面试题:Nginx 是如何实现高并发?常见的优化手段有哪些?
面试题:
Nginx 是如何实现并发的?为什么 Nginx 不使用多线程?Nginx常见的优化手段有哪些?502错误可能原因有哪些?
面试官心理分析
主要是看应聘人员的对NGINX的基本原理是否熟悉,因为大多数运维人员多多少少都懂点NGINX,但是真正其明白原理的可能少之又少。明白其原理,才能做优化,否则只能照样搬样,出了问题也无从下手。
懂皮毛的人,一般会做个 Web Server,搭建一个 Web 站点;初级运维可能搞个 HTTPS 、配置一个反向代理; 中级运维定义个 upstream、写个正则判断;老鸟做个性能优化、写个ACL,还有可能改改源码(小编表示没有改源码的能力)。
面试题剖析
1. Nginx 是如何实现高并发的?
异步,非阻塞,使用了epoll 和大量的底层代码优化。
如果一个server采用一个进程负责一个request的方式,那么进程数就是并发数。正常情况下,会有很多进程一直在等待中。
而nginx采用一个master进程,多个woker进程的模式。
- master进程主要负责收集、分发请求。每当一个请求过来时,master就拉起一个worker进程负责处理这个请求。
- 同时master进程也负责监控woker的状态,保证高可靠性
- woker进程一般设置为跟cpu核心数一致。nginx的woker进程在同一时间可以处理的请求数只受内存限制,可以处理多个请求。
Nginx 的异步非阻塞工作方式正把当中的等待时间利用起来了。在需要等待的时候,这些进程就空闲出来待命了,因此表现为少数几个进程就解决了大量的并发问题。
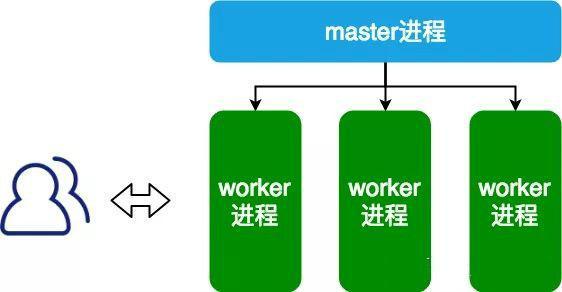
每进来一个request,会有一个worker进程去处理。但不是全程的处理,处理到什么程度呢?处理到可能发生阻塞的地方,比如向上游(后端)服务器转发request,并等待请求返回。那么,这个处理的worker很聪明,他会在发送完请求后,注册一个事件:“如果upstream返回了,告诉我一声,我再接着干”。于是他就休息去了。此时,如果再有request 进来,他就可以很快再按这种方式处理。而一旦上游服务器返回了,就会触发这个事件,worker才会来接手,这个request才会接着往下走。
2. 为什么 Nginx 不使用多线程?
Apache: 创建多个进程或线程,而每个进程或线程都会为其分配 cpu 和内存(线程要比进程小的多,所以worker支持比perfork高的并发),并发过大会耗光服务器资源。
Nginx: 采用单线程来异步非阻塞处理请求(管理员可以配置Nginx主进程的工作进程的数量)(epoll),不会为每个请求分配cpu和内存资源,节省了大量资源,同时也减少了大量的CPU的上下文切换。所以才使得Nginx支持更高的并发。
3. Nginx常见的优化配置有哪些?

(1) 调整worker_processes
指Nginx要生成的worker数量,***实践是每个CPU运行1个工作进程。
了解系统中的CPU核心数,输入
- $ grep processor / proc / cpuinfo | wc -l
(2) ***化worker_connections
Nginx Web服务器可以同时提供服务的客户端数。与worker_processes结合使用时,获得每秒可以服务的***客户端数
***客户端数/秒=工作进程*工作者连接数
为了***化Nginx的全部潜力,应将工作者连接设置为核心一次可以运行的允许的***进程数1024。
(3) 启用Gzip压缩
压缩文件大小,减少了客户端http的传输带宽,因此提高了页面加载速度
建议的gzip配置示例如下:( 在http部分内)

(4) 为静态文件启用缓存
为静态文件启用缓存,以减少带宽并提高性能,可以添加下面的命令,限定计算机缓存网页的静态文件:
- location ~* .(jpg|jpeg|png|gif|ico|css|js)$ {
- expires 365d;
- }
(5) Timeouts
keepalive连接减少了打开和关闭连接所需的CPU和网络开销,获得***性能需要调整的变量可参考:

(6) 禁用access_logs
访问日志记录,它记录每个nginx请求,因此消耗了大量CPU资源,从而降低了nginx性能。
完全禁用访问日志记录
- access_log off;
如果必须具有访问日志记录,则启用访问日志缓冲
- access_log /var/log/nginx/access.log主缓冲区= 16k
4. 502报错可能原因有哪些?

(1) FastCGI进程是否已经启动
(2) FastCGI worker进程数是否不够
(3) FastCGI执行时间过长
(4) FastCGI Buffer不够
nginx和apache一样,有前端缓冲限制,可以调整缓冲参数
- fastcgi_buffer_size 32k;
- fastcgi_buffers 8 32k;
(5) Proxy Buffer不够
如果你用了Proxying,调整
- proxy_buffer_size 16k;
- proxy_buffers 4 16k;
(6) php脚本执行时间过长
将php-fpm.conf的
- <value name="request_terminate_timeout">0s</value>
0s改成一个时间
面试题:Nginx 是如何实现高并发?常见的优化手段有哪些?的更多相关文章
- Nginx与Redis解决高并发问题
原文链接:http://bbs.phpchina.com/forum.php?mod=viewthread&tid=229629 第一版产品采用的是Jquery,Nginx,PHP(CI框架) ...
- nginx+lua+redis构建高并发应用(转)
nginx+lua+redis构建高并发应用 ngx_lua将lua嵌入到nginx,让nginx执行lua脚本,高并发,非阻塞的处理各种请求. url请求nginx服务器,然后lua查询redis, ...
- 15套java架构师、集群、高可用、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩展. ...
- 15套java架构师、集群、高可用、高可扩 展、高性能、高并发、性能优化Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
- tengine编译安装及nginx高并发内核参数优化
Tengine Tengine介绍 Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能和特性. Tengine的性能和稳定性已经在大型的 ...
- sql 数据量高并发的数据库优化(转)
Mysql 大数据量高并发的数据库优化 一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实 ...
- nginx应用总结(2)--突破高并发的性能优化
在日常的运维工作中,经常会用到nginx服务,也时常会碰到nginx因高并发导致的性能瓶颈问题.今天这里简单梳理下nginx性能优化的配置(仅仅依据本人的实战经验而述,如有不妥,敬请指出~) 一.这里 ...
- Nginx和Tengine解决高并发和高可用,而非推荐Apache
什么是Nginx 什么是Tengine 看看国内大公司在用Nginx和Tengine吗? 步骤一:进入 https://www.taobao.com/,按F12.可看到 有很多APP对淘宝进行请求. ...
- Nginx+Redis+Ehcache大型高并发高可用三层架构总结
在生产环境中,对于高并发架构,我们知道缓存 是最重要的环节,对于大量的高并发.可以采用三层缓存架构来实现,也就是Nginx+Redis+Ehcache 对于中间件Nginx常来做流量分发,同事ngin ...
随机推荐
- document.domain vs location.hostname vs location.host
限制是同源政策的相同规则 document.domain 获取域名 location.hostname 获取域名 location.host 获取域名+端口 document.domain ...
- Codeforces 1091C (数学)
题面 传送门 分析 假设k是固定的,那访问到的节点编号就是\(1+(a·k \mod n )\),其中a为正整数. 通过找规律不难发现会出现循环. 通过题目中的图片我们不难发现 只有k=1,2,3,6 ...
- Topcoder SRM653div2
A . 250 Problem Statement Some people are sitting in a row. Each person came here from some cou ...
- SR-IOV
SR-IOV 来源 http://blog.csdn.net/liushen0916/article/details/52423507 摘要: 介绍SR-IOV 的概念.使用场景.VMware 和 K ...
- k3 cloud中库存转移处理
有个苗木基地的苗木要转移到另一个,是做那个单据 解决办法:两个基地是同一组织 做直接调拨单就行了 ,不同组织做调拨申请单,然后做 分布式调出 分布式调入
- Spring MVC 跳转失败,但配置正确填坑
1:正确写法 @RequestMapping("{type_key}.html") public String geren(Model model, @PathVariable S ...
- ServletContext对象初识
什么是ServletContext? ServletContext代表一个web应用的环境(上下文)对象,ServletContext对象内部封装的是该web应用的信息.一个web应用只有一个Serv ...
- Java中实现线程同步的三种方法
实现同步的三种方法 多线程共享数据时,会发生线程不安全的情况,多线程共享数据必须同步. 实现同步的三种方法: 使用同步代码块 使用同步方法 使用互斥锁ReetrantLock(更灵活的代码控制) 代码 ...
- after()和append()的区别、before()和prepend()区别、appendTo()和prependTo()、insertAfter()和insertBefore()
一.after()和before()方法的区别 after()——其方法是将方法里面的参数添加到jquery对象后面去: 如:A.after(B)的意思是将B放到A后面去: before( ...
- SecureCRT 多窗口 批量操作Linux
1.打开多个窗口 2.Window --> Tile Verically将窗口并列展开 3.右击空白部分选择弹出下方的命令窗口 4.右击命令行窗口,选择发送命令至所有窗口 5.完成