大数据学习之hdfs集群安装部署04
1-> 集群的准备工作
1)关闭防火墙(进行远程连接)
systemctl stop firewalld
systemctl -disable firewalld
2)永久修改设置主机名
vi /etc/hostname
注意:需要重启生效->reboot
3)配置映射文件
vi /etc/hosts
#127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
#::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.40.11 bigdata11
192.168.40.12 bigdata12
192.168.40.13 bigdata13
2-> 安装jdk
1)上传tar包
用winscp那个软件吧
2)解压tar包
tar -zxvf jdk
3)配置环境变量
vi /etc/profile
export JAVA_HOME=/root/training/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
注意:加载环境变量 source /etc/profile
4)发送到其它机器(偷个懒,不用一个一个的配,哈哈哈)
scp -r /root/.bash_profile root@bigdata12:/root/.bash_profile
scp -r /root/.bash_profile root@bigdata13:/root/.bash_profile
注意:加载环境变量 source /etc/profile
5)配置ssh免密登录
-》ssh-keygen 生成密钥对
-》 ssh-copy-id 自己
ssh-copy-id 其它
ssh-copy-id 其它
每台机器都这样操作。
1:生产公钥对:ssh-keygen -t rsa(直接回车到底)
2:把公钥发送给serverB: ssh-copy-id -i .ssh/id_rsa.pub root@bigdata11
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata12
ssh-copy-id -i .ssh/id_rsa.pub root@bigdata13
3-> 安装HDFS集群(注意,只是安装的hdfs,并非完全的hadoop,我们用到什么就装什么。有助于学习理解)
1) 修改hadoop-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
2) 修改core-site.xml
<!--配置hdfs-->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata11:9000</value>
</property>
</configuration>
3) 修改hdfs-site.xml
<configuration>
<!--配置元数据存储位置-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/training/hadoop-2.8.4/dfs/name</value>
</property>
//配置数据存储位置
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/training/hadoop-2.8.4/dfs/data</value>
</property>
</configuration>
4)格式化namenode
hadoop namemode -format
5)分发hadoop到其它机器
scp -r /root/training/hadoop-2.8.4/ bigdata12:/root/training/
scp -r /root/training/hadoop-2.8.4/ bigdata13:/root/training/
6)配置hadoop环境变量
export HADOOP_HOME=/root/training/hadoop-2.8.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6)分发hadoop环境变量
scp -r /root/.bash_profile root@bigdata12:/root/.bash_profile
scp -r /root/.bash_profile root@bigdata13:/root/.bash_profile
注意:加载环境变量 source /root/.bash_profile(每个虚拟机都要配置)
7)启动namenode
hadoop-daemon.sh start namenode
8)启动datanode
hadoop-daemon.sh start datanode
9)访问namenode提供的web端口:50070
4-> 自动批量的启动脚本
1)修改配置文件vi /etc/hadoop/slaves(记得每台虚拟机都要配置哦)
bigdata12
bigdata13
2)执行启动命令
start-dfs.sh
start-dfs.sh
如果在安装过程中出现了问题。可以私聊我的qq。在线帮忙解决。或者将问题发在我qq邮箱1850748316@qq.com,我会第一时间回复你!!
附加一个免密登录的原理图吧!!
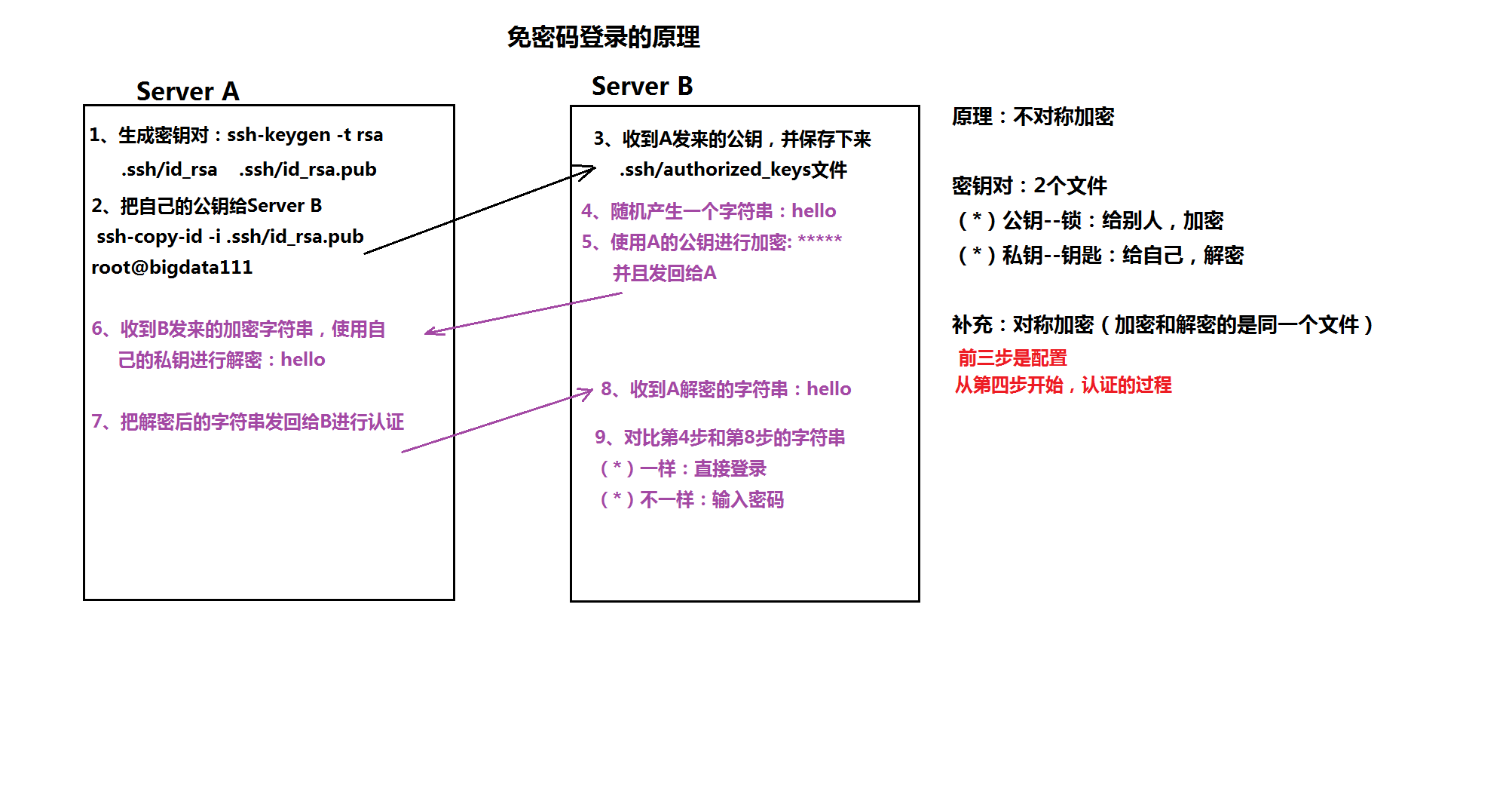
===========================================================》》
小bug1:secondNameNode(备份)在bigdata11那个机器上,这样第二名称节点也没有起什么作用!
完全成了摆设
解决方案:先在bigdata11上修改hdfs-site.xlm
添加如下代码
<property>
<!--注意不是https。-->
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata12:50090</value>
</property>
这里只是在bigdata11上修改了。由于是集群模式。所有机子都要修改!!!
直接分发到其他机器就行了
scp hdfs-site.xml bigdata12:$PWD
scp hdfs-site.xml bigdata13:$PWD
重启集群就会发现只有bigdata12上才有secondnamenode
大数据学习之hdfs集群安装部署04的更多相关文章
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 大数据学习——hadoop2.x集群搭建
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- HDFS集群安装部署
准备环境: 三台centos7虚拟机(Node-1,Node-2,Node-3) 配置虚拟机网络,保证三台机器可以互相ping通,并且和宿主机可以互相ping通.如果仅仅是作为虚拟机学习,可以关闭防火 ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- 第06讲:Flink 集群安装部署和 HA 配置
Flink系列文章 第01讲:Flink 的应用场景和架构模型 第02讲:Flink 入门程序 WordCount 和 SQL 实现 第03讲:Flink 的编程模型与其他框架比较 第04讲:Flin ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- flink部署操作-flink standalone集群安装部署
flink集群安装部署 standalone集群模式 必须依赖 必须的软件 JAVA_HOME配置 flink安装 配置flink 启动flink 添加Jobmanager/taskmanager 实 ...
随机推荐
- 使用Redis实现实时排行榜
游戏中存在各种各样的排行榜,比如玩家的等级排名.分数排名等.玩家在排行榜中的名次是其实力的象征,位于榜单前列的玩家在虚拟世界中拥有无尚荣耀,所以名次也就成了核心玩家的追求目标. 一个典型的游戏排行榜包 ...
- Java基础知识拾遗(四)
IO SequenceInputStream,允许链接多个InputStream对象.在操作上该类从第一个InputStream对象进行读取,知道读取完全部内容,然后切换到第二个InputStream ...
- python基础学习小结
Python是一门面向对象的解释性语言(脚本语言),这一类语言的特点就是不用编译,程序在运行的过程中,由对应的解释器向CPU进行翻译,个人理解就是一边编译一边执行.而JAVA这一类语言是需要预先编译的 ...
- 深入浅出mybatis之缓存机制
目录 前言 准备工作 MyBatis默认缓存设置 缓存实现原理分析 参数localCacheScope控制的缓存策略 参数cacheEnabled控制的缓存策略 总结 前言 提到缓存,我们都会不约而同 ...
- docker学习------swarm集群虚机异常关机,node状态为down
1.因昨天虚机异常关闭,导致今天上去查看时,node节点状态显示为down 2.查了些相关资料,找到处理办法(因我的节点没有任何数据,所以直接对其进行清除) docker swarm leave -- ...
- js ajax方法模板
ajax方法: $.ajax({ type: "POST", url: "WebService.asmx/sp_sj_yisheng_gexinhuaAdd", ...
- SQLServer2012基于扩展事件的阻塞监控
一.前言 SQL阻塞Block是事务联机系统OLTP的产物.由于锁导致的资源等待,事务执行时间过长,直接影响业务:了解阻塞,发现阻塞,已作为DBA日常维护的重中之重. 通过dmv可以发现当前正在阻塞的 ...
- 第4章学习小结_串(BF&KMP算法)、数组(三元组)
这一章学习之后,我想对串这个部分写一下我的总结体会. 串也有顺序和链式两种存储结构,但大多采用顺序存储结构比较方便.字符串定义可以用字符数组比如:char c[10];也可以用C++中定义一个字符串s ...
- Angular_上拉刷新
1.先不做上拉触发,用button模拟一下,触发函数 export class StudyComponent implements OnInit { /*列表数据流 */ list$: Observa ...
- 整理c盘文件
清理大文件时,发现以下目录文件过大,删除后可以正常启动java程序,此目录应该是安装jdk时的缓存文件,可以删除 C:\Users\xxxx\AppData\LocalLow\Oracle\Java\ ...