【solr】Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群
Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。SolrCloud 是基于Solr和Zookeeper的分布式搜索方案,具体拥有以下几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
SolrCloud在搭建时,通过先搭建完一个Solr实例后,可以很容易地使用Zookeeper来做一个集群。我演示的安装步骤基于一台机器,所以采用伪集群的方式进行安装,如果是真正的生成环境,将伪集群的ip改下就可以了,步骤是一样的。
安装准备
- JDK1.7以上
- Solr5.5.4部署包(solr-5.5.4.tgz 大约130M)
- Tomcat8部署包 (apache-tomcat-8.5.16.tar.gz)
- zookeeper-3.4.6部署包(zookeeper-3.4.6.tar.gz)
Solr5.5.4单机部署与Tomcat8
你可以在Solr5.5.4单机部署找到如何将Solr5.5.4部署在Tomcat8环境下.
Solr5.5.4+Zookeeper3.4.6+Tomcat8集群部署
如果已经成功部署了一个Solr,那么接下来的工作也不会太难。下面的集群部署基于已经成功部署过单个Solr。如果你还没有部署过Solr或者还没有部署过单机版的,讲义看一下Solr5.5.4单机部署里面第二部分,通过tomcat部署Solr,然后再来部署集群。
具体zookeeper集群部署我在这里就不讲啦,如果不会部署zookeeper集群的可以看一下看一下zookeeper集群部署。本次部署详情信息如下:
| 机器 | 192.168.219.11(node11),192.168.219.12(node12),192.168.219.13(node13),192.168.219.14(node14) |
| 系统 | Red Hat Enterprise Linux Server release 6.5 (Santiago) |
| 系统内核 | 2.6.32-358.el6.x86_64 |
| solr版本 | Solr-5.5.4 |
| zookeeper版本 | 3.4.6 |
| zookeeper地址(ip:port) | node11:2282,node12:2282,node13:2282 |
| tomcat版本 | 8.5.16 |
| solr+tomcat地址 | /home/anu/tomcat8 |
| solr_home(core)地址 | /home/anu/tomcat8/solr_home, node11:8888(leader),node12:8888(follower),node13:8888(follower),node14:8888(follower) |
1、我早之前已经在一台机器上那装过单机的Solr(鄙人是在node11机器上安装的,通过tomcat+Solr实现,放在tomcat8中),所以直接来改动它里面的配置就可以啦。
2、为了保证端口不冲突,我们来改一下tomcat端口还有Solr端口

修改./tomcat8/conf/server.xml,将下面几个地方的端口尽量改动一下不要和别的地方冲突

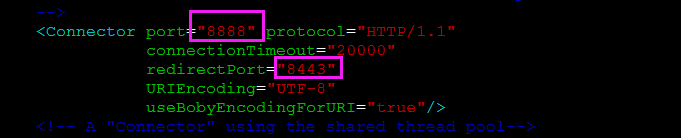

这些地方本人已经改过啦,注意上面那个8888端口是tomcat发布端口,这个后面要用到,需要设置成Solr端口
3、配置tomcat8的启动项,配置zookeeper和各个tomcat进行关联:首先确定leader节点,本人使用node11作为leader,其余的作为follower,现在先配置leader的tomcat目录下(我的是tomcat8)的bin/catalina.sh中的最上面添加一行

| JAVA_OPTS="-Djetty.port= -Dbootstrap_confdir=/home/anu/tomcat8/solr_home/ustcinfo/conf -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=" |
8888:必须要和我们上面配置的tomcat端口一致,
/home/anu/tomcat8/solr_home/ustcinfo/conf:这个是我的Solr_home 的路径,这个下面我们单机安装的时候已经说了这个的由来,下面马上我再说一下
solr_home:是我的solr_home名字,可以随便取,但是尽量和你的solr_home文件名一样,便于查看
node11:2282,node12:2282,node13:2282:这是我的zookeeper集群,前面已经安装并且已经启动
2:表示有两个shard节点
下面大致解释一下这些参数含义:
- -Djetty.port Solr的发布端口,需要和tomcat端口一致,使用jetty.port是响应Solr内部jetty关联
- -Dbootstrap_confdir ZooKeeper需要准备一份集群配置的副本,这个参数是告诉SolrCloud这些配置是放在哪里,同时作为整个集群共用的配置文件。
- -Dcollection.configName 指定你的配置文件上传到zookeeper后的名字,建议和你所上传的核心名字一致,这样容易识别。
- -DzkRun 在Solr中启动一个内嵌的zooKeeper服务器,该服务会管理集群的相关配置。
- -DzkHost 跟上面参数的含义一样,允许配置一个ip和端口来指定用哪个Zookeeper服务器进行协调。
- -DnumShards=2 配置需要把你的数据分开到多少个shard中
- -Dbootstrap_conf=true 将会上传solr/home里面的所有数据到zookeeper的home/data目录,也就是所有的core将被集群管理,本次我未使用这个参数。
这里面配好之后,我们再说说我配置的Solr_home路径由来。
首先,我们在单机中已经将./solr-5.5.4/server/solr 下面所有的东西都拷贝到./tomcat8/solr_home目录下。我们进入到./tomcat/sole_home 目录下

其次,在这个路径下新建一个作为core使用的文件夹,名字可以随意起,鄙人创建名字为ustcinfo的文件夹
然后将./tomcat8/solr_home/configsets/basic_configs 目录下的所有文件都拷贝到我们刚刚新建的ustcinfo 下面
mkdir ustcinfo
cp -r configsets/basic_configs/* ustcinfo/
cd ustcinfo/
ls
cd conf
pwd



在这就可以看到我们配置的Solr_home地址,用于后面同一创建Solr集合识别core使用。
特别需要注意:上面添加JAVA_OPTS时针对leader节点的,其余三台机器的JAVA_OPTS如下:
JAVA_OPTS="-Djetty.port=8888 -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=2"
这个配置后面会提到
4、修改solr.xml的jetty.port参数值为tomcat的端口
打开./tomcat8/solr_home/solr.xml 文件,修改jetty.port参数值为tomcat的端口(即我们前面配置的)
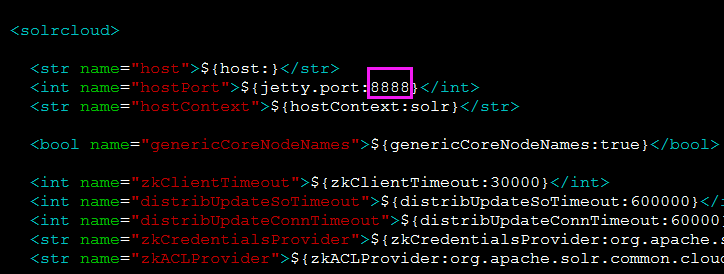
5、将配置好的tomcat+solr拷贝到其他三台机器node12、node13、node14,
scp -r tomcat8 anu@node12:/home/anu/
scp -r tomcat8 anu@node13:/home/anu/
scp -r tomcat8 anu@node14:/home/anu/
6、修改其他三台follower的tomcat8启动项,
分别进入node12、node13、node14机器,通过vim tomcat8/bin/catalina.sh 打开catalina.sh文件,将tomcat启动项的 -Dbootstrap_confdir=/home/anu/tomcat8/solr_home/ustcinfo/conf 删掉,最终JAVA_OPTS参数如下
JAVA_OPTS="-Djetty.port=8888 -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=2"
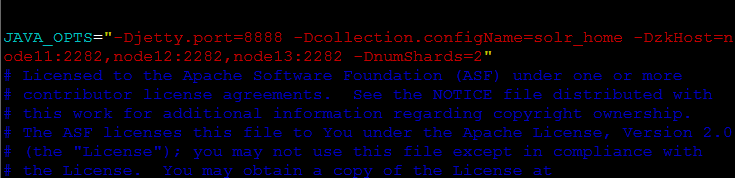
7、分别启动4台机器的tomcat8+Solr
使用命令tomcat8/bin/catalina.sh start 或者tomcat8/bin/startup.sh 启动四台tomcat8
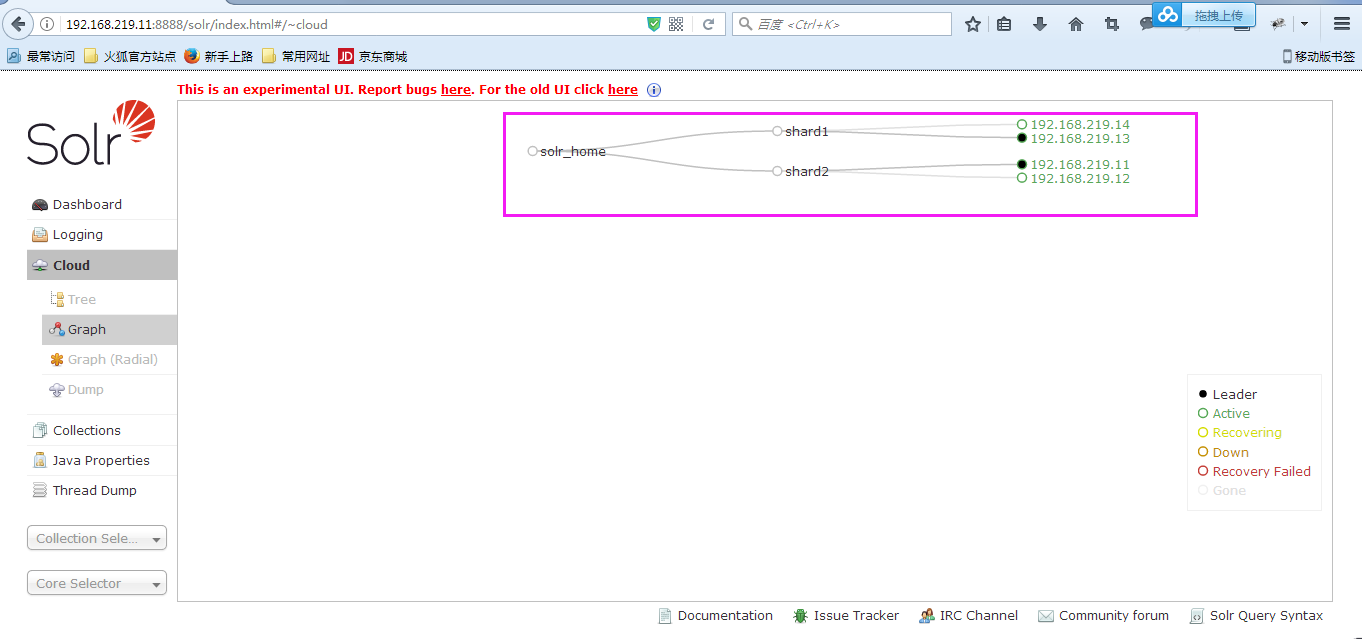
8、通过访问页面查看Sole配置
在浏览器中打开http://192.168.219.11:8888/solr/index.html#/,进入后点击左边导航栏的cloud查看
【solr】Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群的更多相关文章
- Solr 10 - SolrCloud集群模式简介 + 组成结构的说明
目录 1 什么是SolrCloud 2 SolrCloud的结构 2.1 物理结构 2.2 逻辑结构 2.2.1 Collection(集合) 2.2.2 Core(内核) 2.2.3 Shard(分 ...
- Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境
Hadoop2.7.3+HBase1.2.5+ZooKeeper3.4.6搭建分布式集群环境 一.环境说明 个人理解:zookeeper可以独立搭建集群,hbase本身不能独立搭建集群需要和hadoo ...
- ubuntu12.04+kafka2.9.2+zookeeper3.4.5的伪分布式集群安装和demo(java api)测试
博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1&do=blog&id=547 转载声明:可以转载, 但必须以超链 ...
- Zookeeper3.4.6部署伪分布集群(Apache)
1.下载Zookeeper http://mirrors.cnnic.cn/apache/zookeeper/zookeeper-3.4.6/ 2.创建/usr/app/zookeeper目录,并切换 ...
- Zookeeper3.4.10 + ActiveMQ-5.15.0 集群搭建
网上的教程真的是凤毛麟角,就不想说啥了,一次一次把我带入坑. 好了关于Zookeeper的搭建已经说好了,本文说说基于Zookeeper的MQ集群. 第一步.将mq安装包上传到CentOS7,并解压 ...
- solr集群搭建,zookeeper集群管理
1. 第一步 把solrhome中的配置文件上传到zookeeper集群.使用zookeeper的客户端上传. 客户端命令位置:/root/solr-4.10.3/example/scripts/cl ...
- Solr 14 - SolrJ操作SolrCloud集群 (Solr的Java API)
目录 1 pom.xml文件的配置 2 SolrJ操作SolrCloud 1 pom.xml文件的配置 项目的pom.xml依赖信息请参照: Solr 09 - SolrJ操作Solr单机服务 (So ...
- solr 主从模式和solrcloud集群模式
主从模式 主节点有单点故障问题:没有主从自动切换,没有failover,主机down掉了的话,整个数据变成只读.并且需要一台机单独做索引,浪费资源,所有数据都需要在这台机器上单独存在一份,索引变化较大 ...
- 基于redis实现tomcat8的tomcat集群的session持久化实现(tomcat-redis-session-manager二次开发)
前言: 本项目是基于jcoleman的tomcat-redis-session-manager二次开发版本 1.修改了小部分实现逻辑 2.去除对juni.jar包的依赖 3.去除无效代码和老版本tom ...
随机推荐
- Codeforces 839D Winter is here
链接:CF839D 题目大意 给定一个数组大小为\(n(1\leq n\leq 200000)\)的数组\(a\),满足\(1\leq a_i \leq 1000000\). 选择其中任意\(len\ ...
- 【JZOJ3301】家族
description 阿狸和桃子养了n 个小阿狸, 小阿狸们每天都在一起玩的很开心. 作为工程师的阿狸在对小阿狸们之间的关系进行研究以后发现了小阿狸的人际关系由某种神奇的相互作用决定, 阿狸称之为& ...
- ThinkPHP 读取数据
在ThinkPHP中读取数据的方式很多,通常分为读取数据.读取数据集和读取字段值. 步进电机和伺服电机 数据查询方法支持的连贯操作方法有: 连贯操作 作用 支持的参数类型 where 用于查询或者更新 ...
- Django之深入了解模板层
目录 模板语法 模板传值 过滤器 标签 自定义过滤器和标签 模板继承 模板导入 模板语法 前端模板的语法只记住两种就行了. {{ xxx }} 变量相关的 { % % } 逻辑相关的 模板传值 我们通 ...
- 使用pageHelper分页查询,报sql语句错误
1.异常详情: 2.异常分析: (1)pageHelper分页大致流程: 配置默认的拦截器:pagehelper.PageInterceptor,对发送的查询语句进行拦截,拦截之后对原有的查询语句进 ...
- sql.xml where ids in的写法
<if test="iSurfaceTypeArray != null"> AND b.i_SurfaceType in <!-- 根据外观检查查询 --> ...
- final关键字与类型转换
一.关于final的重要知识点; 1.final关键字可以用于成员变量.本地变量.方法以及类. 2. final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误. 3. 你不能够 ...
- Deepin折腾手记之安装常用软件
1. 创建快捷方式 在创建快捷图标的文件/usr/share/applications/xx.desktop 编辑内容 [Desktop Entry] Name=VNote X-Deepin-Vend ...
- 操作系统-CPU调度
概念 控制.协调多个进程对CPU的竞争 即按一定的调度算法从就绪队列中选择一个进程,把CPU的使用权交给被选中的进程 场景 N个进程就绪,等待上M(M>=1)个CPU运行,需要决策哪个进程分配给 ...
- java最常用的几种加密算法
1. BASE64 Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,大家可以查看RFC2045-RFC2049,上面有MIME的详细规范.Base64编码可用于在HTTP环境下传递 ...