DolphinScheduler源码分析之任务日志
DolphinScheduler源码分析之任务日志
任务日志打印在调度系统中算是一个比较重要的功能,下面就简要分析一下其打印的逻辑和前端页面查询的流程。
AbstractTask
所有的任务都会继承AbstractTask,这个抽象类有一个比较重要的字段就是logger,其实也就是一个org.slf4j.Logger对象。
也就是说所有的任务都是通过slf4j打印日志的。那这个logger是如何创建的呢?
Logger taskLogger = LoggerFactory.getLogger(LoggerUtils.buildTaskId(LoggerUtils.TASK_LOGGER_INFO_PREFIX,
taskInstance.getProcessDefine().getId(),
taskInstance.getProcessInstance().getId(),
taskInstance.getId()));
public static String buildTaskId(String affix,
int processDefId,
int processInstId,
int taskId){
// - [taskAppId=TASK_79_4084_15210]
return String.format(" - [taskAppId=%s-%s-%s-%s]",affix,
processDefId,
processInstId,
taskId);
}
非常简单,就是通过LoggerFactory.getLogger获取的,名字是由流程定义ID、流程实例ID、任务ID拼接成的。前端查询日志时,taskAppId其实就是logger的名称。通过下图可以很直观的看到,当前任务的流程定义ID是1,流程实例ID是2,任务ID是2 
其实分析到这里,并没有证明最终的进程把日志通过logger写到文件,至少目前没有看到相关的代码。为了更加直观的证明,我们选择Shell类型的任务来分析打印日志的方式。因为它最终创建了一个shell子进程,如果要通过logger字段打印日志,一定会有相关的代码。
ShellCommandExecutor
Shell类型的任务是通过ShellCommandExecutor去执行具体的shell脚本的。
/**
* constructor
* @param logHandler log handler
* @param taskDir task dir
* @param taskAppId task app id
* @param taskInstId task instance id
* @param tenantCode tenant code
* @param envFile env file
* @param startTime start time
* @param timeout timeout
* @param logger logger
*/
public ShellCommandExecutor(Consumer<List<String>> logHandler,
String taskDir,
String taskAppId,
int taskInstId,
String tenantCode,
String envFile,
Date startTime,
int timeout,
Logger logger)
上面是ShellCommandExecutor的构造函数,通过注释以及参数命名大概可以猜到,logHandler是最终打印日志的地方。下面从其赋值以及如何使用分析日志究竟是不是logger打印的。
this.shellCommandExecutor = new ShellCommandExecutor(this::logHandle, taskProps.getTaskDir(),
taskProps.getTaskAppId(),
taskProps.getTaskInstId(),
taskProps.getTenantCode(),
taskProps.getEnvFile(),
taskProps.getTaskStartTime(),
taskProps.getTaskTimeout(),
logger);
ShellCommandExecutor创建的时候,logHandler是通过ShellTask的logHandle方法赋值的。
/**
* log handle
* @param logs log list
*/
public void logHandle(List<String> logs) {
// note that the "new line" is added here to facilitate log parsing
logger.info(" -> {}", String.join("\n\t", logs));
}
上面是logHandle的方法定义,很明显就是通过logger打印日志的。
那logHandler是什么时候使用的呢?
AbstractCommandExecutor
ShellCommandExecutor继承了AbstractCommandExecutor,在AbstractCommandExecutor.run中调用了一个非常重要的方法:parseProcessOutput
private void parseProcessOutput(Process process) {
String threadLoggerInfoName = String.format(LoggerUtils.TASK_LOGGER_THREAD_NAME + "-%s", taskAppId);
ExecutorService parseProcessOutputExecutorService = ThreadUtils.newDaemonSingleThreadExecutor(threadLoggerInfoName);
parseProcessOutputExecutorService.submit(new Runnable(){
@Override
public void run() {
BufferedReader inReader = null;
try {
inReader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
long lastFlushTime = System.currentTimeMillis();
while ((line = inReader.readLine()) != null) {
logBuffer.add(line);
lastFlushTime = flush(lastFlushTime);
}
} catch (Exception e) {
logger.error(e.getMessage(),e);
} finally {
clear();
close(inReader);
}
}
});
parseProcessOutputExecutorService.shutdown();
}
parseProcessOutput这个方法就是把Process的标准输入输出打印到了logBuffer中,然后根据条件flush。
private long flush(long lastFlushTime) {
long now = System.currentTimeMillis();
/**
* when log buffer siz or flush time reach condition , then flush
*/
if (logBuffer.size() >= Constants.defaultLogRowsNum || now - lastFlushTime > Constants.defaultLogFlushInterval) {
lastFlushTime = now;
/** log handle */
logHandler.accept(logBuffer);
logBuffer.clear();
}
return lastFlushTime;
}
flush就是根据条件(大小、时间)把logBuffer中的内容,通过logHandler打印,其实就是通过logger打印到文件。
分析到这个地方,我们才真正清楚,任务其实就是通过slf4j打印到文件。那么问题又来了,前端是如何查询日志文件的呢?日志文件的路径前端是如何找到的呢?
logback.xml
既然我们知道了是slf4j在打印日志,那么配置文件在哪里呢?
在dolphinscheduler-server模块的resources目录下,有两个logback.xml文件:worker_logback.xml、master_logback.xml。任务打印日志的配置应该是worker_logback.xml,在哪里指定的呢?
dolphinscheduler-daemon.sh文件中有一个关于日志的配置。
-Dlogging.config=classpath:master_logback.xml

上面是worker_logback.xml,可以看到有两个appender,其中TASKLOGFILE是我们关注的对象。它有一个比较关键的filter,根据logback中filter的概念来猜测,这应该就是用来区分workerlogfile这个appender的。也就是说两个appender,会通过filter分别筛选出各自的日志进行打印。
/**
* Accept or reject based on thread name
* @param event event
* @return FilterReply
*/
@Override
public FilterReply decide(ILoggingEvent event) {
if (event.getThreadName().startsWith(LoggerUtils.TASK_LOGGER_THREAD_NAME) || event.getLevel().isGreaterOrEqual(level)) {
return FilterReply.ACCEPT;
}
return FilterReply.DENY;
}
这个filter根据日志级别和线程名过滤,符合条件的才能打印到当前appender。其实也就是只打印任务线程的日志。
当然了,还配置了Discriminator,它限定了logger的名称符合前面的定义。
/**
* logger name should be like:
* Task Logger name should be like: Task-{processDefinitionId}-{processInstanceId}-{taskInstanceId}
*/
@Override
public String getDiscriminatingValue(ILoggingEvent event) {
String loggerName = event.getLoggerName()
.split(Constants.EQUAL_SIGN)[1];
String prefix = LoggerUtils.TASK_LOGGER_INFO_PREFIX + "-";
if (loggerName.startsWith(prefix)) {
return loggerName.substring(prefix.length(),
loggerName.length() - 1).replace("-","/");
} else {
return "unknown_task";
}
}
LoggerController
前面的分析我们知道,任务的日志其实就是打印到本地日志文件中,那么前端查询的时候估计就是直接读取日志文件然后返回。
但有一个很现实的问题,任务是随机分布在各个worker的,如何读取日志文件呢?
LoggerController.queryLog就是用来查询日志的,它调用了LoggerService.queryLog
public Result queryLog(int taskInstId, int skipLineNum, int limit) {
TaskInstance taskInstance = processDao.findTaskInstanceById(taskInstId);
if (taskInstance == null){
return new Result(Status.TASK_INSTANCE_NOT_FOUND.getCode(), Status.TASK_INSTANCE_NOT_FOUND.getMsg());
}
String host = taskInstance.getHost();
if(StringUtils.isEmpty(host)){
return new Result(Status.TASK_INSTANCE_NOT_FOUND.getCode(), Status.TASK_INSTANCE_NOT_FOUND.getMsg());
}
Result result = new Result(Status.SUCCESS.getCode(), Status.SUCCESS.getMsg());
logger.info("log host : {} , logPath : {} , logServer port : {}",host,taskInstance.getLogPath(),Constants.RPC_PORT);
LogClient logClient = new LogClient(host, Constants.RPC_PORT);
String log = logClient.rollViewLog(taskInstance.getLogPath(),skipLineNum,limit);
result.setData(log);
logger.info(log);
return result;
}
LoggerService.queryLog的逻辑其实就是通过任务实例ID,查询到了任务所在节点以及日志路径,通过LogClient读取日志。当然了,读取的时候,有限定跳过的行数以及需要读取的行数。
LogClient.rollViewLog其实就是一次rpc调用,它连接到对应host的50051端口,读取日志。
LoggerServer
LoggerServer其实就是一个socket服务,它监听Constants.RPC_PORT(50051)端口的连接,交给LogViewServiceGrpcImpl处理对应的rpc请求。
/**
* server start
* @throws IOException io exception
*/
public void start() throws IOException {
/* The port on which the server should run */
int port = Constants.RPC_PORT;
server = ServerBuilder.forPort(port)
.addService(new LogViewServiceGrpcImpl())
.build()
.start();
logger.info("server started, listening on port : {}" , port);
Runtime.getRuntime().addShutdownHook(new Thread() {
@Override
public void run() {
// Use stderr here since the logger may have been reset by its JVM shutdown hook.
logger.info("shutting down gRPC server since JVM is shutting down");
LoggerServer.this.stop();
logger.info("server shut down");
}
});
}
rollViewLog的实现如下,其实也比较简单,就是调用readFile读取日志文件,然后返回。
public void rollViewLog(LogParameter request, StreamObserver<RetStrInfo> responseObserver) {
logger.info("log parameter path : {} ,skip line : {}, limit : {}",
request.getPath(),
request.getSkipLineNum(),
request.getLimit());
List<String> list = readFile(request.getPath(), request.getSkipLineNum(), request.getLimit());
StringBuilder sb = new StringBuilder();
boolean errorLineFlag = false;
for (String line : list){
sb.append(line + "\r\n");
}
RetStrInfo retInfoBuild = RetStrInfo.newBuilder().setMsg(sb.toString()).build();
responseObserver.onNext(retInfoBuild);
responseObserver.onCompleted();
}
总结
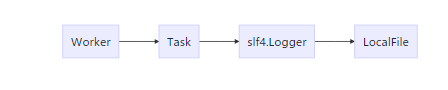
上面是一个简单的流程图,是worker写入日志的流程。

这是一个前端读取日志的路程,读取日志的请求按照箭头方向传递,最终由LoggerServer读取本地日志返回给远程的ApiServer,ApiServer返回给前端。
DolphinScheduler源码分析之任务日志的更多相关文章
- DolphinScheduler源码分析
DolphinScheduler源码分析 本博客是基于1.2.0版本进行分析,与最新版本的实现有一些出入,还请读者辩证的看待本源码分析.具体细节可能描述的不是很准确,仅供参考 源码版本 1.2.0 技 ...
- 8. SOFAJRaft源码分析— 如何实现日志复制的pipeline机制?
前言 前几天和腾讯的大佬一起吃饭聊天,说起我对SOFAJRaft的理解,我自然以为我是很懂了的,但是大佬问起了我那SOFAJRaft集群之间的日志是怎么复制的? 我当时哑口无言,说不出是怎么实现的,所 ...
- DolphinScheduler源码分析之EntityTestUtils类
1 /* 2 * Licensed to the Apache Software Foundation (ASF) under one or more 3 * contributor license ...
- 源码分析之spring-JdbcTemplate日志打印sql语句
对于开源的项目来说的好处就是我们遇到什么问题可以通过看源码来解决. 比如近期有个同事问我说,为啥JdbcTemplate中只有在Error的时候才打印出sql语句呢.我一想,这和log的配置有关系吧. ...
- DolphinScheduler 源码分析之 DAG类
1 /* 2 * Licensed to the Apache Software Foundation (ASF) under one or more 3 * contributor license ...
- HDFS源码分析之编辑日志编辑相关双缓冲区EditsDoubleBuffer
EditsDoubleBuffer是为edits准备的双缓冲区.新的编辑被写入第一个缓冲区,同时第二个缓冲区可以被flush.为edits准备的双缓冲区.新的编辑被写入第一个缓冲区,同时第二个缓冲区可 ...
- [Abp vNext 源码分析] - 文章目录
一.简要介绍 ABP vNext 是 ABP 框架作者所发起的新项目,截止目前 (2019 年 2 月 18 日) 已经拥有 1400 多个 Star,最新版本号为 v 0.16.0 ,但还属于预览版 ...
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- HDFS源码分析EditLog之获取编辑日志输入流
在<HDFS源码分析之EditLogTailer>一文中,我们详细了解了编辑日志跟踪器EditLogTailer的实现,介绍了其内部编辑日志追踪线程EditLogTailerThread的 ...
随机推荐
- 宝塔面板管理阿里云服务器FTP不能用
# 宝塔面板管理阿里云,ftp不能用 解决方法 搜ftp点击设置 然后Ctrl+F搜索ForcePassiveIP 注意2在默认情况下是带#号的,去掉#号,后面的ip地址是阿里云的公网ip 重启,再次 ...
- pku-3321 Apple Tree(dfs序+树状数组)
Description There is an apple tree outside of kaka's house. Every autumn, a lot of apples will grow ...
- Docker(二):理解容器编排工具Kubernetes内部工作原理
一.Kubernetes是什么 要说到Docker就不得不说说Kubernetes.当Docker容器在微服务的环境下数量一多,那么统一的,自动化的管理自然少不了.而Kubernetes就是一个这样的 ...
- 尝试在阿里云的Linux服务器器上安装拥有图形界面的Pycharm
在Linux服务器上跑Python项目发现每次从本地上传文件太过麻烦,于是打算在服务器上安装Pycharm直接写Pycharm代码. 去Pycharm的官网下载Linux版本(支持正版于是我下载了 ...
- 软件质量保障初探_Chris
关于软件质量保障的体会 首先,软件质量保障的重要性不言而喻,书中说软件质量体现在以下方面 软件开发过程的可见性 软件开发过程的风险控制 软件内部模块,项目中间阶段的交付质量,项目管理工具的因素 软件开 ...
- Ops:jar包启动关闭脚本
简介 公司开发架构为java语言的rpc dubbo架构,将功能分解为各个模块,模块较多,发布到环境上的应用为编译后的jar包和配置文件,以及启动关闭jar包的shell脚本.之前经常会出现进程启动不 ...
- java架构之路-(微服务专题)初步认识微服务与nacos初步搭建
历史演变: 以前我们都是一个war包,包含了很多很多的代码,反正我开始工作的时候做的就是这样的项目,一个金融系统,代码具体多少行记不清楚了,内部功能超多,但是实际能用到的不多,代码冗余超大,每次部署大 ...
- 安装symfony3.4的坑,也是PHP7.3的经典坑之解决办法
对于刚入手symfony3.4的同学,肯定会发现,安装symfony后部署后看到的往往不是hello world,也不是symfony的欢迎页面,而是给你一个下马威,唉,给你来个bug开开胃. 当然这 ...
- c#设计模式读书博客
第一次在博客园撸博客,也是为了鞭策自己去学习进步,过年之后买了一本<C#设计模式>这是我一直很想去学习的一本书.然后用博客记录我的学习历程,并且分享给需要的人.这本书记录的设计模式有23种 ...
- js + php服务器推送see(自定义推送时间)
//javascript code var source = new EventSource("./main.php"); source.onmessage=function(ev ...