HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制
0)启动概述
Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。但是此刻,namenode运行在安全模式,即namenode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,namenode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以namenode不会进入安全模式。
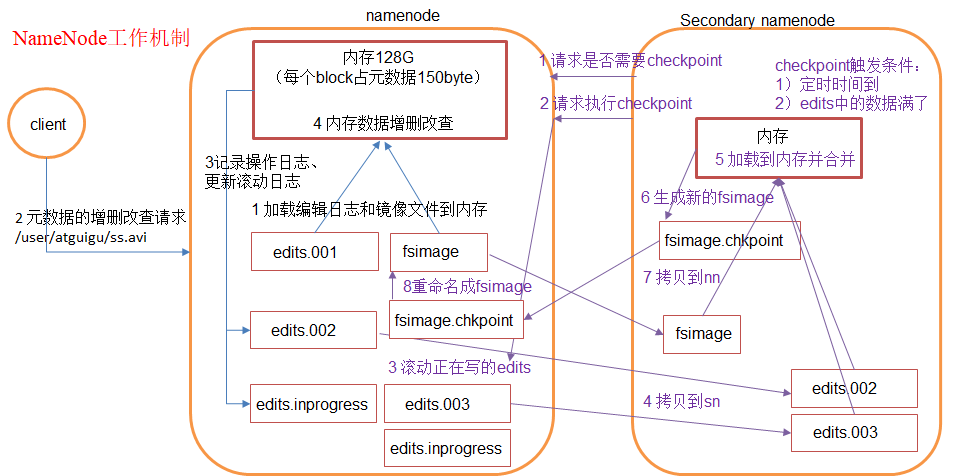
1)第一阶段:namenode启动(根据客户端的请求记录fsimage和edits,在内存中进行增删改查)
(1)第一次启动namenode格式化后,创建HDFS镜像文件fsimage和编辑日志文件edits。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(HDFS的镜像文件FsImage包含着集群所有文件的元数据信息;编辑日志edits类似“账本”记录数据操作)
(2)客户端对元数据进行增删改的请求
(3)namenode记录操作日志,更新滚动日志(“记账”)到edits.002、edits.inprogress为接下来用的edits
(4)namenode在内存中对数据进行增删改查
2)第二阶段:Secondary NameNode工作(帮助NameNode具体操作edits和fsimage文件,NameNode只是在内存中执行增删改查)
(1)Secondary NameNode询问namenode是否需要checkpoint。直接带回namenode是否检查结果。
(checkpoint判断条件:① 定时时间到,默认1小时 ② edits中造作动作次数已满,默认100万)
(2)Secondary NameNode请求执行checkpoint。
(3)namenode滚动正在写的edits日志(将目前的edits.inprogress写入edits.003)
(4)将滚动前的编辑日志(edits.002、edits.003)和镜像文件拷贝到Secondary NameNode
(5)Secondary NameNode将编辑日志和镜像文件加载到内存并合并。
(6)生成新的镜像文件fsimage.chkpoint
(7)拷贝fsimage.chkpoint到namenode
(8)namenode将fsimage.chkpoint重新命名成fsimage
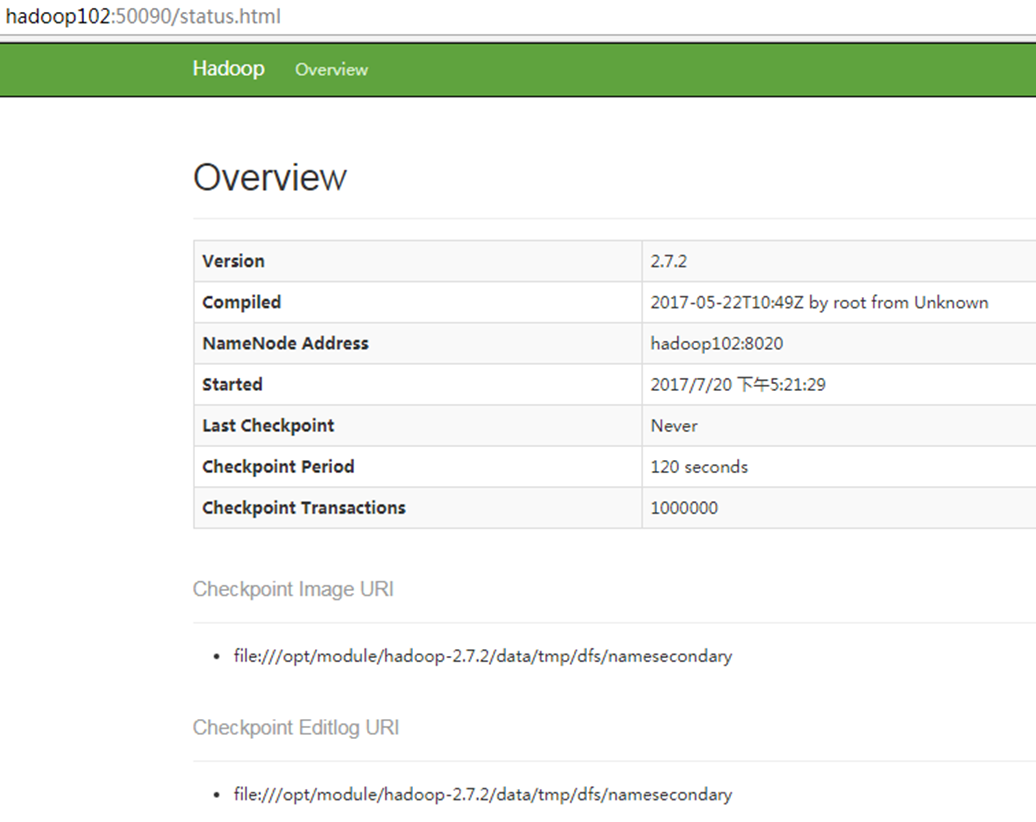
3)web端访问SecondaryNameNode
(1)启动集群
(2)浏览器中输入:http://hadoop102:50090/status.html
(3)查看SecondaryNameNode信息
4)chkpoint检查时间参数设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property> <property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
HDFS中NameNode和Secondary NameNode工作机制的更多相关文章
- NameNode和SecondaryNameNode的工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- NameNode 与 SecondaryNameNode 的工作机制
一.NameNode.Fsimage .Edits 和 SecondaryNameNode 概述 NameNode:在内存中储存 HDFS 文件的元数据信息(目录) 如果节点故障或断电,存在内存中的数 ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- hdfs namenode/datanode工作机制
一. namenode工作机制 1. 客户端上传文件时,namenode先检查有没有同名的文件,如果有,则直接返回错误信息.如果没有,则根据要上传文件的大小以及block的大小,算出需要分成几个blo ...
- HDFS中NameNode管理元数据机制
NameNode职责 响应客户端请求 维护目录树 管理元数据(查询,修改) HDFS元数据存储 内存中有一份完整的元数据(特定数据结构) 磁盘有一个“准完整”的元数据的镜像文件 当客户端对HDFS中的 ...
- Hadoop- NameNode和Secondary NameNode元数据管理机制
元数据的存储机制 A.内存中有一份完整的元数据(内存meta data) B.磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中) C.用于衔接内存metadata ...
- Secondary NameNode:的作用?
前言 最近刚接触Hadoop, 一直没有弄明白NameNode和Secondary NameNode的区别和关系.很多人都认为,Secondary NameNode是NameNode的备份,是为了防止 ...
- 深刻理解HDFS工作机制
深入理解一个技术的工作机制是灵活运用和快速解决问题的根本方法,也是唯一途径.对于HDFS来说除了要明白它的应用场景和用法以及通用分布式架构之外更重要的是理解关键步骤的原理和实现细节.在看这篇博文之前需 ...
- Secondary NameNode 的作用
https://blog.csdn.net/xh16319/article/details/31375197 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止Na ...
随机推荐
- HDU 5418 Victor and World (状态压缩dp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5418 题目大意:有n个结点m条边(有边权)组成的一张连通图(n <16, m<100000 ...
- win10如何设置软件开机启动
想要实现应用程序在所有的用户登录系统后都能自动启动,就把该应用程序的快捷方式放到“系统启动文件夹”里C:\ProgramData\Microsoft\Windows\Start Menu\Progra ...
- es6的...用法
...将一个数组转为用符号分隔的参数序列 1.console.log(1, ...[2, 3, 4], 5) // 1 2 3 4 5 2. var args = [0, 1, 2]; f.apply ...
- ASP.NET的OnClientClick与OnClick事件
OnClientClick是客户端事件方法.一般采用JavaScript来进行处理.也就是直接在IE端运行.一点击就运行. OnClick事件是服务器端事件处理方法,在服务器端,也就是IIS中运行.点 ...
- Java——常用类(基础类型数据包装类)
[包装类] 包装类(如Integer.Double等)这些类封装了一个相应的基础数据类型数值,并为其提供了一系列操作. 例如:java.lang.Integer类提供了以下构造方法: ...
- 【bzoj3566】 [SHOI2014]概率充电器
*题目描述: 著名的电子产品品牌 SHOI 刚刚发布了引领世界潮流的下一代电子产品——概率充电器: “采用全新纳米级加工技术,实现元件与导线能否通电完全由真随机数决定!SHOI 概率充电器,您生活不可 ...
- RedisTemplate访问Redis数据结构(五)——ZSet
Redis 有序集合和无序集合一样也是string类型元素的集合,且不允许重复的成员.不同的是每个元素都会关联一个double类型的分数.有序集合的成员是唯一的,但分数(score)却可以重复.red ...
- vue 通过绑定事件获取当前行的id
<div @click="router(items.productId)" style="float: left;" :key='items.produc ...
- loadrunner常用函数整理
1.int web_reg_save_param("参数名","LB=左边界","RB=右边界",LAST); //注册函数,在参数值出 ...
- ReentrantLock 源码分析
ReentrantLock 1)ReentrantLock 类实现了和 synchronized 一样的内存语义,同时该类提供了更加灵活多样的可重入互斥锁定操作. 2)ReentrantLock 实例 ...