MySQL语句技巧
1、查询时间的格式:
(1) 查询时将时间戳格式化
SELECT FROM_UNIXTIME(eventtime) FROM table_name
SELECT FROM_UNIXTIME(eventtime, '%Y-%m-%d %H:%i:%S') FROM table_name
(2) 查询1月18号 post_date为date或者datetime类型,同理可以只 month(post_date)=n查某个月,或者 day(post_date)=n某一天,或者 year(post_date)=n 某一年的数据。
SELECT * FROM posts WHERE MONTH(post_date)='1' AND DAY(post_date)='18';
(3)查询datetime类型时,只对比其中的日期。例如查询2019-01-02数据,post_date为datetime类型、post_time为时间戳(int)类型
SELECT * FROM posts WHERE DATE(post_date) = '2019-01-02';
SELECT * FROM posts WHERE DATE_FORMAT(post_time,'%Y-%m-%d') = '2019-01-02';
2、查询一段时间内,每5分钟间隔分时在线数据统计(eventtime是时间戳)
可以延伸统计一段时间内每10分钟、30分钟、1小时等时间段为分组的登录、付费、激活等各种数据。
SELECT FROM_UNIXTIME(`eventtime`-`eventtime`% (5*60), '%Y-%m-%d %H:%i:%S') AS stime, count(distinct uid) uids
FROM 20170828_online WHERE eventtime>=1503921000 AND eventtime<=1503925200
GROUP BY stime;
3、最高效的删除重复记录方法 ( 因为使用了ROWID)例子:
DELETE FROM EMP E WHERE E.ROWID > (SELECT MIN(X.ROWID) FROM EMP X WHERE X.EMP_NO = E.EMP_NO);
4、将两个表的查询结果合并成一行
select A.newusers,B.pay from (SELECT COUNT(DISTINCT uid) AS newusers FROM applogs.20171025_firstentry WHERE game=12 AND client=1) AS A,
(SELECT SUM(money)/100 AS pay FROM applogs.20171025_paylog WHERE eventdate=flogindate AND game=12 AND client=1 ) AS B;
5、列转行技巧
eg:统计id为1的记录数,id为2的记录数以及id为3的记录数。
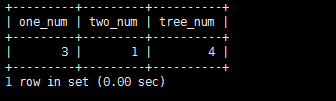
SELECT COUNT(CASE WHEN id=1 THEN 1 ELSE NULL END ) AS `one_num`,COUNT(CASE WHEN id=2 THEN 1 ELSE NULL END ) AS `two_num`,COUNT(CASE WHEN id=3 THEN 1 ELSE NULL END ) AS `tree_num` FROM test;
表数据:
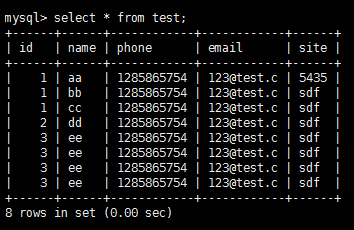
执行该语句的结果:
6、group_concat函数的使用方法
公式:group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
基础表格:(以5中的表格数据为例)
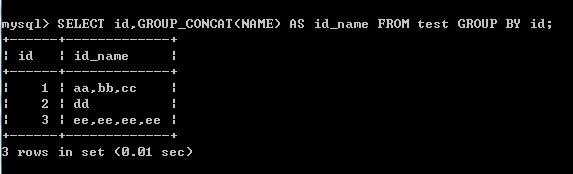
(1)以id分组,把name字段的值放在同一结果行,以逗号分隔(默认)
SELECT id,GROUP_CONCAT(NAME) AS id_name FROM test GROUP BY id;
结果:
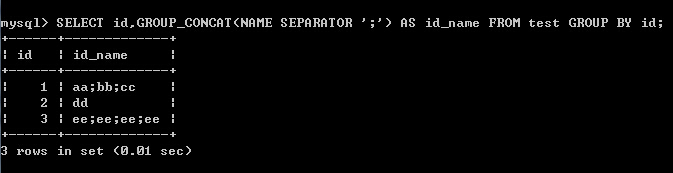
(2)以id分组,把name字段的值放在同一结果行,以分号分隔
SELECT id,GROUP_CONCAT(NAME SEPARATOR ';') AS id_name FROM test GROUP BY id;
结果:
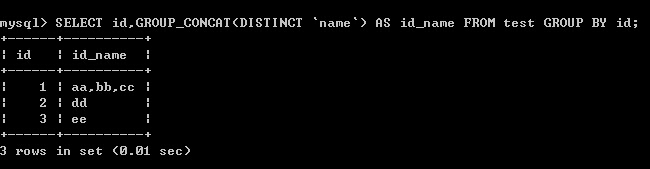
(3)以id分组,把去冗余的name字段的值放在同一结果行, 以逗号分隔
SELECT id,GROUP_CONCAT(DISTINCT `name`) AS id_name FROM test GROUP BY id;
结果:
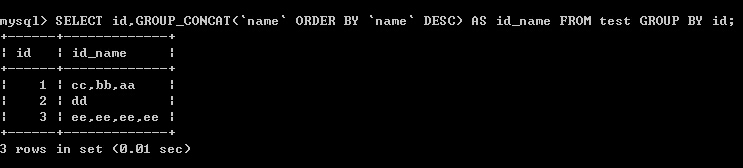
(4)以id分组,把name字段的值放在同一结果行,逗号分隔,以name排倒序
SELECT id,GROUP_CONCAT(`name` ORDER BY `name` DESC) AS id_name FROM test GROUP BY id;
结果:
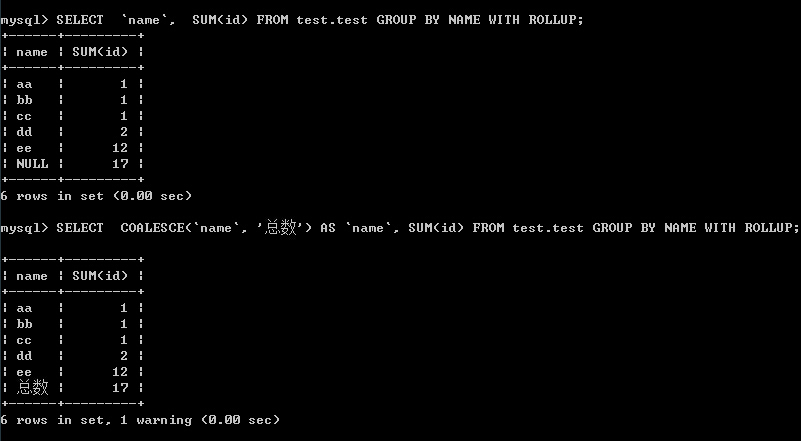
7、with rollup 的用法 (表格以5中的数据表为例)
SELECT `name`, SUM(id) FROM test.test GROUP BY NAME WITH ROLLUP
SELECT COALESCE(`name`, '总数') AS `name`, SUM(id) FROM test.test GROUP BY NAME WITH ROLLUP
结果:
COALESCE函数说明:
select coalesce(a,b,c);
如果a==null,则选择b;如果b==null,则选择c;如果a!=null,则选择a;如果a b c 都为null ,则返回为null。coalesce(a,b,c,d...)同理。
8、插入数据出现UNIQUE索引或PRIMARY KEY冲突时就使用更新(ON DUPLICATE KEY UPDATE 语法)
(1) INSERT INTO `sy`.`day` (id, name, phone) VALUES('666', 'xst', '10086') ON DUPLICATE KEY UPDATE name = VALUES(name),phone = VALUES(phone);
(2) INSERT INTO TABLE (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; (UPDATE TABLE SET c=c+1 WHERE a=1;)
(3) INSERT INTO TABLE (a,b,c) VALUES (1,2,3),(2,5,7),(3,3,6),(4,8,2) ON DUPLICATE KEY UPDATE b=VALUES(b);
(4)插入一行数据,单主键已经存在,则更新该主键的相关数据,但数据表中 level原先的数据等于0或者为空或者小于即将更新进去的 level 值的时候,就将新的值更新进去,否则不做处理。
INSERT IGNORE INTO test.test (uid,roleid,rolename,game,`server`,`level`) VALUES('2','00002','test2','1','1001','98') ON DUPLICATE KEY UPDATE
`level` = (CASE WHEN `level`=0 OR 'level'=NULL OR `level`<VALUES(`level`) THEN VALUES(`level`) ELSE `level` END)
9、查询一个用户是否连续 7天或者10天登录(通过两个日期字段计算其相差的天数)
SELECT eventdate FROM login WHERE user='xst' AND DATEDIFF(eventdate,firstlogindate)<=7 GROUP BY eventdate
SELECT COUNT(DISTINCT eventdate) AS days FROM login WHERE user='xst' AND DATEDIFF(eventdate,flogindate)<=7
10、查询某个字段的一个值出现过两次以上的记录
(1)查询数据表中did出现两次以上的记录:
select * from did_table where did in (select did from did_table group by did having count(did)>1);
(2)查询用户登录数据表(记录一个用户登录时的用户和设备信息)中使用两种以上客户端(或者设备)登录的用户。uid为用户id,cid为客户端id
SELECT uid,COUNT(cid) AS cids FROM (SELECT uid,cid FROM data_base.20181104_login WHERE channel='140' GROUP BY uid,cid) AS A GROUP BY uid HAVING cids>1;
11、将一个表(B)的某个字段数据更新到另一个表(A)
UPDATE first_open A, open B SET A.uuid=B.uuid WHERE A.game=B.game AND A.did=B.did AND A.cid=B.cid AND A.aid=B.aid AND A.osid=B.osid and A.ip=B.ip and A.eventtime=B.eventtime
12、查询每个用户最后一条数据
select * from (select * from usertable order by eventtime desc) a group by uid;
13、查询两个表某个字段的交集
(1)左表有,右表没有
SELECT A.finish_date,B.game,A.order_num,B.pay_num,B.pay_type,A.company FROM mydb.mytable AS A LEFT JOIN mydb.testtab AS B ON A.order_num = B.pay_num WHERE B.game=63 AND B.pay_num IS NULL
(2)右表有,左表没有
SELECT B.game,A.order_num,B.pay_num,B.pay_type FROM mydb.mytable AS A RIGHT JOIN mydb.testtab AS B ON A.order_num = B.pay_num WHERE B.game=63 AND A.order_num IS NULL
14、sql中的三元表达式
SELECT IF(type=1,'增加','减少') AS type,role_name,item_name FROM_UNIXTIME(eventtime) FROM base.item
SELECT CASE WHEN type=1 THEN '增加' ELSE '减少' END AS type,role_name,item_name FROM_UNIXTIME(eventtime) FROM base.item
MySQL语句技巧的更多相关文章
- MYSQL SQL语句技巧初探(一)
MYSQL SQL语句技巧初探(一) 本文是我最近了解到的sql某些方法()组合实现一些功能的总结以后还会更新: rand与rand(n)实现提取随机行及order by原理的探讨. Bit_and, ...
- php代码优化,mysql语句优化,面试需要用到的
首先说个问题,就是这些所谓的优化其实代码标准化的建议,其实真算不上什么正真意义上的优化,还有一点需要指出的为了一丁点的性能优化,甚至在代码上的在一次请求上性能提升万分之一的所谓就去大面积改变代码习惯, ...
- mysql语句:批量更新多条记录的不同值[转]
mysql语句:批量更新多条记录的不同值 mysql更新语句很简单,更新一条数据的某个字段,一般这样写: 帮助 1 UPDATE mytable SET myfield = 'value' WHERE ...
- mysql语句:批量更新多条记录的不同值
mysql更新语句很简单,更新一条数据的某个字段,一般这样写: 1 UPDATE mytable SET myfield = 'value' WHERE other_field = 'other_va ...
- MySql基础笔记(二)Mysql语句优化---索引
Mysql语句优化--索引 一.开始优化前的准备 一)explain语句 当MySql要执行一个查询语句的时候,它首先会对语句进行语法检查,然后生成一个QEP(Query Execution Plan ...
- 不可不知的mysql 常用技巧总结
不可不知的mysql 常用技巧总结 mysql常用命令 mysqld --启动mysql数据库 show databases; -- 查看数据库 use database; -- 选择数据库 show ...
- Mysql语句优化
总结总结自己犯过的错,网上说的与自己的Mysql语句优化的想法. 1.查询数据库的语句的字段,尽量做到用多少写多少. 2.建索引,确保查询速度. 3.orm框架自带的方法会损耗一部分性能,这个性能应该 ...
- MYSQL注入技巧备忘录
MYSQL一些技巧 仅仅是作为自己备忘录,如果错误,敬请斧正. 0)基础饶过 1.大小写绕过 2.双写绕过 3.添加注释 /*!*/ or /*!小于mysql版本*/ 5.宽字节.Latin1默认编 ...
- 如何根据执行计划,判断Mysql语句是否走索引
如何根据执行计划,判断Mysql语句是否走索引
随机推荐
- php递归实现一维数组转为指定树状结构 --- 省市区处理
### 这两天脑壳痛,一时短路,想不到准备利用递归实现这个需求,最后还是要请教同事,回来自己在实现了一遍,并记录下来 ### 原数据: // { // 广东省: { // 广州市: [ // &quo ...
- springMVC上传
1.页面 2.开始上传按钮对应的JS 3.添加文件按钮的方法,下图中1是从fast中取到的文件名称,2是文件图片的路径 下面就是后台的一些类.方法等 4.bean层,生成的get和set方法我就不写了 ...
- gardner 算法matlab实现
% 仿真4比特原始数据与星座图的编码映射过程: % 完成16QAM信号的调制解调: % 基带信号符号速率 ps =1Mbps: % 成形滤波器的滚降因子 a=0.8: % 载波信号频率fc=2MHz ...
- 基于tkinter的GUI编程
tkinter:tkinter是绑定了Python的TKGUI工具集,就是Python包装的Tcl代码,通过内嵌在Python解释器内部的Tcl解释器实现的,它是Python标准库的一部分,所以使用它 ...
- js中valueOf方法的使用
今天一位刚毕业的同事问了我一个问题,为什么这段代码执行结果是-1.代码如下: var o = { valueOf: function(){ return -1; } }; o = +o; 当时我也是懵 ...
- Jenkins+maven环境部署
选择使用tomcat下运行jenkins项目,安装步骤如下 1. 安装tomcat,查看想要下载的版本 https://mirrors.cnnic.cn/apache/tomcat/ wget h ...
- js变量污染引起的诡异bug
js方法是这样的: //保存提货券JSON数据到隐藏字段 saveVoucherListInfoToHiddenFiled: function () { //保存绑定商品信息 var voucherL ...
- Excel—数学函数
ROUND(四舍五入函数)就是说把一个小数点后多位的数四舍五入小数点位数的函数 函数语法:ROUND(哪个数,要四舍五入到小数点后几位) ROUNDUP(保留小数点几位后进位的函数)就是说要保留一个小 ...
- notes for lxf(五)
类和实例的绑定方法和属性 实例绑定 obj.func = func obj.func(obj, &argv) obj.func = MethodType(func, obj) 第一个参数是方 ...
- 2018年多校第四场第二题 B. Harvest of Apples hdu6333
题意:给定10^5以内的n,m求∑组合数(n,i),共10^5组数据. 题解: 定义 S(n, m) = \sum_{i = 0} ^ {m} {n \choose i}S(n,m)=∑i=0m ...