python(八)内置模块logging/os/time/sys/json/pickle
模块
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。点这里查看Python的所有内置函数。
你也许还想到,如果不同的人编写的模块名相同怎么办?为了避免模块名冲突,Python又引入了按目录来组织模块的方法,称为包(Package)。
举个例子,一个abc.py的文件就是一个名字叫abc的模块,一个xyz.py的文件就是一个名字叫xyz的模块。
现在,假设我们的abc和xyz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突。方法是选择一个顶层包名,比如test,按照如下目录存放:
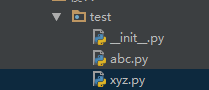
引入了包以后,只要顶层的包名不与别人冲突,那所有模块都不会与别人冲突。现在,abc.py模块的名字就变成了test.abc,类似的,xyz.py的模块名变成了test.xyz。
请注意,每一个包目录下面都会有一个__init__.py的文件,这个文件是必须存在的,否则,Python就把这个目录当成普通目录,而不是一个包。__init__.py可以是空文件,也可以有Python代码,因为__init__.py本身就是一个模块,而它的模块名就是test。
模块分为三种:
自定义模块
第三方模块
内置模块
自定义模块
1、定义模块
a.同一目录下定义多个模块
b.同一目录不同子目录下定义模块
c.自定义多个模块
2、导入模块
|
1
2
3
4
|
import module #调用模块,一般调用内置模块或第三方模块from module import xxx #导入某个模块的某个方法from module import xxx as rename #导入模块并定义模块别名from module import * #导入模块的所有方法 |
导入模块其实就是告诉python解释器去解释那个py文件。
导入模块时,如果想直接通过import module的方式导入,根据sys.path路径作为基准来进行,也就是说你所导入的模块必须在sys.path路径下,如果没有,则import module方式不能成功导入。
|
1
2
3
4
5
6
7
8
9
10
|
import sysprint(sys.path)结果:['J:\\python_program\\S13\\day06\\模块\\test', 'J:\\python_program\\S13', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\python35.zip', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\DLLs', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\lib', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python35\\lib\\site-packages'] |
如果sys.path中没有需要的路径,可以通过sys.path.append('路径')添加。
将当前程序所在路径加入到sys.path中:
|
1
2
3
4
5
|
import sysimport osproject_path = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))sys.path.append(project_path)print(sys.path) |
在Python中,安装第三方模块,是通过包管理工具pip完成的。
如果你正在使用Mac或Linux,安装pip本身这个步骤就可以跳过了。
如果你正在使用Windows,确保安装python时勾选了pip和Add python.exe to Path。
在命令提示符窗口下尝试运行pip,如果Windows提示未找到命令,可以重新运行安装程序添加pip。
安装模块命令:
|
1
2
3
4
5
6
7
8
9
|
pip install requestsimport requests 加载requests、json模块import jsonreponse.encoding='utf-8'dic = json.loads(reponse.text)print(dic,type(dic)) |
内置模块
1、sys模块--用于提供python解释器相关操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
sys.argv #命令行参数List,第一个元素是程序本身路径sys.exit(n) #退出程序,正常退成时exit(0)sys.maxsize #最大的Int值sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量sys.platfrom #操作系统平台名称sys.stdin #输入相关sys.stdout #输出相关sys.stderror #错误相关的 import syssys.stdout.write('Hello World!') #屏幕输出hello world import sysprint('Please enter your name:')name = sys.stdin.readline()[:-1] #获取命令行输入print('Hi,%s'%name) |
进度百分比:
|
1
2
3
4
5
6
7
8
9
10
11
|
import sys,timedef view_bar(num,total): rate = float(num) / float(total) rate_num = int(rate * 100) r = '\r%d%%'%(rate_num) sys.stdout.write(r) #屏幕输出百分比 sys.stdout.flush() #屏幕强制刷新if __name__ == '__main__': for i in range(0,100): time.sleep(0.1) view_bar(i,100) |
2、os模块---用于提供系统级别的操作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cdos.curdir 返回当前目录: ('.')os.pardir 获取当前目录的父目录字符串名:('..')os.makedirs('dir1/dir2') 可生成多层递归目录os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirnameos.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirnameos.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印os.remove() 删除一个文件os.rename("oldname","new") 重命名文件/目录os.stat('path/filename') 获取文件/目录信息os.sep 操作系统特定的路径分隔符,win下为"\\",Linux下为"/"os.linesep 当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"os.pathsep 用于分割文件路径的字符串os.name 字符串指示当前使用平台。win->'nt'; Linux->'posix'os.system("bash command") 运行shell命令,直接显示os.environ 获取系统环境变量os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素os.path.exists(path) 如果path存在,返回True;如果path不存在,返回Falseos.path.isabs(path) 如果path是绝对路径,返回Trueos.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回Falseos.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回Falseos.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 |
3、json、pickle-----python中用于序列化的两个模块
json:用于字符串和python基本数据类型间进行转换
pickle:用于python特有类型和python基本数据类型之间进行转换
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
import jsondic = {'k1':999}result = json.dumps(dic) #将字典转化为字符串print(result,type(result))#执行结果:{"k1": 999} <class 'str'>str = '{"k1":"biubiubiu"}' #注意:反序列化时,内部必须用双引号result = json.loads(str) #将字符串转化为字典print(result,type(result))#执行结果:{'k1': 'biubiubiu'} <class 'dict'>import jsonli = [11,22,33,44]json.dump(li,open('db','w')) #将列表持久化到文件中li1 = json.load(open('db','r')) #将列表从文件中读取出来print(li1,type(li1))#执行结果:[11, 22, 33, 44] <class 'list'>import pickleli = [11,22,33,44]a = pickle.dumps(li) #dumps/loads都是在内存中进行的print(a)#执行结果: b'\x80\x03]q\x00(K\x0bK\x16K!K,e.' |
通过以上例子,不难看出pickle转换都是将python的基本数据类型转换成2进制格式,那么我们存文件时,也需要以二进制的方式存
|
1
2
3
4
5
6
|
li = [11,22,33,44]a = pickle.dump(li,open('db','wb'))result=pickle.load(open('db','rb'))print(result)#执行结果:[11, 22, 33, 44] |
4、time模块
时间相关的操作,时间有三种表示方式:
时间戳 1970年1月1日之后的秒,即:time.time()
格式化的字符串 2014-11-11 11:11, 即:time.strftime('%Y-%m-%d')
结构化时间 元组包含了:年、日、星期等... time.struct_time 即:time.localtime()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
import time print(time.time()) #返回从1970年到现在的时间戳 1465447994.0811183print(time.ctime()) #输出当前系统时间 Thu Jun 9 12:53:48 2016print(time.ctime(time.time()-86400)) #将时间戳转换为字符串格式 Wed Jun 8 12:56:53 2016print(time.gmtime(time.time()-86400)) #将时间戳UTC转换成struct_time格式print(time.localtime(time.time()-86400)) #将本地时间的时间戳转换成struct_time格式: print(time.mktime(time.localtime())) #将struct_time格式转换回时间戳格式 1465448495.0 print(time.strftime(%Y_%m_%d %H:%M)) #将struct_time格式转换成指定的字符串格式 2016-06-09 05:03:22 print(time.strptime("2016-06-09","%Y-%m-%d")) #将字符串格式转换成struct_time格式 import datetime print(datetime.date.today) #输出格式2016-06-09print(datetime.date.fromtimestamp(time.time()-86400)) #输出昨天的时间 current_time = datetime.datetime.now()print(current_time) #输出2016-06-09 13:09:28.271793print(current_time.timetuple()) #返回struct_time格式 print(current_time.repace(2015,5,20)) #输出2015-05-20 13:11:34.505876,返回当前时间,但指定的值将被替换 str_to_date = datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M") #将字符串转换成日期格式 2006-11-21 16:30:00 new_date = datetime.datetime.now() + datetime.timedelta(day=10) #比现在加十天new_date = datetime.datetime.now() + datetime.timedelta(hours=-10) #比现在减10小时 print(new_date)2016-06-19 13:18:14.567043 #10天以后2016-06-09 03:18:36.311825 #10小时之前下面是时间格式化的占位符的表示方法: %Y Year with century as a decimal number. %m Month as a decimal number [01,12]. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %M Minute as a decimal number [00,59]. %S Second as a decimal number [00,61]. %z Time zone offset from UTC. %a Locale's abbreviated weekday name. %A Locale's full weekday name. %b Locale's abbreviated month name. %B Locale's full month name. %c Locale's appropriate date and time representation. %I Hour (12-hour clock) as a decimal number [01,12]. %p Locale's equivalent of either AM or PM. |
5、logging日志模块
logging的日志可以分为debug(),info(),warning(),error(),critical()5个级别
这几个级别的严重性从高到低critical>error>warning>info>debug
模块的使用:
|
1
2
3
4
5
6
7
8
|
import logginglogging.warning("user[mysql]attempted wrong pasword more than 3 times")logging.critical("server had down")输出结果:WARNING:root:user[mysql]attempted wrong pasword more than 3 timesCRITICAL:root:server had down |
将日志信息写入文件:
|
1
2
3
4
|
logging.basicConfig(filename='error.log',level=logging.INFO)logging.debug('This is debug message...')logging.info("it's info message biubiubiu...")logging.warning("warning biubiubiu dididi .....") |
文件中会有info、warning的输出信息,没有debug的信息。因为定义时指定
level=logging.INFO,故不会只会写入info及info级别以上的信息。
以上程序可以写入到文件中,但是没有打印日志的时间,下面就加上打印时间:
|
1
2
3
4
5
|
logging.basicConfig(format='%(asctime)s %(message)s', datefmt='%m/%d/%Y %I:%M:%S %p')logging.warning('what is time now')执行结果:06/16/2016 04:29:53 PM what is time now |
如果想同时把log打印在屏幕和日志里,就需要在掌握一些复杂的知识:
logger:提供了应用程序可以直接使用的接口;
handler:将(logger创建的)日志记录发送到合适的目的输出;
filter:提供细度设备来决定输出那条日志记录;
formatter:决定日志记录的最终输出格式。
下面就分别介绍一下上面这四种方法在实际工作中的应用:
1、Logger
Logger输出信息之前必须获得一个Logger(如果没有显示的获取则自动创建并使用root Logger)。
这里所说的Logger就是程序的执行用户,默认是root执行,可以指定zabbix、nginx等用户。
logger = logging.getLogger() 返回一个默认的Logger也即root Logger,并应用默认的日志级别WARNING、Handler和Formatter设置
logging.setLevel(level) 指定最低的日志级别,可用日志级别有:logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、 logging.CRITICAL.
注意:此处定义为全局的日志级别, 全局日志级别是一个基调,下面局部日志级别只能比全局日志级别高或者相等才能正常输出,不能比全局日志级别低。
|
1
2
3
4
|
import logging logger= logging.getLogger('mylogger') #定义程序的执行用户logger.setLevel(logging.DEBUG) #定义全局日志级别 |
2、Handler
Handler对象负责发送相关的信息到指定目的地,有几个常用的Handler方法:
Handler.setLevel(level): 指定日志级别,低于全局日志级别的日志将被忽略
Handler.setFormatter():给这个handler选择一个Formatter
Handler.addFilter(filt)、Handler.remove(filt):新增或删除一个filter对象
可以通过addHandler()方法为Logger添加多个Handler:
|
1
2
|
logger.addHandler('输出到屏幕')logger.addHandler('输出到文件') |
下面列举几种定义Handler输出的方法:
|
1
2
3
4
5
6
7
8
9
10
11
|
logging.StreamHandler #向终端输出日志信息logging.FileHandler #向文件是输出日志信息logging.handlers.RotatingFileHandler #类似上面的FileHandler,但是它可以管理文件大小;当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建一个新的同名日志文件输出logging.handlers.TimedRotatindFileHandler #和RotatindFileHandler类似,不过它没有通过判断文件大小来决定何时重新创建文件,而是间隔一定时间就自动创建新的日志文件 logging.handlers.SocketHandler #使用TCP协议,将日志信息发送到网络logging.handlers.DatagramHandler #使用UDP协议,将日志信息发送到网络logging.handlers.SysLogHandler #日志输出到sysloglogging.handlers.SMTPHandler #远程输出日志到邮件地址logging.handlers.MemoryHandler #日志输出到内存中的指定bufferlogging.handlers.HTTPHandler #通过'GET'或'POST'远程输出到HTTP服务器 |
3、Formatter
Formatter对象设置日志信息最后的规则、结构和内容,默认时间格式为%Y-%m-%d %H:%M:%S
|
1
|
formatter= logging.Formatter('%(asctime)s - %(name)s' - %(levelname)s - %(message)s') |
Formatter参数中用到的字符串的占位符和logging.basicConfig()函数用到的相同。
4、Filter
限制只有满足过滤规则的日志才会输出,比如我们定义了filter=logging.Filter('a,b,c'),并将这个Filter添加给了一个Handler上,则使用该Handler的Logger中只有名字带有a,b,c前缀的Logger才会输出其日志。
上面分别介绍了一下logging模块的高级用法中的Logger、Handler、Formatter和Filter,下面通过一个小例子把几个用法串到一起使用:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
import logging #create loggerlogger = logging.getLogger('haifeng') #指定程序执行的用户名logger.setLevel(logging.DEBUG) #全局日志级别,也是最低日志级别 #create console handler and set level to debugch = logging.StreamHandler() #指定屏幕输出ch.setLevel(logging.DEBUG) #指定屏幕输出日志级别 #create file handler and set level to warningfh = logging.FileHandler('access.log') #指定输出到文件里fh.setLevel(logging.WARNING) #日志级别为WARING #create formatterformatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(lineno)s - %(message)s') #定义日志内容的格式 #add formatter to ch and fhch.setFormater(formatter) #定义屏幕输出按照上面定义的日志格式fh.setFormatter(formatter) #文件输出也是这个格式 #add ch and fh to loggerlogger.addHandler(ch) #添加Handler打印到终端上的方式到loggerlogger.addHandler(fh) #添加Handler打印到文件中的方式到logger #'application' codelogger.debug('debug message')logger.info('info message')logger.warn('warn message')logger.error('error message')logger.critical('critical message') |
python(八)内置模块logging/os/time/sys/json/pickle的更多相关文章
- Python day19 模块介绍3(sys,json,pickle,shelve,xml)
1.sys模块 import sys sys.path()#打印系统path sys.version()#解释程序版本信息 sys.platform()#系统平台 sys.exit(0)#退出程序 c ...
- 13、Python文件处理、os模块、json/pickle序列化模块
一.字符编码 Python3中字符串默认为Unicode编码. str类型的数据可以编码成其他字符编码的格式,编码的结果为bytes类型. # coding:gbk x = '上' # 当程序执行时, ...
- Python模块02/序列化/os模块/sys模块/haslib加密/collections
Python模块02/序列化/os模块/sys模块/haslib加密/collections 内容大纲 1.序列化 2.os模块 3.sys模块 4.haslib加密 5.collections 1. ...
- Python os、sys、pickle、json等模块
1.os 所有和操作系统相关的内容都在os模块,一般用来操作文件系统 import os os.makedirs('dirname1/dirname2') # 可生成多层递归目录 os.removed ...
- Python常用模块之os和sys
1.OS常用方法 os.access(path, mode) # 检验权限模式 os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirn ...
- python之random 、os 、sys 模块
一.random模块 import random print(random.random())#(0,1)----float 大于0且小于1之间的小数 print(random.randint(1,3 ...
- python的内置模块之os模块方法详解以及使用
1.getcwd() 获取当前工作路径 import os print(os.getcwd()) C:\python35\python3.exe D:/pyproject/day21模块/os模块.p ...
- Python模块:shutil、序列化(json&pickle&shelve)、xml
shutil模块: 高级的 文件.文件夹.压缩包 处理模块 shutil.copyfileobj(fscr,fdst [, length]) # 将文件内容拷贝到另一个文件中 import shu ...
- python学习之路-day4-装饰器&json&pickle
本节内容 迭代器&生成器 装饰器 Json & pickle 数据序列化 一.生成器 1.列表生成式 >>> L = [x * x for x in range(10 ...
随机推荐
- 《JAVA开发环境的熟悉》实验报告——20145337
- Ubuntu下编译第一个C程序的成功运行
1. 打开控制台:使用快捷键 Ctrl + Alt + T: 2. 安装gcc为C语言编译器,g++为C++ 语言编译器 sudo apt-get install g++. 3. 编辑好hello ...
- 实现memcpy
memcpy的原型: SYNOPSIS #include <string.h> void *memcpy(void *dest, const void *src, size_t n); D ...
- A trip through the Graphics Pipeline 2011_10_Geometry Shaders
Welcome back. Last time, we dove into bottom end of the pixel pipeline. This time, we’ll switch ...
- C#中 MD5和SHA1加密代码
Pwd = FormsAuthentication.HashPasswordForStoringInConfigFile(entity.Pwd, "MD5"); Pwd = For ...
- JS中的String.Math.Date
//今天放假没看东西,贴上以前的基础,没事看着玩 // String->-> var myStr = "My name is LiuYashion"; console. ...
- Mysql新建表,插入中文时报错“Incorrect string value: '\xE4\xBD\xA0\xE5\xA5\xBD' for column”问题
有时候我们在往数据库中输入信息时,如果输入的内容是中文,会报错“Incorrect string value: '\xE4\xBD\xA0\xE5\xA5\xBD' for column”. 例如: ...
- ios之json,xml解析
JSON解析步骤: 1.获取json文件路径 NSString*path = [[NSBundle mainBundle] pathForResource:@"Teacher"of ...
- Vcenter server 5.5克隆模板(创建ISO镜像)
1.进入Vcenter server 5.5控制台 --- 选择虚拟机和模版. 2.右键 XP_32 --- 模版 ---- 克隆为模板(Vcenter server 5.5连接的VMware ESX ...
- Tomcat启动时报错,Failed to start component [StandardEngine[Catalina].StandardHost[localhost].StandardContext
05-Dec-2016 11:23:44.321 SEVERE [localhost-startStop-1] org.apache.catalina.core.ContainerBase.addCh ...