python爬虫——scrapy的使用
本文中的知识点:
- 安装scrapy
- scrapy的基础教程
- scrapy使用代理
安装scrapy
由于小哥的系统是win7,所以以下的演示是基于windows系统。linux系统的话,其实命令都一样的,没啥差,windows与linux都可以用。
pip install scrapy
安装好后,先看下scrapy是否安装上了,确认下,我的是Scrapy 1.8.0
scrapy version
好了,安装很简单。用scrapy创建个新项目吧。命令行下输入,这里注意,命令会在当前目录下创建ts项目。
创建新项目
# 新建一个名为ts的scrapy的项目
scrapy startproject ts
我是在桌面下创建的ts目录,创建成功后给的提示截图如下。

分析目录文件
让我们去目录下看看都有些什么,有个scrapy.cfg配置文件,ts目录。
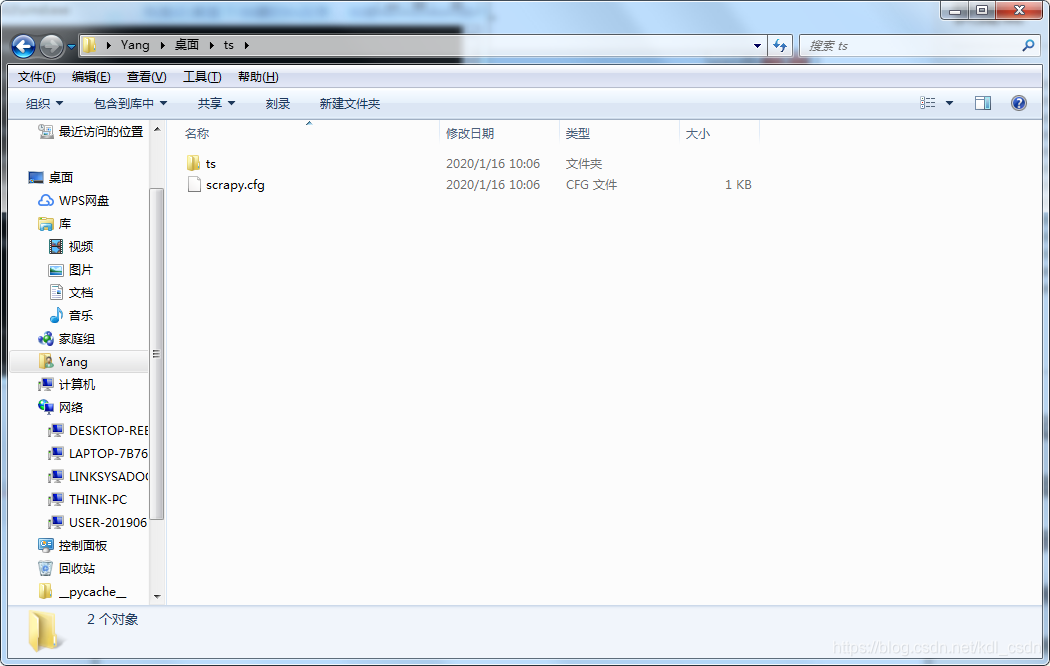
在进入ts目录,看下有些什么。嗯~~~ 主菜来了,这里就是我们要写的内容了。
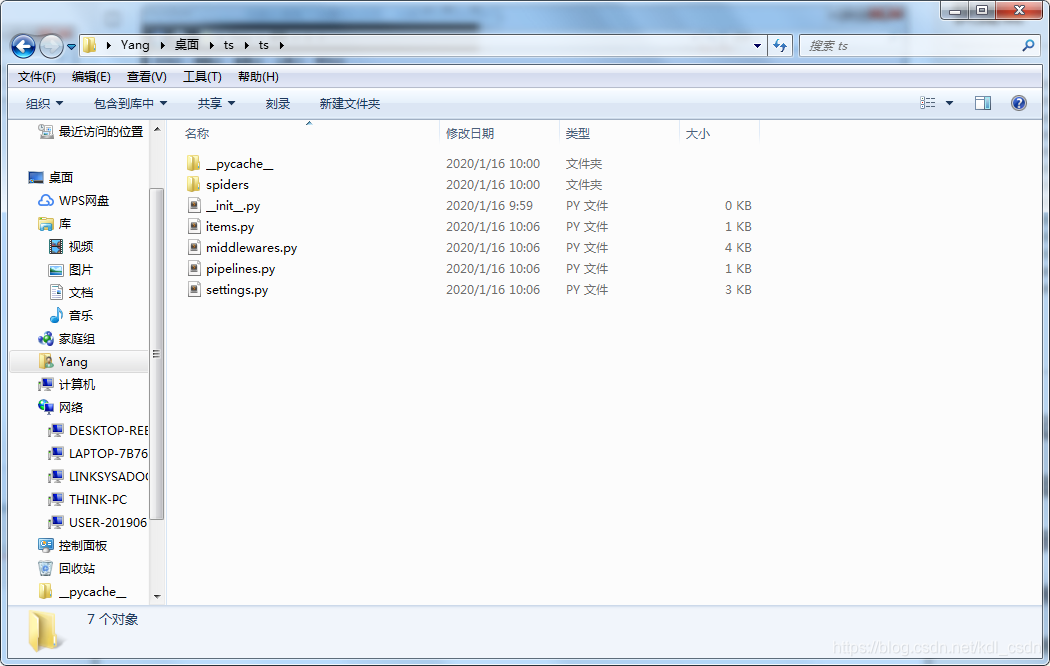
- spiders目录——爬虫代码放这里
- items.py ——要抓取的字段
- middleware——中间件
- pipelines——管道文件
- settings——设置文件
先不用管这么细,我们先跑起来。
代码样例
抓个百度首页试试吧。
进入spiders目录里,创建个baidu的爬虫,并且限制抓取域名的范围。注意要在spiders的目录下输入以下命令
scrapy genspider baidu "baidu.com"
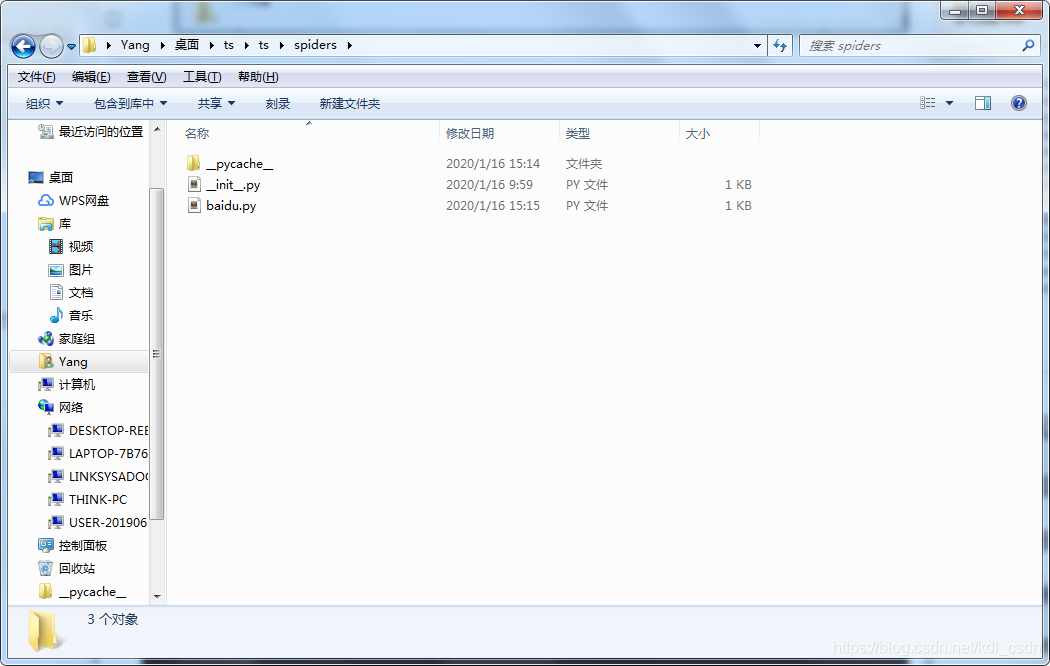
看到命令已经帮我们自动创建了爬虫代码,打开文件看下。
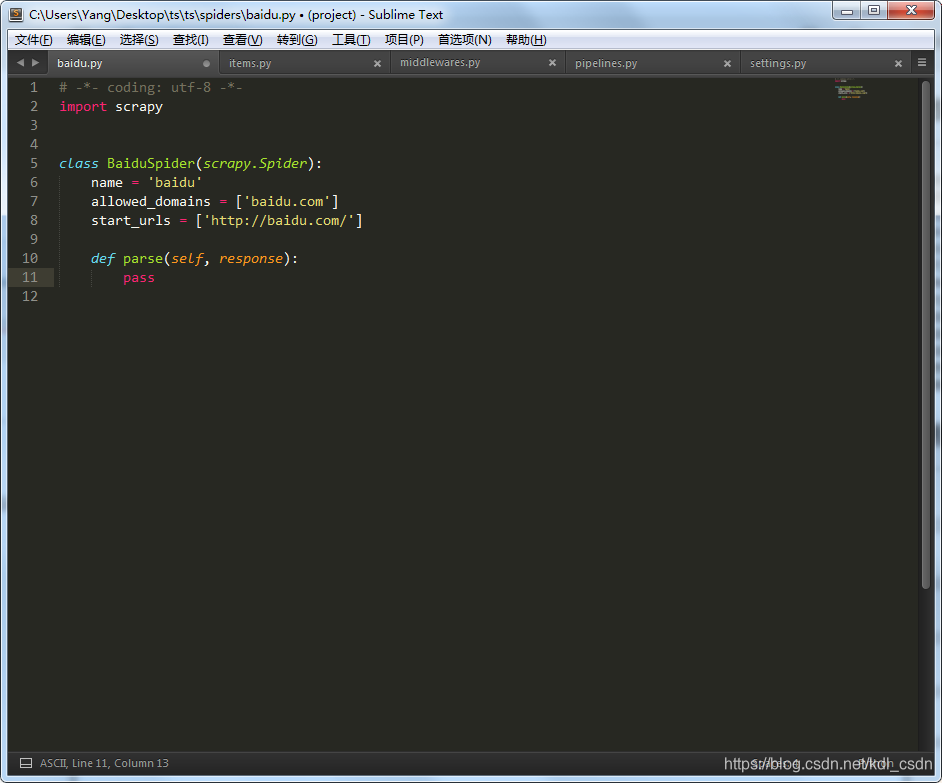
看下这里的代码,先导入scrapy,定义了一个BaiduSpider类,必须要继承scrapy.Spider。这里注意,里面有3个必须的属性(name,allowed_domains,start_urls)。
- name——爬虫的名字,运行爬虫的时候就看这个参数。
- allowed_domains——抓取的域名限制,这是我们刚才在命令行输入的。PS:抓百度,当然限制在百度内了,别抓到淘宝上去了,先不跨界
- start_urls——要抓取的url列表,类型list
- parse函数——抓取后的动作,可以自己定义
好的,既然都OK了,那我们去运行下,看看会发生什么。
命令行下输入,注意这里的baidu就是爬虫的name属性。
scrapy crawl baidu
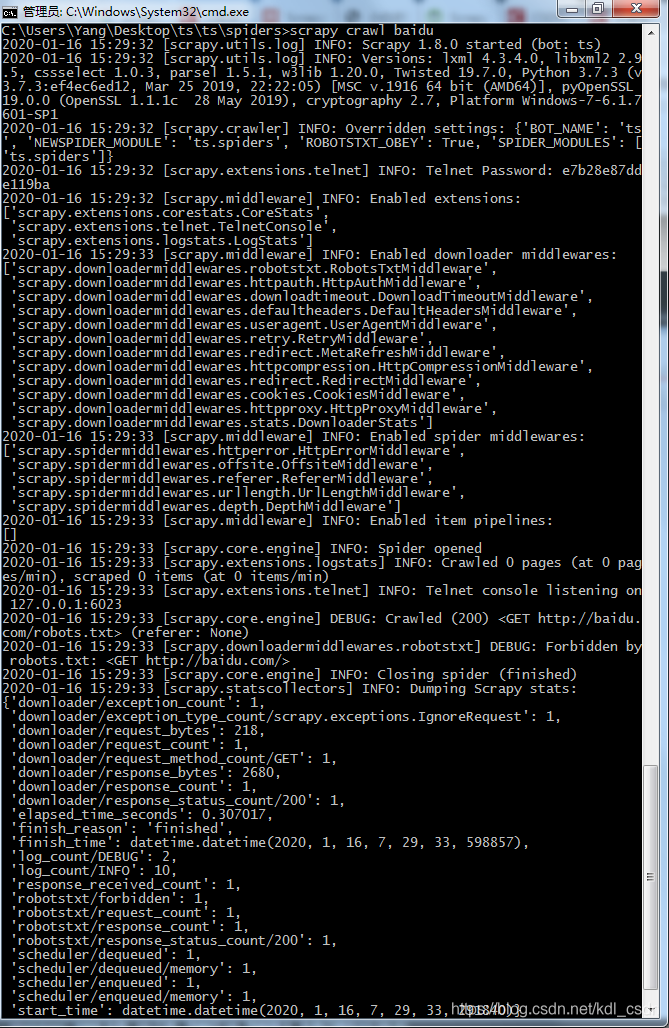
嘎嘎嘎,,,一大堆信息,看的是不是有点懵,说实话,我也是。这是正常信息,已经跑起来了。这些参数,大家随意看一看吧,我先不解释了。。。手动滑稽~~~哈哈哈,其实先不用看,一会我们在讲。
代码改造下,按照我们的预期来
还记得刚才的parse函数么,不过命令创建的是啥事都没干。自己定义下,让它做点事,也好知道代码是按照我们的预期去跑的。
# -*- coding: utf-8 -*-
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
# 打印下response返回的状态码
print(response.status)
在来运行下,还记得刚才的运行命令吗?不记得了?。。。行,我在说一遍,
scrapy crawl baidu
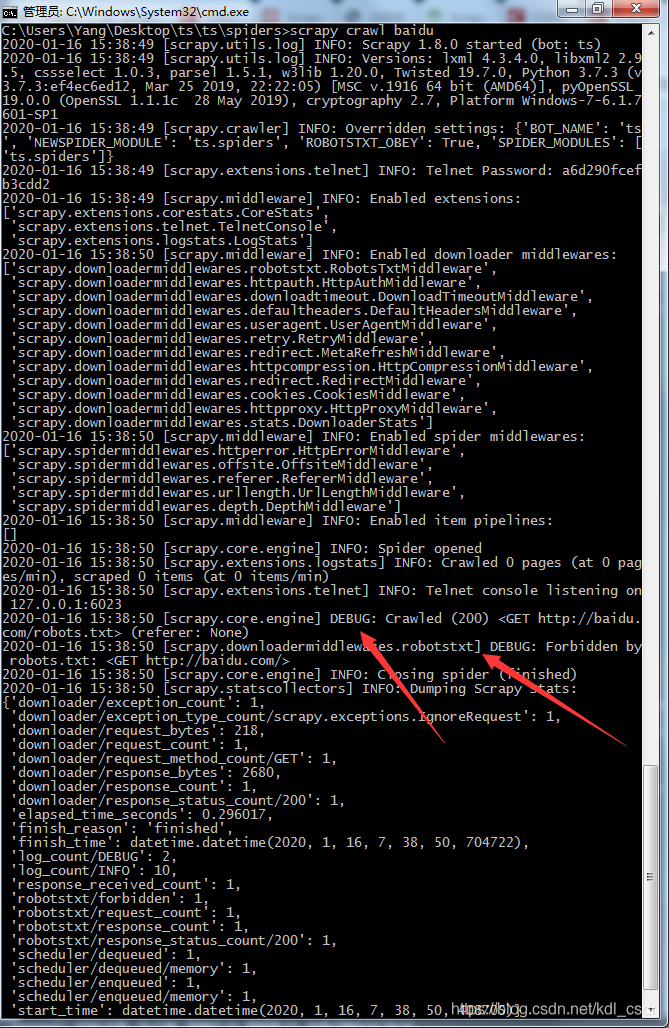
好的,让我们看看会给什么信息。嗯,,,有点问题,没有打印response的状态码,看下日志,这里说的是爬虫碰到了robots.txt,给Forbidden(禁止)了。MD,百度竟然不给我爬,百度自己的spider都在爬其他网站的,,,
这里得解释下为什么禁止了,这其实就是个爬虫的哲学问题了,盗亦有道的道理,相信大家都听说过,爬虫也是,爬亦有道。robots.txt也就是robots协议,这个文件会告诉爬虫,哪些能爬,哪些不能爬,爬虫要遵守这个规则。毕竟是别人的网站嘛,,,
本文以教学为主,旨在教大家使用scrapy框架,合理使用爬虫,遵守互联网规则是每一位互联网人的责任。
好的,问题该怎么解决?其实robots.txt也是可以解决的。这个时候settings.py就派上用场了。到我们之前的目录下,找到settings.py文件。
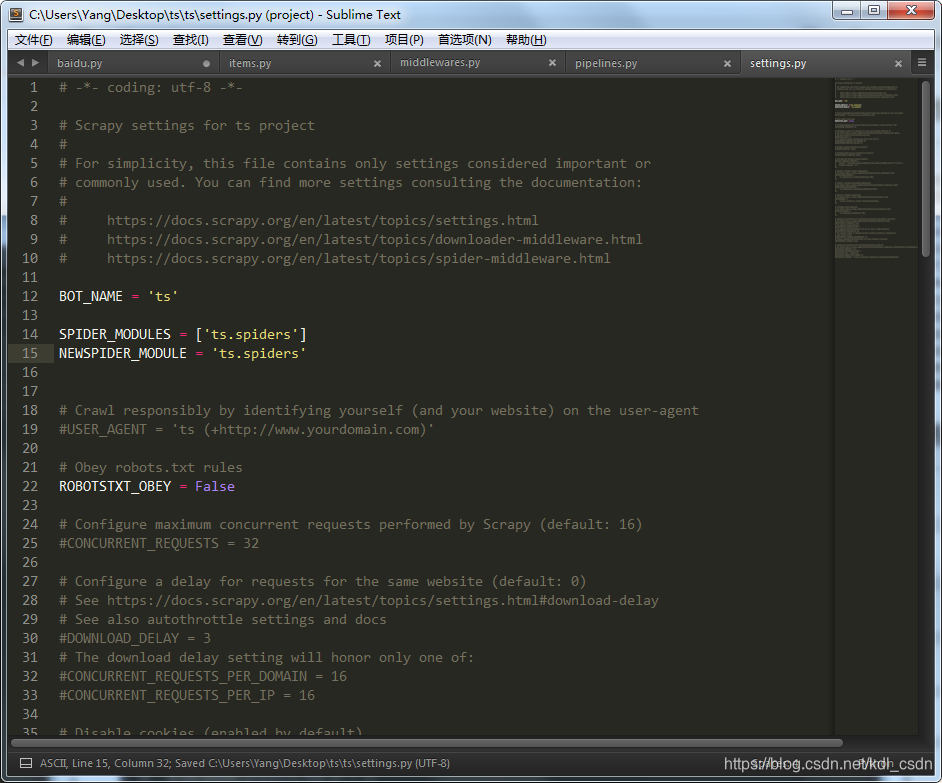
打开看下,注意到ROBOTSTXT_OBEY = True ,这个就是遵守robots协议。
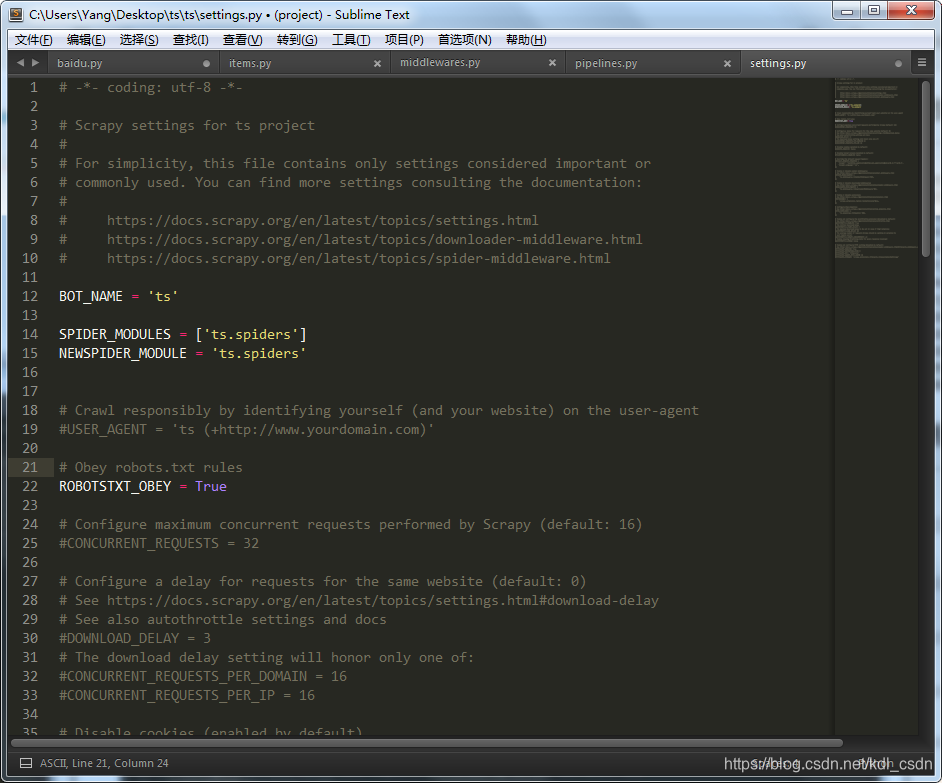
改成False,不遵守robots协议 ~~~嘿嘿嘿,别笑,,,我只是教大家学scrapy框架而已
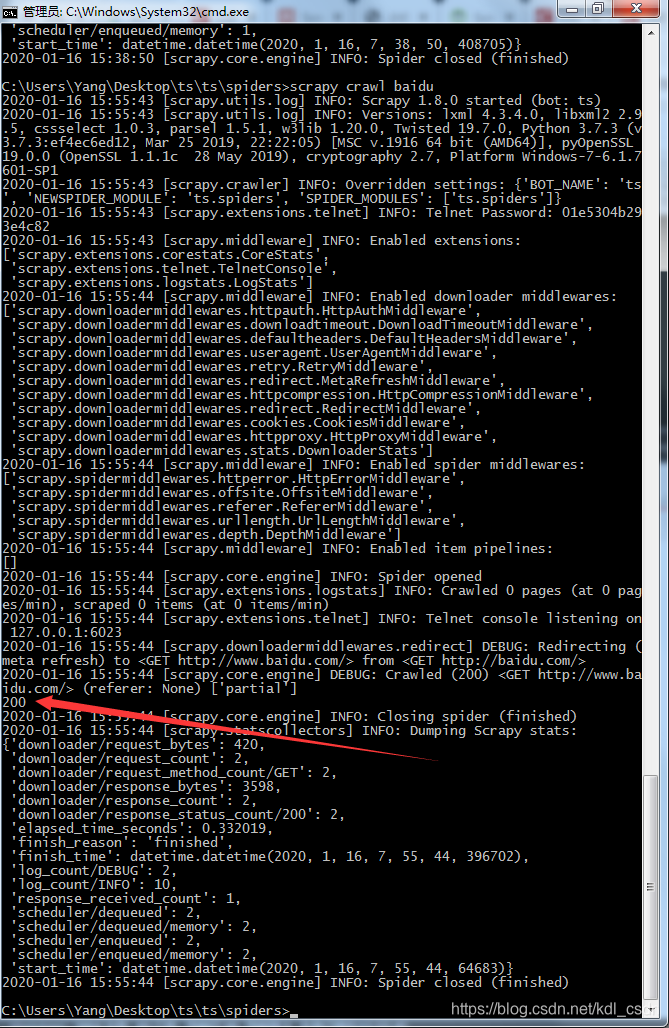
再来运行下。看到这里就已经打印出来了,返回200,成功抓取百度。
再来改造下
改造下parse函数,把抓取的数据保存到一个文件里。毕竟之前的定义的parse动作是打印各种信息,都在看日志,脑袋都大了,这次直接点,看文件好吧。
# -*- coding: utf-8 -*-
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
# 定义文件名 baidu.html
filename = 'baidu.html'
with open(filename, 'wb') as f:
f.write(response.body) #文件写入response的body信息
好的,运行下试试。(PS:命令没忘吧,忘了的往上翻翻),这里注意我是在spiders目录下运行的,baidu.html文件也会保存在当前目录下。
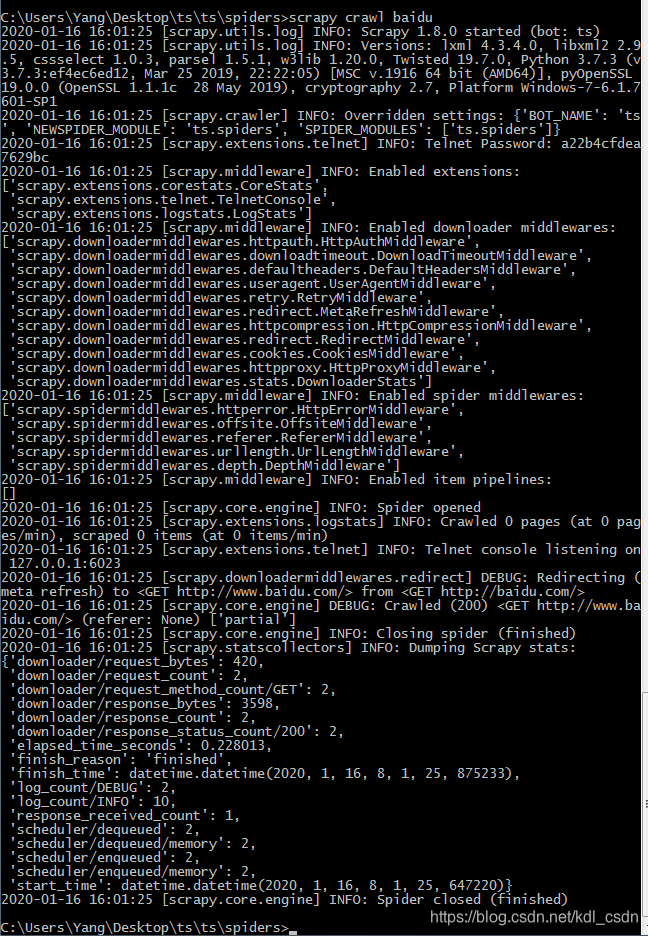
看到了吧,文件出来了,直接双击打开看看,嗯,是百度首页。

使用代理
准备工作,找个可靠的代理IP,剩下的跟着我的步骤走。
修改中间件配置
这里就需要用到中间件了,找到文件middleware.py,打开看看文件。
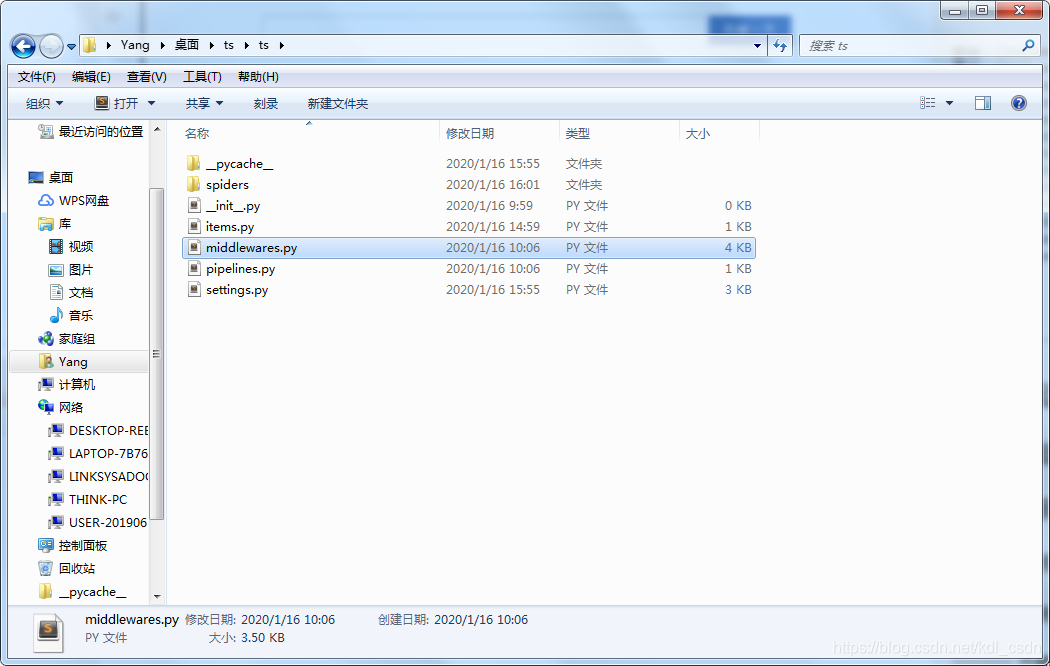
这就是项目的中间件配置了。参数挺多,不过设置代理,我们只需要关注几个参数即可。
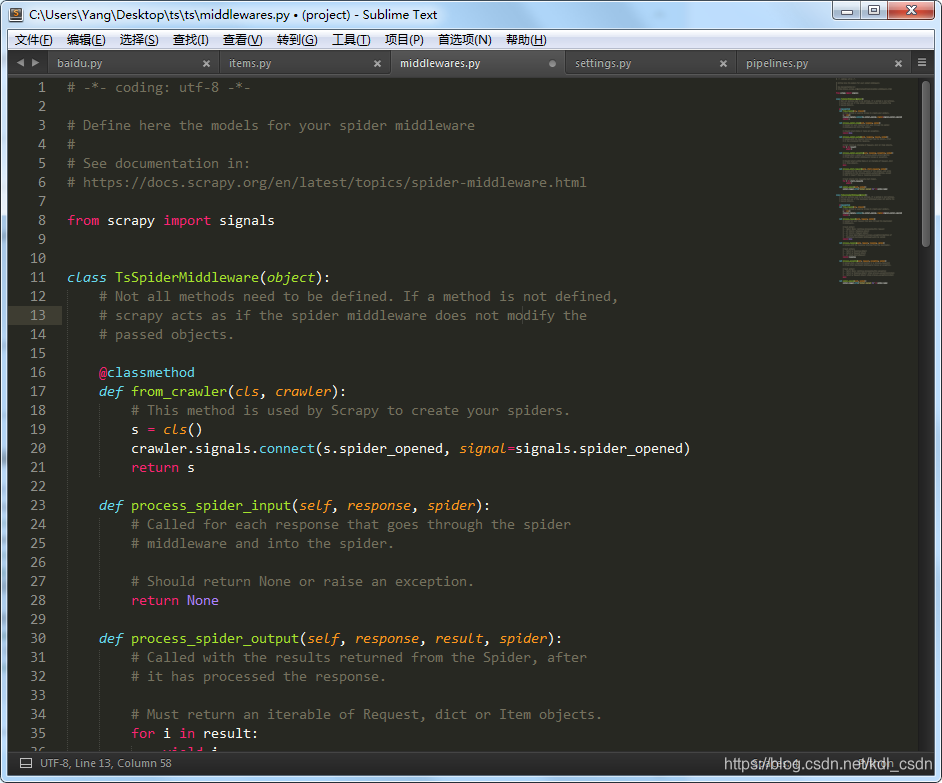
找到TsDownloaderMiddleware,这个类就是我们的项目下载器的中间件,我们的代理配置主要写在process_request函数里。
改成
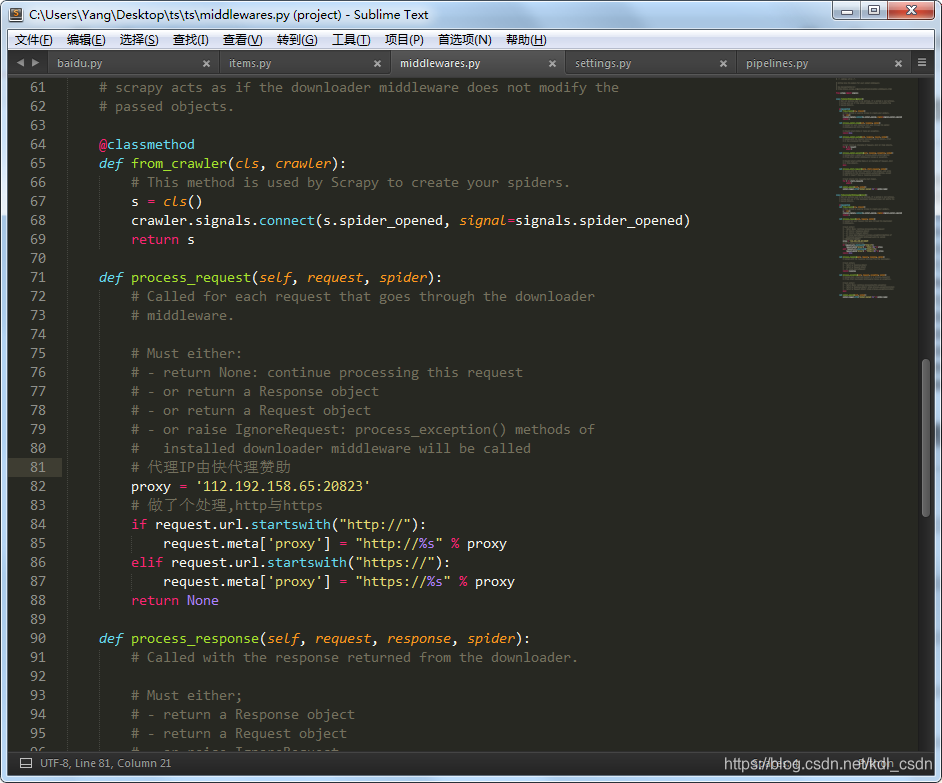
def process_request(self, request, spider):
# Called for each request that goes through the downloader
# middleware.
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
# 代理IP由快代理赞助
proxy = '112.192.158.65:20823'
# 做了个处理,http与https
if request.url.startswith("http://"):
request.meta['proxy'] = "http://%s" % proxy
elif request.url.startswith("https://"):
request.meta['proxy'] = "https://%s" % proxy
return None
修改后如图
settings.py文件也需要修改,需要修改两处:
1、header参数,记住爬虫要模拟用户的真实请求。找到USER_AGENT参数,改成自己浏览器的ua,不知道怎么找ua的同学可以看我前面的一篇教程(点击跳转)中有提到。
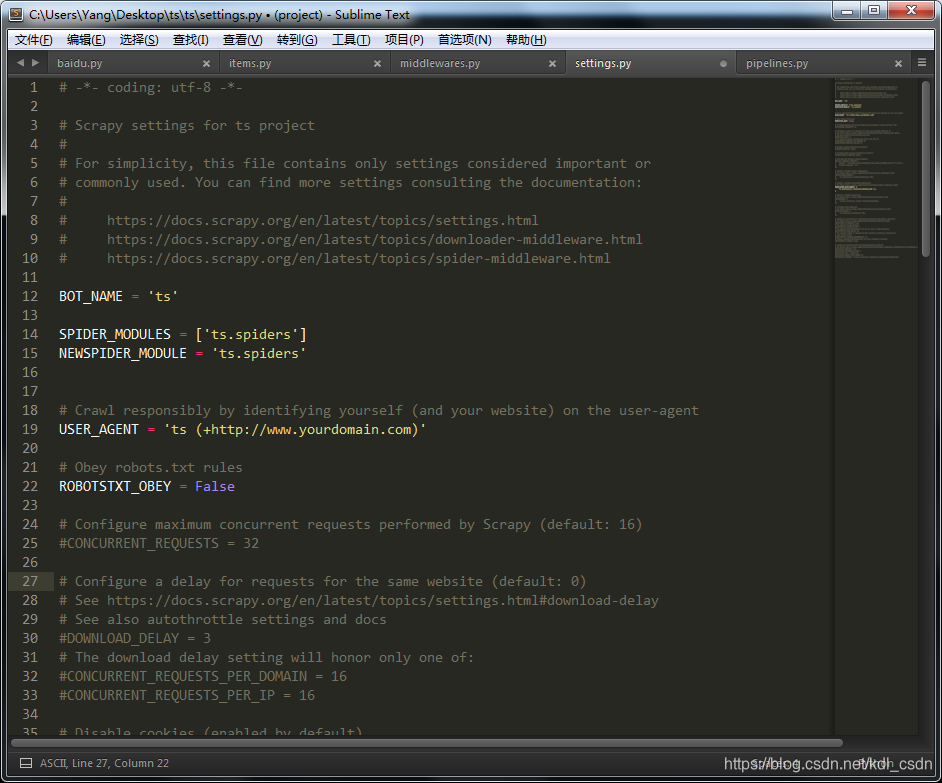
修改后
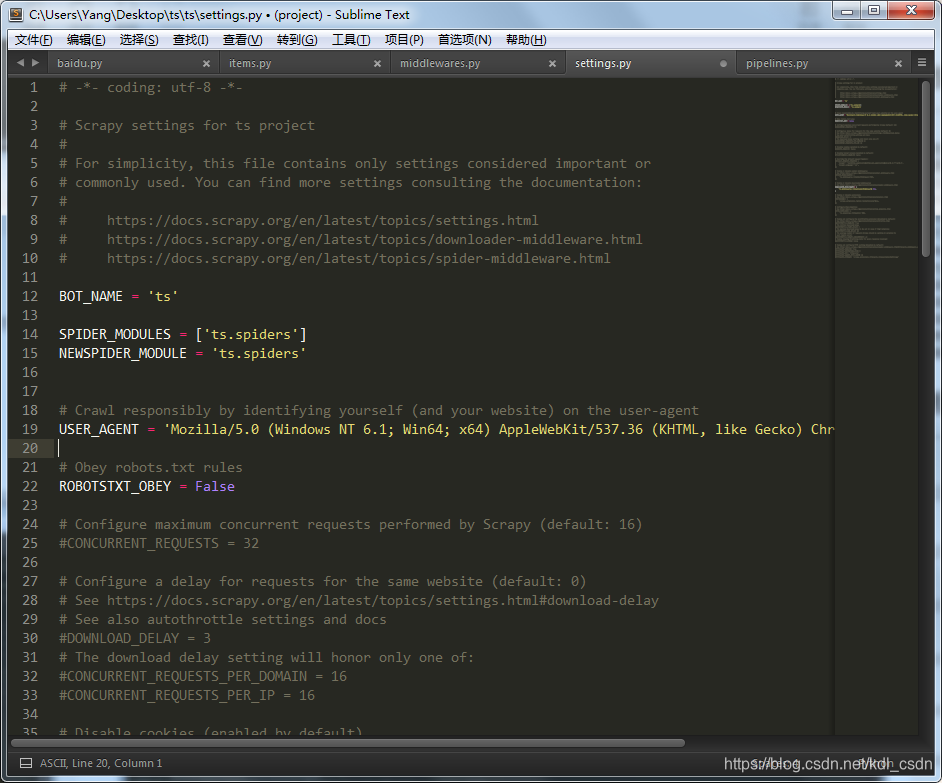
2、找到DOWNLOADER_MIDDLEWARES参数,Ctrl + f搜索,注释掉这个配置保存,启动配置
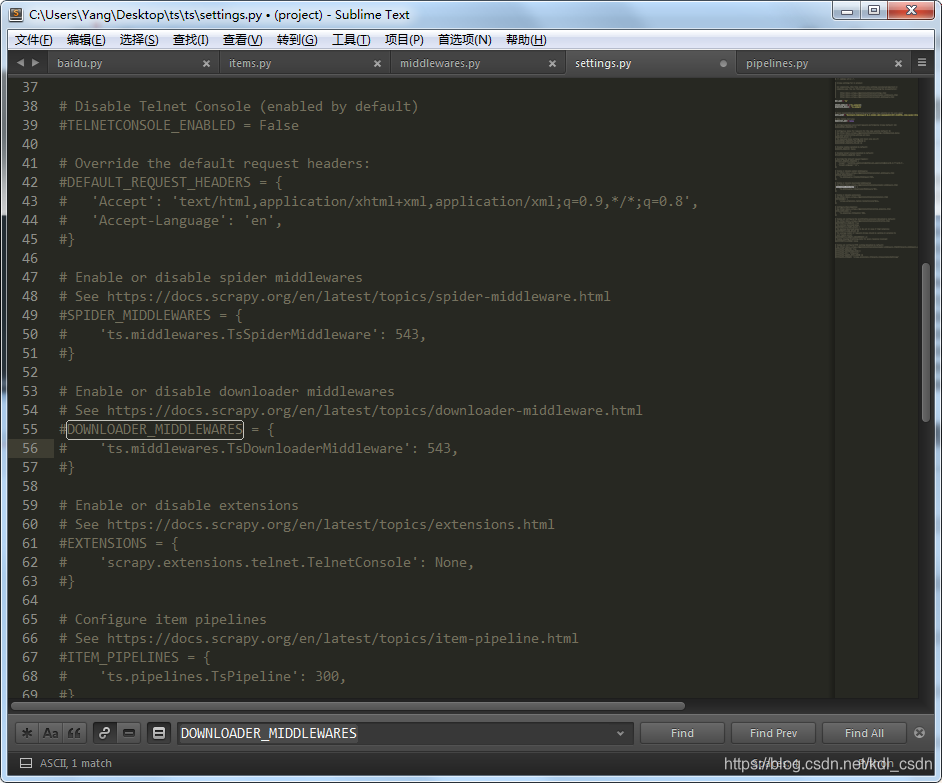
注释后,修改后
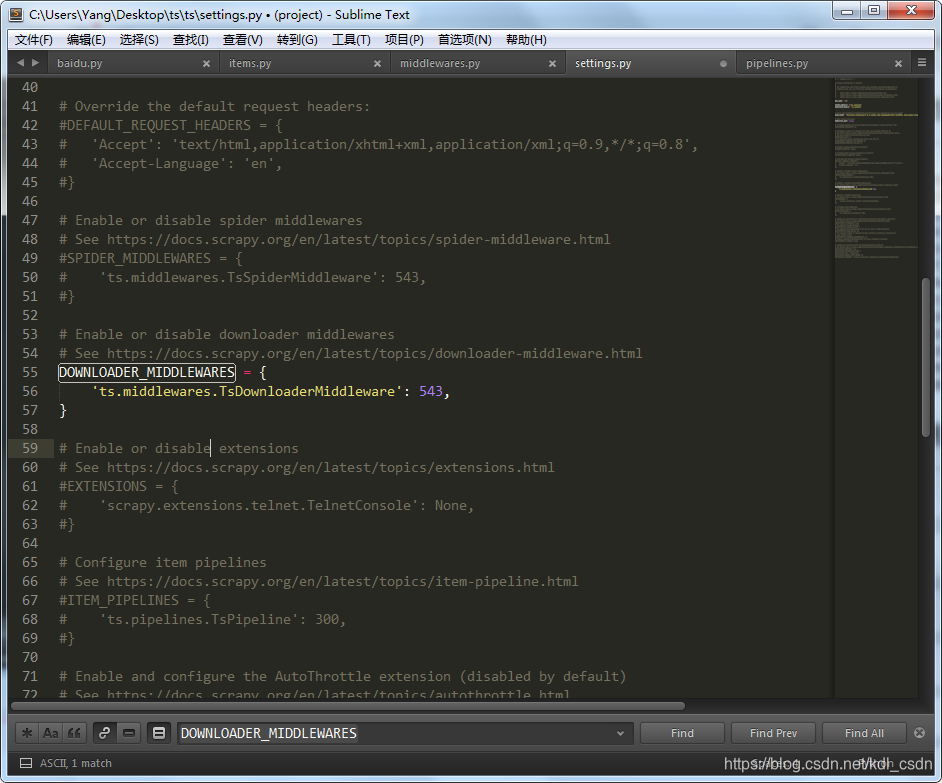
好的,在改下我们的爬虫代码,spiders目录下的baidu.py文件。因为我们用了代理,所以去访问下查IP的网站,看看是否用上代理了。
# -*- coding: utf-8 -*-
import scrapy
class BaiduSpider(scrapy.Spider):
name = 'baidu'
allowed_domains = ['baidu.com']
start_urls = ['https://www.baidu.com/s?ie=UTF-8&wd=ip']
def parse(self, response):
filename = 'baidu.html'
with open(filename, 'wb') as f:
f.write(response.body)

好的,现在在spiders目录下运行下,看看有没有文件出来。
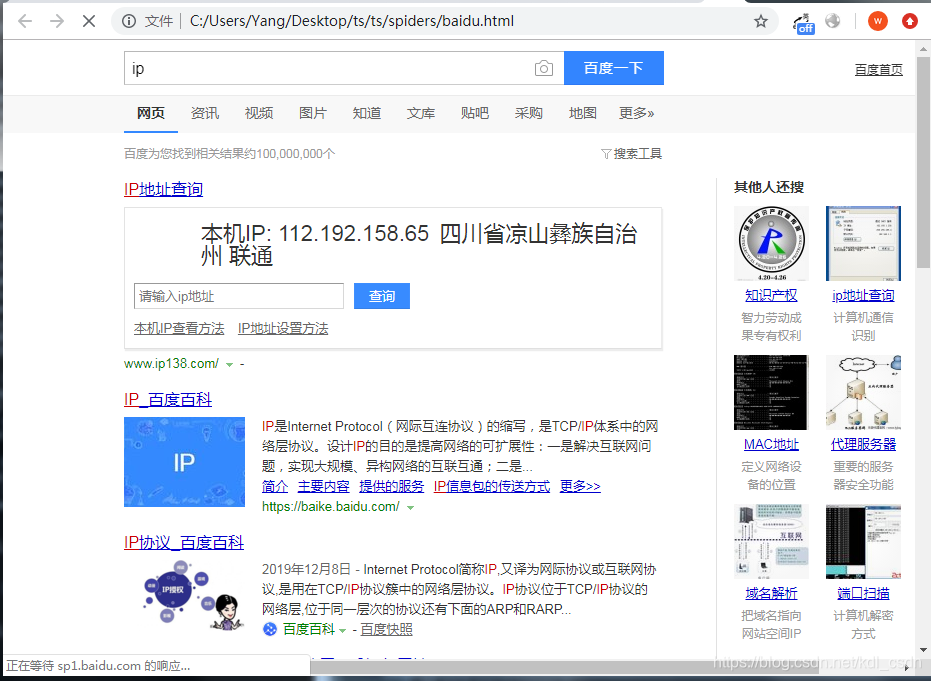
有了,打开文件看下。对吧,这里查到的IP也是我们在代码样例中的IP。说明成功用上代理了。
scrapy使用代理总结下,需要修改及注意那些点。
- 修改中间件文件middleware.py,主要修改downloader中间件的process_request函数。
- 修改配置文件settings.py,设置自己的ua;启用DOWNLOADER_MIDDLEWARES配置;
嗯,主要注意这两个点。
其实还有一种设置代理的方法,我就先不写了,交给大家去研究吧。
进阶学习:
python爬虫——scrapy的使用的更多相关文章
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- Python爬虫Scrapy框架入门(0)
想学习爬虫,又想了解python语言,有个python高手推荐我看看scrapy. scrapy是一个python爬虫框架,据说很灵活,网上介绍该框架的信息很多,此处不再赘述.专心记录我自己遇到的问题 ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- 安装python爬虫scrapy踩过的那些坑和编程外的思考
这些天应朋友的要求抓取某个论坛帖子的信息,网上搜索了一下开源的爬虫资料,看了许多对于开源爬虫的比较发现开源爬虫scrapy比较好用.但是以前一直用的java和php,对python不熟悉,于是花一天时 ...
- Python 爬虫-Scrapy爬虫框架
2017-07-29 17:50:29 Scrapy是一个快速功能强大的网络爬虫框架. Scrapy不是一个函数功能库,而是一个爬虫框架.爬虫框架是实现爬虫功能的一个软件结构和功能组件集合.爬虫框架是 ...
- python爬虫scrapy学习之篇二
继上篇<python之urllib2简单解析HTML页面>之后学习使用Python比较有名的爬虫scrapy.网上搜到两篇相应的文档,一篇是较早版本的中文文档Scrapy 0.24 文档, ...
- Python爬虫Scrapy(二)_入门案例
本章将从案例开始介绍python scrapy框架,更多内容请参考:python学习指南 入门案例 学习目标 创建一个Scrapy项目 定义提取的结构化数据(Item) 编写爬取网站的Spider并提 ...
- python爬虫----scrapy框架简介和基础应用
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以 ...
随机推荐
- 2018-7-31-C#-判断两条直线距离
title author date CreateTime categories C# 判断两条直线距离 lindexi 2018-07-31 14:38:13 +0800 2018-05-08 10: ...
- WPF 托盘显示
本文告诉大家如何在 WPF 实现在托盘显示,同时托盘可以右击打开菜单,双击执行指定的代码 NotifyIcon WPF 通过 Nuget 安装 Hardcodet.NotifyIcon.Wpf 可以快 ...
- 2019-5-21-win10-uwp-商业游戏-1.1.5
title author date CreateTime categories win10 uwp 商业游戏 1.1.5 lindexi 2019-05-21 11:38:20 +0800 2018- ...
- get_free_page 和其友
如果一个模块需要分配大块的内存, 它常常最好是使用一个面向页的技术. 请求整个页也 有其他的优点, 这个在 15 章介绍. 为分配页, 下列函数可用: get_zeroed_page(unsigned ...
- Python的优缺点、以及解释器种类
优点 Python起始定位“优雅”.“明确”.“简洁”,工具型语言,上手快,实用性强. 开发效率高,支持库强大,很多功能都有与之对应的最优模块支持. 高级语言,编程时无需考虑内存等底层具体实现. 可移 ...
- Linux 内核热插拔事件产生
一个热插拔事件是一个从内核到用户空间的通知, 在系统配置中有事情已经改变. 无论何 时一个 kobject 被创建或销毁就产生它们. 这样事件被产生, 例如, 当一个数字摄像头 使用一个 USB 线缆 ...
- Priest John's Busiest Day (2-sat)
题面 John is the only priest in his town. September 1st is the John's busiest day in a year because th ...
- Java中的选择结构
1.if选择结构 if选择结构是根据条件判断之后再做处理的一种语法结构 语法: if(条件){ 代码块 //条件成立之后要执行的代码,可以是一条语句,也可以是一组语句 } if后小括号里的条件是一个表 ...
- Java第一次创建对象速度比之后慢的原因
类的对象在第一次创建的时候,Java虚拟机(JVM)首先检查是否所要加载的类对应的Class对象是否已经加载.如果没有加载,JVM就会根据类名查找.class文件,并将其Class对象载入.一般某个类 ...
- $Noip2016/Luogu2822$ 组合数问题
$Luogu$ 看这题题解的时候看到一个好可爱的表情(●'◡'●)ノ♥ $Sol$ 首先注意到这题的模数是$k$.然而$k$并不一定是质数,所以不能用$C_n^m=\frac{n!}{m!(n-m)! ...