Convolutional Pose Machines(理解)
0 - 背景
人体姿态识别存在遮挡以及关键点不清晰等主要挑战,然而,人体的关键点之间由于人体结构而具有相互关系,利用容易识别的关键点来指导难以识别关键点的检测,是提高关键点检测的一个思路。本文通过提出序列化结构模型,来提高人体姿态识别任务的效果。
1 - 贡献
- 使用一个序列卷积结构模型学习表达空间信息
- 采用系统的方法来设计和训练模型,以学习图像特征和依赖图像空间模型进行结构化预测的任务
- 在MPII/LSP/FLIC等数据集上实现了最好的性能
- 分析了联合训练一个多阶段、中间重复监督的架构的效果
2 - 整体思路
2.1 - CPM(Convolutional Pose Machines)
Convolutional Pose Machines(CPM)算法思想来自于Pose Machine,其网络结果如下图:

图中(a)和(b)是pose machine中的结构,(c)和(d)是其对应的卷积网络结构,(e)展示了图片在网络中传输的不同阶段的感受野。
- Stage 1:对输入图片做处理,其中$X$代表经典的VGG结构,并且最后采用$1 \times 1$卷积输出belief map,如果人体有$k$个关键带来,则$belief map$的通道数为$k$
- Stage T:对于Stage 2以后的Stage,其结构都统称为Stage T,其输入为上一个Stage的输出以及对原始图片的特征提取的联合,输出于Stage 1一致

2.2 - 损失函数
损失函数公式如下:
$$f_t=\sum_{p=1}^{P+1}\sum_{z\in Z}\begin{Vmatrix}b_t^p(z)-b_*^p(z)\end{Vmatrix}^2_2$$
3 - 实验
3.1 - intermediate supervision
如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小,而发生梯度消失现象。
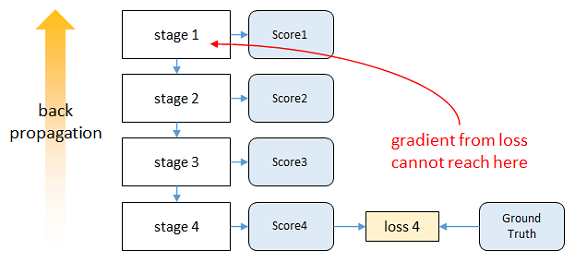
本文为了解决这个问题,提出了中间监督方法,从而保证底层参数的正常更新。
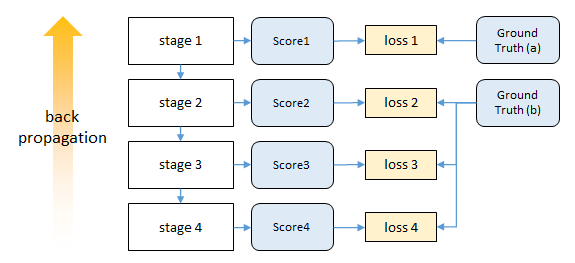
效果如下图,可以看到,加入中间监督之后,在靠近输入的stage,其梯度比没有中间监督大很多,从而保证学习的效果。

3.2 - 感受野
CPM采用大卷积核获得大感受野,对于被遮挡的关键点检测很有效果。并且本文通过实验表明了随着感受野的增大,预测的准确率上升,如下图:

文中提出增大感受野有如下几种方式:
- 增大pool,但会损失较多信息从而减小了精度
- 增大卷积核,同时会增加参数量
- 增加卷积层,层数过多容易产生梯度消失等问题
4 - 参考资料
https://arxiv.org/abs/1602.00134
https://blog.csdn.net/cherry_yu08/article/details/80846146
https://blog.csdn.net/shenxiaolu1984/article/details/51094959
https://www.cnblogs.com/JillBlogs/p/9098989.html
Convolutional Pose Machines(理解)的更多相关文章
- Convolutional Pose Machines
Convolutional Pose Machines 2018-12-10 18:17:20 Paper:https://www.cv-foundation.org/openaccess/conte ...
- 人体姿势识别,Convolutional pose machines文献阅读笔记。
开源实现 https://github.com/shihenw/convolutional-pose-machines-release(caffe版本) https://github.com/psyc ...
- SPM:Single-stage Multi-person Pose Machines
figure1图b figure1 -a figure3-a 图一-a
- learning to Estimate 3D Hand Pose from Single RGB Images论文理解
持续更新...... 概括:以往很多论文借助深度信息将2D上升到3D,这篇论文则是想要用网络训练代替深度数据(设备成本比较高),提高他的泛性,诠释了只要合成数据集足够大和网络足够强,我就可以不用深度信 ...
- 论文笔记 Stacked Hourglass Networks for Human Pose Estimation
Stacked Hourglass Networks for Human Pose Estimation key words:人体姿态估计 Human Pose Estimation 给定单张RGB ...
- (转)Awesome Human Pose Estimation
Awesome Human Pose Estimation 2018-10-08 11:02:35 Copied from: https://github.com/cbsudux/awesome-hu ...
- 从DeepNet到HRNet,这有一份深度学习“人体姿势估计”全指南
从DeepNet到HRNet,这有一份深度学习"人体姿势估计"全指南 几十年来,人体姿态估计(Human Pose estimation)在计算机视觉界备受关注.它是理解图像和视频 ...
- 2016CVPR论文集
http://www.cv-foundation.org/openaccess/CVPR2016.py ORAL SESSION Image Captioning and Question Answe ...
- PyTorch深度学习计算机视觉框架
Taylor Guo @ Shanghai - 2018.10.22 - 星期一 PyTorch 资源链接 图像分类 VGG ResNet DenseNet MobileNetV2 ResNeXt S ...
随机推荐
- 【递归】hex2dec
自己捉摸了好久,由于不熟悉. #include <stdio.h> int dec2hex(char *p); int base; int num; int main(void) { ch ...
- Python_自定义递归的最大深度
自定义递归的最大深度 python默认的最大递归深度为998,在有些情况下是不够用,需要我们自行设置.设置方式如下: import sys sys.setrecursionlimit(num) # n ...
- Linux之判断字符串是否为空
help命令可以查看帮助 help test 正确做法: #!/bin/sh STRING= if [ -z "$STRING" ]; then echo "ST ...
- jexus独立版设置支持https
先用命令找到libssl.so find / -name libssl.so.* 执行完命令之后找到libssl.so.x.x.x如(libssl.so.1.0.0) 再到jexus/runtime/ ...
- hdu-1711(hash)
题意:给你T组数据,每组数据分别输入n,m和长度为n的数字数组,和长度为m的数字数组,问你长度为m的数组第一次出现在长度为n的数组的位置 解题思路:标准字符串匹配问题,一般用kmp解,拿来练hash ...
- 「洛谷4197」「BZOJ3545」peak【线段树合并】
题目链接 [洛谷] [BZOJ]没有权限号嘤嘤嘤.题号:3545 题解 窝不会克鲁斯卡尔重构树怎么办??? 可以离线乱搞. 我们将所有的操作全都存下来. 为了解决小于等于\(x\)的操作,那么我们按照 ...
- 使用diff或者vimdiff比较远程文件(夹)与本地文件夹
方法1:管道给diff $ssh eric@192.168.1.11 "cat ~/remote_file.txt" | diff - ~/local_file.txt 如果 Fi ...
- js中获取时间new date()的用法
获取时间: var myDate = new Date();//获取系统当前时间 获取特定格式的时间: myDate.getYear(); //获取当前年份(2位) myDate.getFullYea ...
- 关于AI
自己看着办吧 http://tieba.baidu.com/p/6008409988?fr=ala0&pstaala=1&tpl=5&fid=93764&isgod=0
- Qt(MinGW版)在win7 64位上无法播放视频解决方案
[原因分析] Qt自带的MinGW是32位版本,不支持64位的ffmpeg(解码器). 无法播放视频,问题就出在opencv_ffmpeg2411_64.dll(opencv\bin\)上. [解决方 ...