时代中人们可以获取的数据成指数倍的增长,单纯通过增加硬盘个数来扩展计算机文件系统的存储容量 ...
随机推荐
- Kubernetes中的PV和PVC
K8S引入了一组叫作Persistent Volume Claim(PVC)和Persistent Volume(PV)的API对象,大大降低了用户声明和使用持久化Volume的门槛.在Pod的Vol ...
- vue中封装swipe组件
<template> <!-- TODO swipe --> <div id="hy-swiper"> <div class=" ...
- 【MM系列】SAP技巧之更改布局
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP技巧之更改布局 前言部分 ...
- linux如何使用QQmail实现网络邮件报警?
环境:CentOS7 目的:考虑到实现服务的高可用性.使用电子邮件通知服务,可以快速的通知维护人员.提高服务的可靠性,而通过 smtp.qq.com 实现脚本邮件报警 一.设置并取得 smtp.qq. ...
- Spring体系
1.Spring简介 Spring是一个轻量级Java开发框架,最早有Rod Johnson创建,目的是为了解决企业级应用开发的业务逻辑层和其他各层的耦合问题.它是一个分层的JavaSE/JavaEE ...
- [python] a little deep learning case
from numpy import exp, array, random, dot class NeuralNetwork(): def __init__(self): random.seed(1) ...
- git diff 命令介绍
https://www.jianshu.com/p/6e1f7198e76a https://www.jianshu.com/p/5b6a014ac3db https://blog.csdn.net/ ...
- Ruby学习中(首探数组, 注释, 运算符, 三元表达式, 字符串)
一. 数组 1.定义一个数组 games = ["英雄联盟", "绝地求生", "钢铁雄心"] puts games 2.数组的循环 gam ...
- 【深入理解JVM】类加载器与双亲委派模型 (转)
出处: [深入理解JVM]类加载器与双亲委派模型 加载类的开放性 类加载器(ClassLoader)是Java语言的一项创新,也是Java流行的一个重要原因.在类加载的第一阶段“加载”过程中,需要通过 ...
- ASP.NET CORE CACHE的使用(含MemoryCache,Redis)
原文:ASP.NET CORE CACHE的使用(含MemoryCache,Redis) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接 ...