Spark在MaxCompute的运行方式
一、Spark系统概述
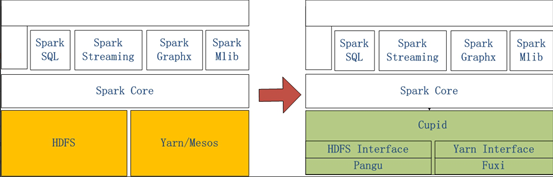
左侧是原生Spark的架构图,右边Spark on MaxCompute运行在阿里云自研的Cupid的平台之上,该平台可以原生支持开源社区Yarn所支持的计算框架,如Spark等。
二、Spark运行在客户端的配置和使用
2.1打开链接下载客户端到本地
2.2将文件上传的ECS上
2.3将文件解压
tar -zxvf spark-2.3.0-odps0.30.0.tar.gz

2.4配置Spark-default.conf
# spark-defaults.conf
# 一般来说默认的template只需要再填上MaxCompute相关的账号信息就可以使用Spark
spark.hadoop.odps.project.name =
spark.hadoop.odps.access.id =
spark.hadoop.odps.access.key =
# 其他的配置保持自带值一般就可以了
spark.hadoop.odps.end.point = http://service.cn.maxcompute.aliyun.com/api
spark.hadoop.odps.runtime.end.point = http://service.cn.maxcompute.aliyun-inc.com/api
spark.sql.catalogImplementation=odps
spark.hadoop.odps.task.major.version = cupid_v2
spark.hadoop.odps.cupid.container.image.enable = true
spark.hadoop.odps.cupid.container.vm.engine.type = hyper
2.5在github上下载对应代码
https://github.com/aliyun/MaxCompute-Spark
2.5将代码上传到ECS上进行解压
unzip MaxCompute-Spark-master.zip
2.6将代码打包成jar包(确保安装Maven)
cd MaxCompute-Spark-master/spark-2.x
mvn clean package
2.7查看jar包,并进行运行
bin/spark-submit --master yarn-cluster --class com.aliyun.odps.spark.examples.SparkPi \
MaxCompute-Spark-master/spark-2.x/target/spark-examples_2.11-1.0.0-SNAPSHOT-shaded.jar
三、Spark运行在DataWorks的配置和使用
3.1进入DataWorks控制台界面,点击业务流程
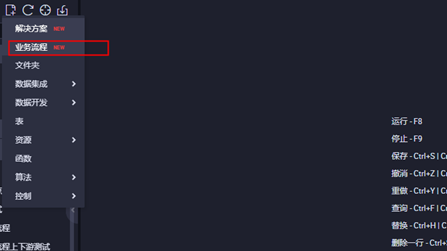
3.2打开业务流程,创建ODPS Spark节点
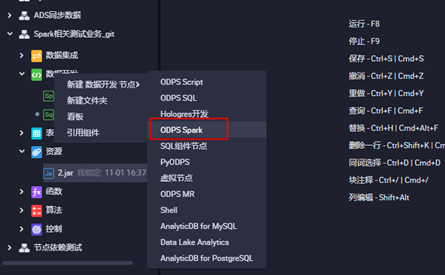
3.3上传jar包资源,点击对应的jar包上传,并提交
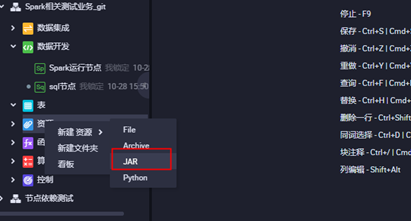
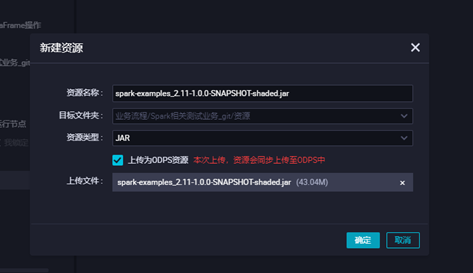
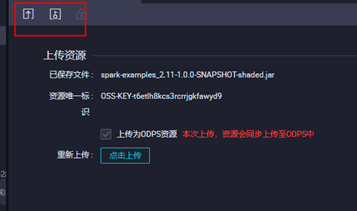
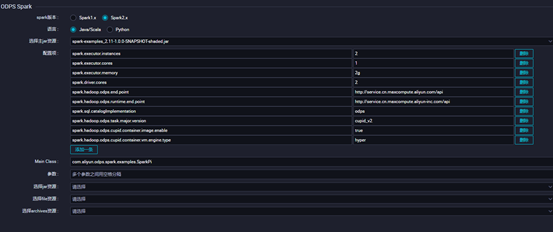
3.4配置对应ODPS Spark的节点配置点击保存并提交,点击运行查看运行状态
四、Spark在本地idea测试环境的使用
4.1下载客户端与模板代码并解压
模板代码:
https://github.com/aliyun/MaxCompute-Spark
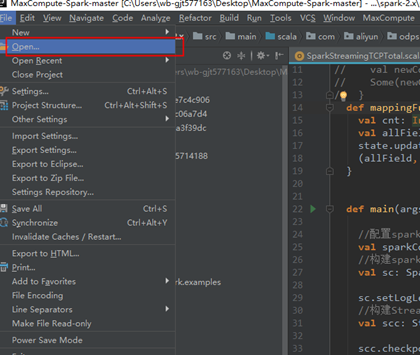
4.2打开idea,点击Open选择模板代码
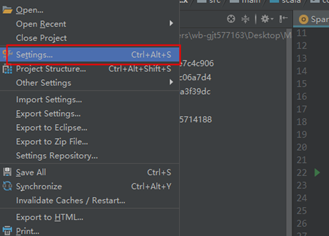
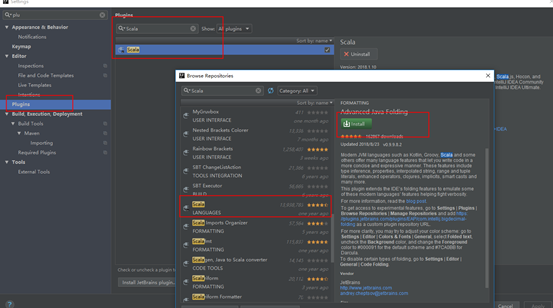
4.2安装Scala插件
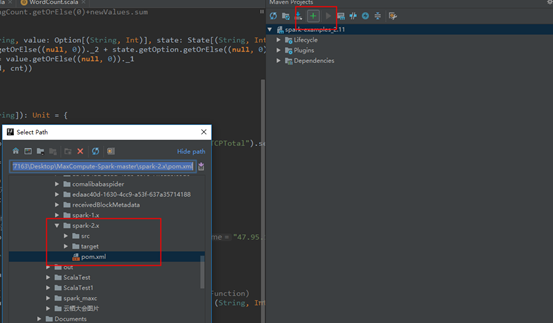
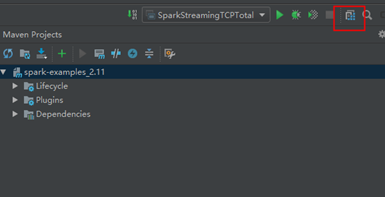
4.3配置maven
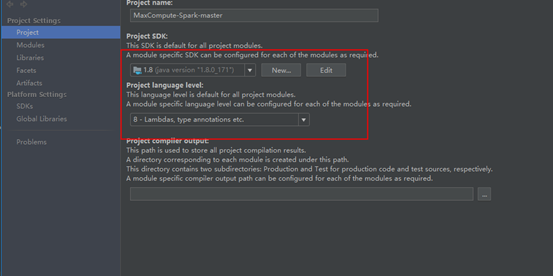
4.4配置JDK和相关依赖
本文作者:耿江涛
本文为云栖社区原创内容,未经允许不得转载。
Spark在MaxCompute的运行方式的更多相关文章
- 「Spark」Spark SQL Thrift Server运行方式
Spark SQL可以使用JDBC/ODBC或命令行接口充当分布式查询引擎.这种模式,用户或者应用程序可以直接与Spark SQL交互,以运行SQL查询,无需编写任何代码. Spark SQL提供两种 ...
- MaxCompute Spark开发指南
0. 概述 本文档面向需要使用MaxCompute Spark进行开发的用户使用.本指南主要适用于具备有Spark开发经验的开发人员. MaxCompute Spark是MaxCompute提供的兼容 ...
- MaxCompute问答整理之7月
本文是基于本人对MaxCompute产品的学习进度,再结合开发者社区里面的一些问题,进而整理成文.希望对大家有所帮助. 问题一.DataWorks V2.0简单模式和标准模式的区别?公司数仓的数据上云 ...
- 阿里云大数据计算服务 - MaxCompute (原名 ODPS)
MaxCompute 是阿里EB级计算平台,经过十年磨砺,它成为阿里巴巴集团数据中台的计算核心和阿里云大数据的基础服务.去年MaxCompute 做了哪些工作,这些工作背后的原因是什么?大数据市场进入 ...
- 一文快速了解MaxCompute
很多刚初次接触MaxCompute的用户,面对繁多的产品文档内容以及社区文章,往往很难快速.全面了解MaxCompute产品全貌.同时,很多拥有大数据开发经验的开发者,也希望能够结合自身的背景知识,将 ...
- spark学习(基础篇)--(第三节)Spark几种运行模式
spark应用执行机制分析 前段时间一直在编写指标代码,一直采用的是--deploy-mode client方式开发测试,因此执行没遇到什么问题,但是放到生产上采用--master yarn-clus ...
- 【互动问答分享】第10期决胜云计算大数据时代Spark亚太研究院公益大讲堂
“决胜云计算大数据时代” Spark亚太研究院100期公益大讲堂 [第10期互动问答分享] Q1:Spark on Yarn的运行方式是什么? Spark on Yarn的运行方式有两种:Client ...
- Hive数据如何同步到MaxCompute之实践讲解
摘要:本次分享主要介绍 Hive数据如何迁移到MaxCompute.MMA(MaxCompute Migration Assist)是一款MaxCompute数据迁移工具,本文将为大家介绍MMA工具的 ...
- MaxCompute新功能发布
2018年Q3 MaxCompute重磅发布了一系列新功能. 本文对主要新功能和增强功能进行了概述. 实时交互式查询:Lightning on MaxCompute 生态兼容:Spark on Max ...
随机推荐
- ConcurrentLinkedQueue 源码分析
ConcurrentLinkedQueue ConcurrentLinkedQueue 能解决什么问题?什么时候使用 ConcurrentLinkedQueue? 1)ConcurrentLinked ...
- SynchronousQueue 源码分析
SynchronousQueue SynchronousQueue 能解决什么问题?什么时候使用 SynchronousQueue? 1)SynchronousQueue 没有任何内部容量. 2)Sy ...
- python-异常处理总结
一.异常处理 在程序运行的过程中,总会遇到各种各样的错误.程序一出错就停止运行了,下面的代码就不能运行了:这时候就需要捕捉异常,通过捕捉异常,再去做对应的处理. e.g: info = { " ...
- Git 实践
最近也学习了Git的相关知识,现通过一个实例来记录Git使用流程,也方便日后使用. git的基础学习: https://www.yiibai.com/git/git-quick-start.html ...
- 字符串中的TRIM操作
std::string& ltrim(std::string& str, const std::string& chars = "\t\n\v\f\r ") ...
- Ora01653 :是表空间不足
解决方案:表空间中增加数据文件: ALTER TABLESPACE 表空间名称ADD DATAFILE 'D:\app\Administrator\oradata\orcl\Ibomis1.dbf' ...
- altium笔记转载
原理图的设计 1.左键单击元器件按住space键可以将其旋转,按X键左右旋转:按Y键上下旋转. 2.智能粘贴:Edit àsmart paste . 3.屏障:compile mask(编译时被屏障的 ...
- Jmeter之Json表达式关联
Jmeter使用中,通常用的最多的是正则表达式和Xpath表达式,但是现在大多数网站都用的Json返回数据,而且数据还特长的那种,作为合格的测试人员也要适应技术潮流发展,下面介绍利用Json Extr ...
- Java-集合第四篇Queue集合
1.什么是Queue 模拟队列数据结构,先进先出(FIFO),从队尾加元素,从队头取元素. 2.Queue接口中定义了如下几个方法: 1>void add(Object o):将指定元素 ...
- HDU.6186.CSCource.(前缀和数组和后缀和数组)
明天后天是南昌赛了嘤嘤嘤,这几天就先不更新每日题目了,以后补题嘤嘤嘤. 今天和队友做了一套2017年广西邀请赛,5个题还是有点膨胀...... 好了,先来说一下有意思的题目吧...... CS Cou ...