Transformer【Attention is all you need】
前言
Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的方式映射成(y1, y2 ... ym), 之前的做法是用RNN进行encode-decoder,但是由于RNN在某一时间刻的输入是依赖于上一时间刻的输出,所以RNN不能并行处理,导致效率低效,而Transfomer就避开了RNN,因此encoder-decoder效率高。
Transformer
从一个高的角度来看Transformer,它就是将源语言 转换 成目标语言

打开Transformer单元,我们会发现有两个部分组成,分别是encoders单元和decoders单元
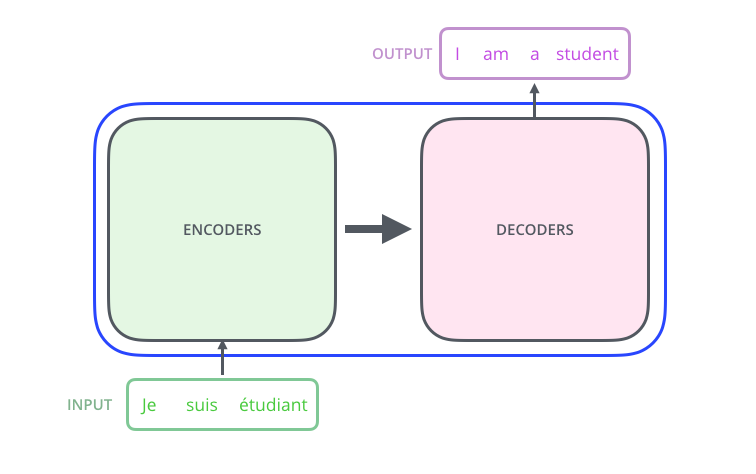
而对于encoders单元,它是由六个encoder组成的,同样decoders单元,它也是由六个decoders组成。

对于每一个encoder,它们结构都一样的,但是权重不共享,每一个encoder的结构都是由两部分组成,分别是self-attention和feed forward neural network。
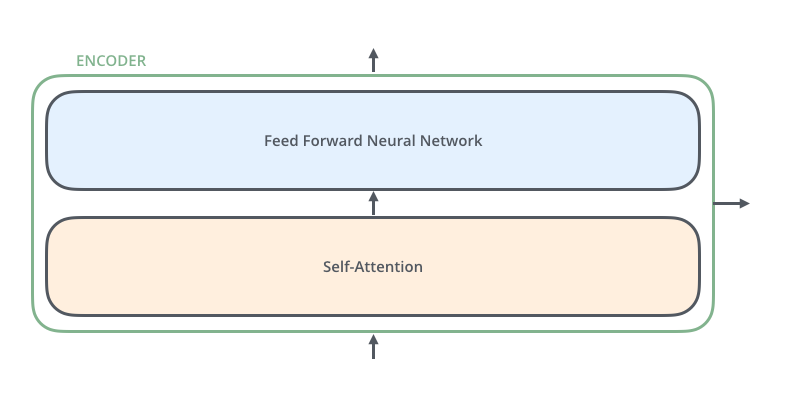
Transformer的处理流程是这样的:输入数据传给self-attention,然后selft-attention计算每一个位置的与其他位置的相关性,从而获得每一个位置的输出结果,该输出结果传给FFNN,得到第一个encoder的输出z1,z1作为第二个encoder的输入,步骤如上,直到最后一个encoder输出 ouput。
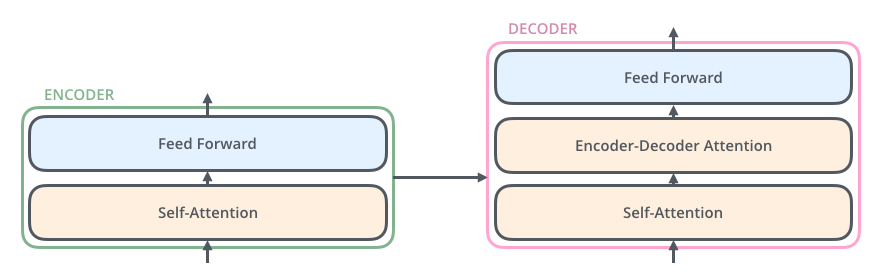
该输出ouput,在传给decoder,大致过程和encoder一致,有些许差异,稍后分析。
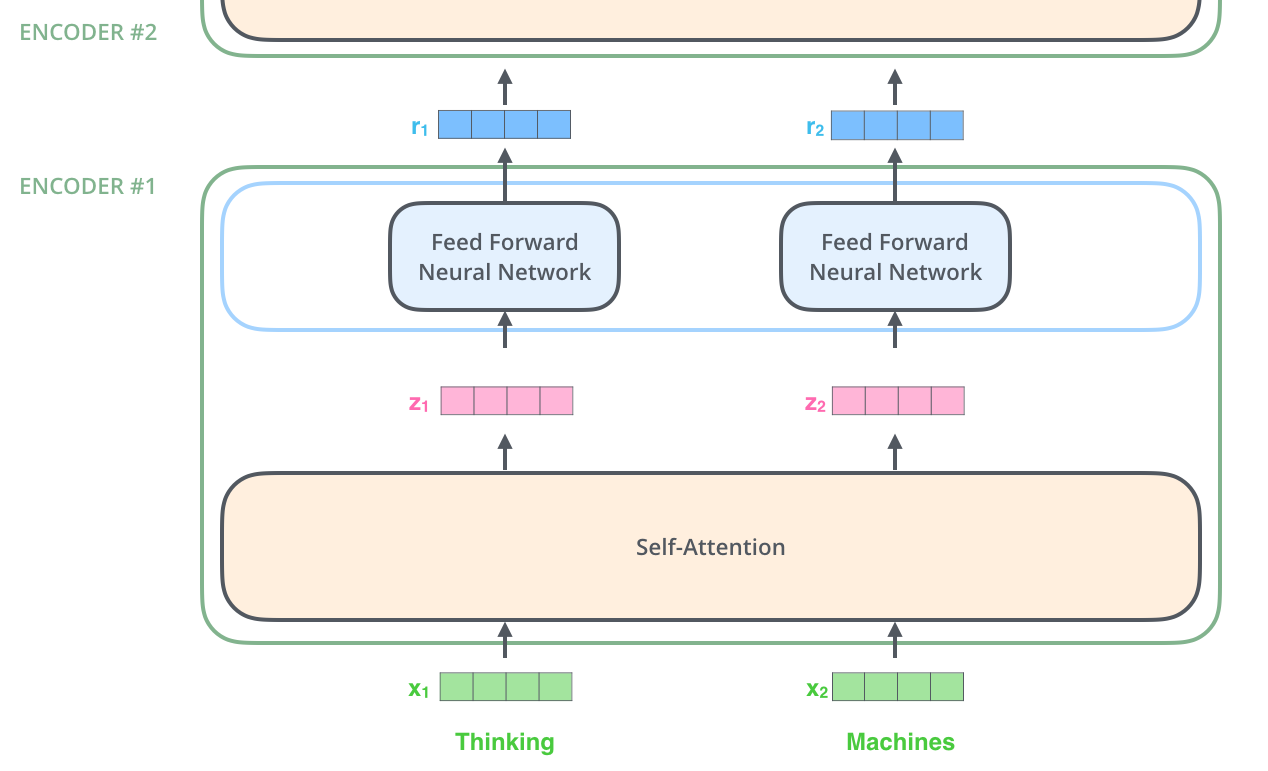
具体示例:
假设输入的是两个单词:Thinking Machine, 首先对单词作embedding,然后作为第一个encoder的输入,在第一个encoder里面经过self-attention,得到zi,然后zi经过FFNN得到第一个encoder的输出ri,然后ri像embedding一样,作为第二个encoder的输入
self-attention
selft-attention的作用就是求 某一位置与其他位置的相关性权重。
selft-attention执行流程:
第一步:
输入向量 embedding分别与三个权重矩阵(WQ WK ,WV)相乘,得到三个向量, Queries, Keys, Values。据说三个权重矩阵(WQ WK ,WV)是在训练过程中获得的,我很好奇它是怎么训练获得的。
还有就是 Queries, Keys, Values这三个向量的维度要比 embedding的维度小, Queries, Keys, Values的维度是64, embedding的维度是512。至于为什么要小,是为了便于multi-head计算
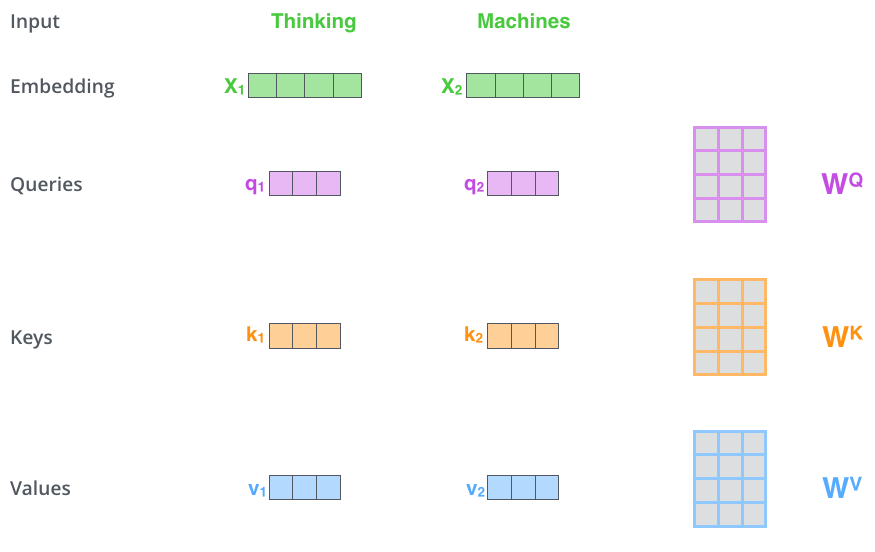
第二步:
计算每一个位置与其他位置的得分。
如图,以第一个单词Thinking为例,用q1分别与不同位置的keys向量ki进行点积,得到与每其他位置的得分。
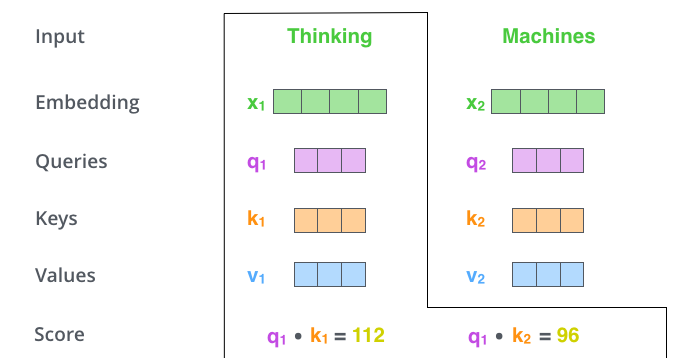
第三步
将得分 除以 8, keys的维度平方根,paper是64。
第四步
对得分进行sotfmax
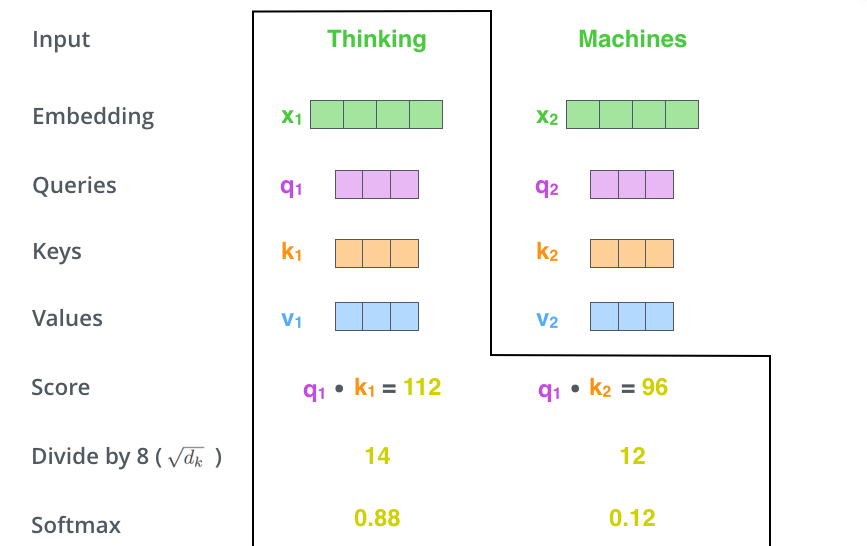
第五步:
用softmax的得分(权重) 乘以 对应位置的values向量,
第六步:
对加权values向量求和
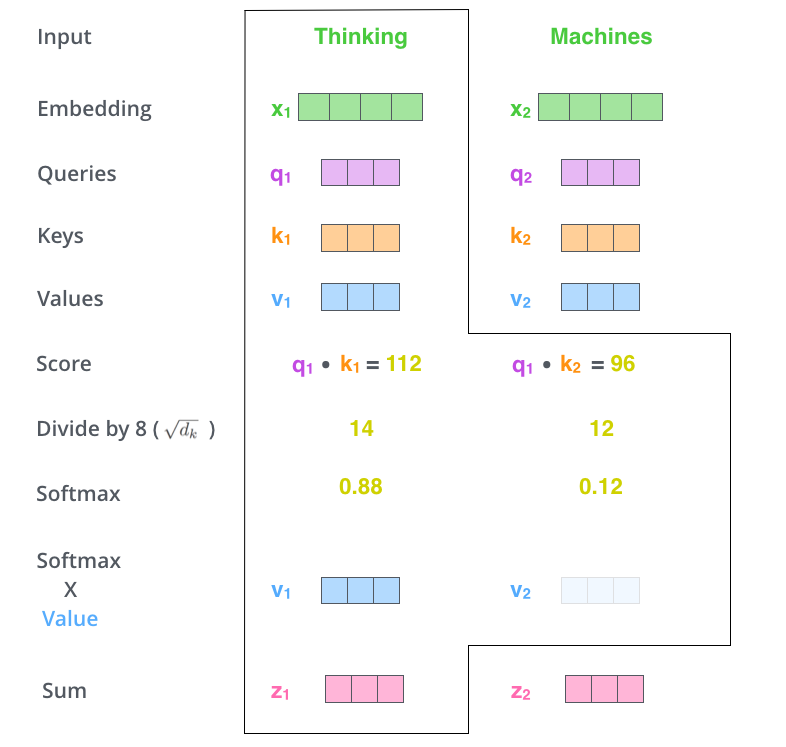
以上是对于一个单词的运算过程,可以用矩阵对整个输入序列进行操作
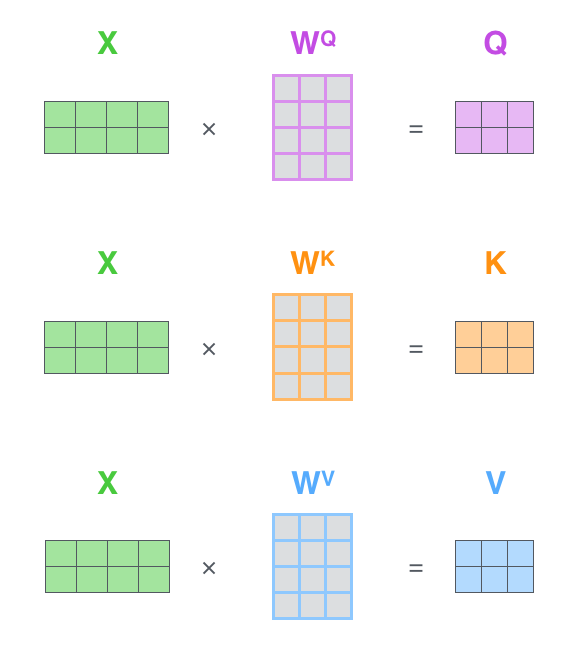
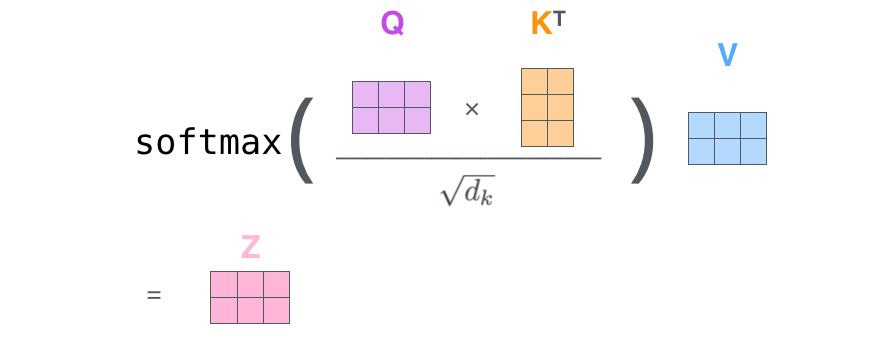
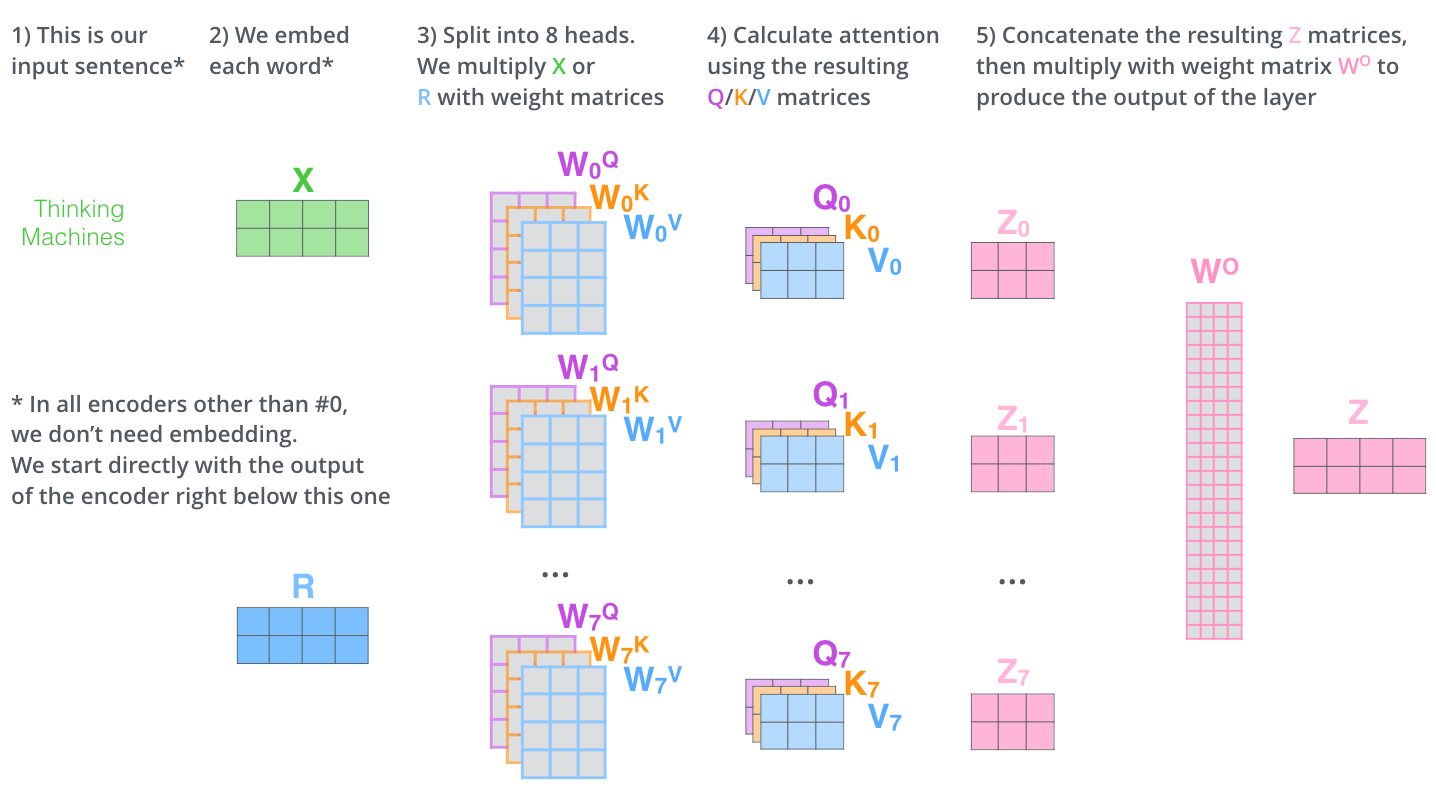
优化Multi-head
motivation:
1、对于上面的计算过程,最后的到z1仅包含与他相关的那些位置的信息,而其他位置信息就包含的较少,Multi-headed可以覆盖到每一个位置的信息 (不太理解,不就是要找到最相关的位置吗, 为什么要其他的都包含呢)
2、它为attention层提供了更多的表示空间。在上面的计算过程中,都产生了一个 Queries,Keys, Values的权重矩阵,Transformer使用了八个head,每一个head相当于一个独立的子空间,在这里将随机初始化 Queries,Keys, Values的权重矩阵,所以最终会有八个权重矩阵,也就是会有八个 Queries,Keys, Values向量。
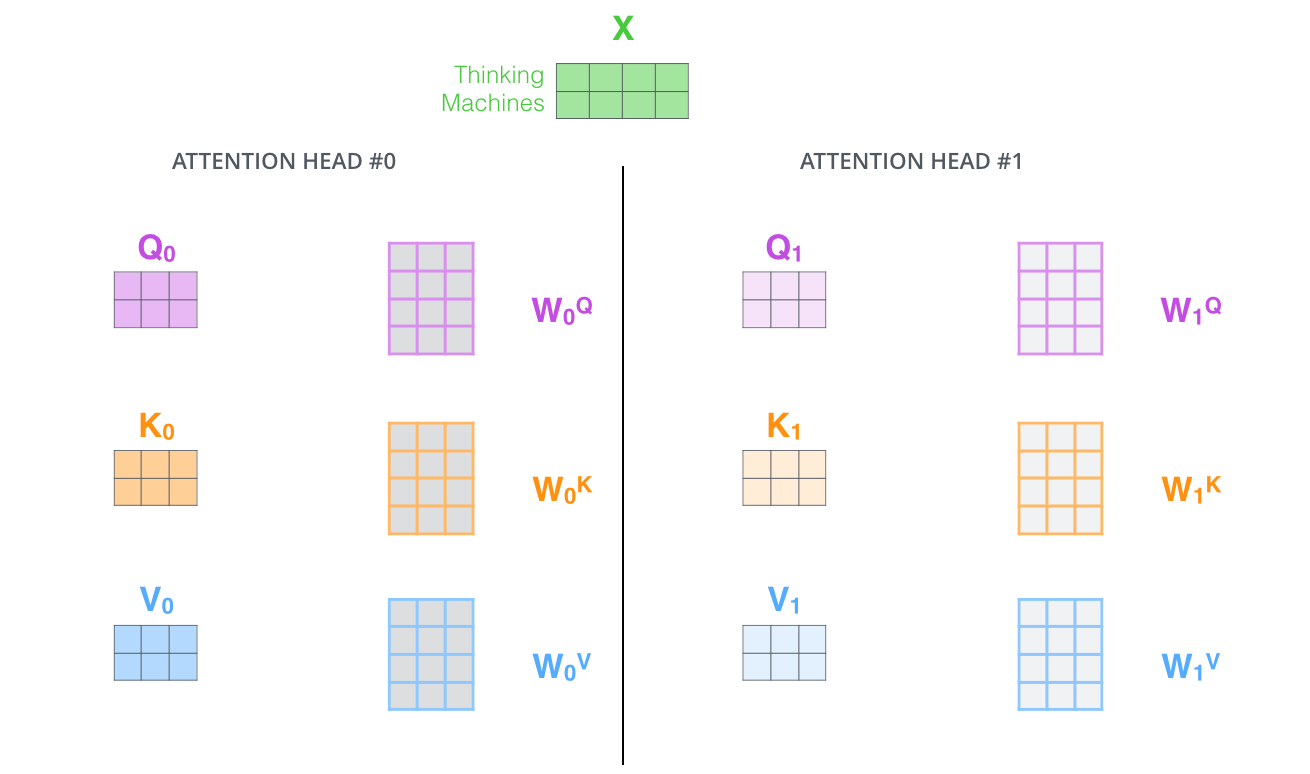
与之前一样的计算方式,embeding需要与每一个head进行计算,最后会有八个输出
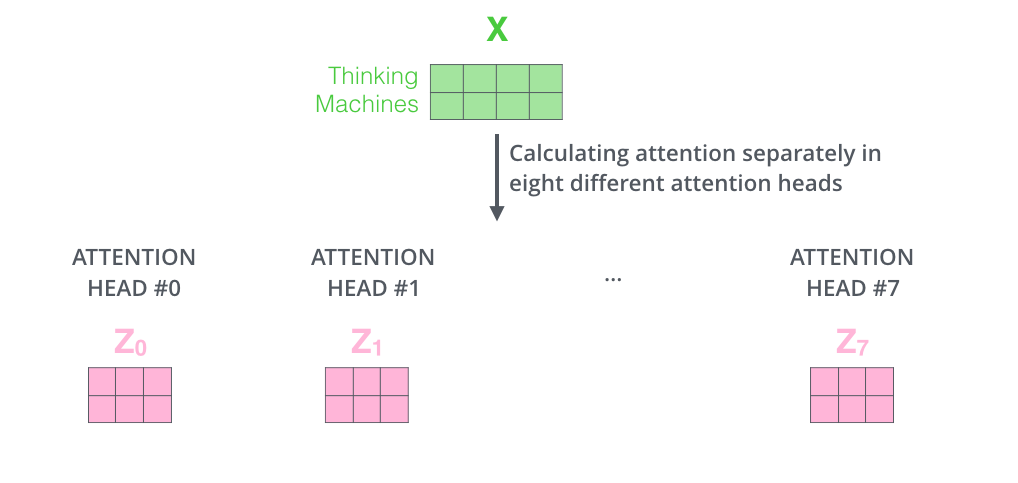
然后八个输出拼接成一个向量,乘以 另一个权重矩阵Wo (怎么得到的?)得到最后的输出Z

multi-headed的整体过程如下:
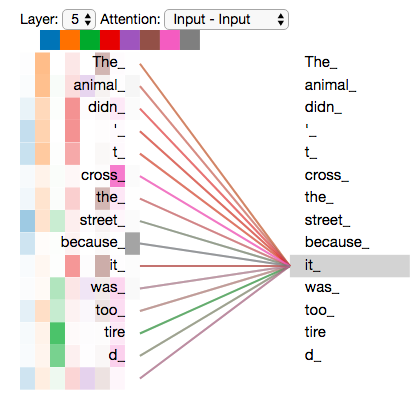
multi-headed与single-headed的效果:
single-headed只关注与他最相关的,也就是权重最大的,如左图。而Multi-headed会关注好的内容,如右图

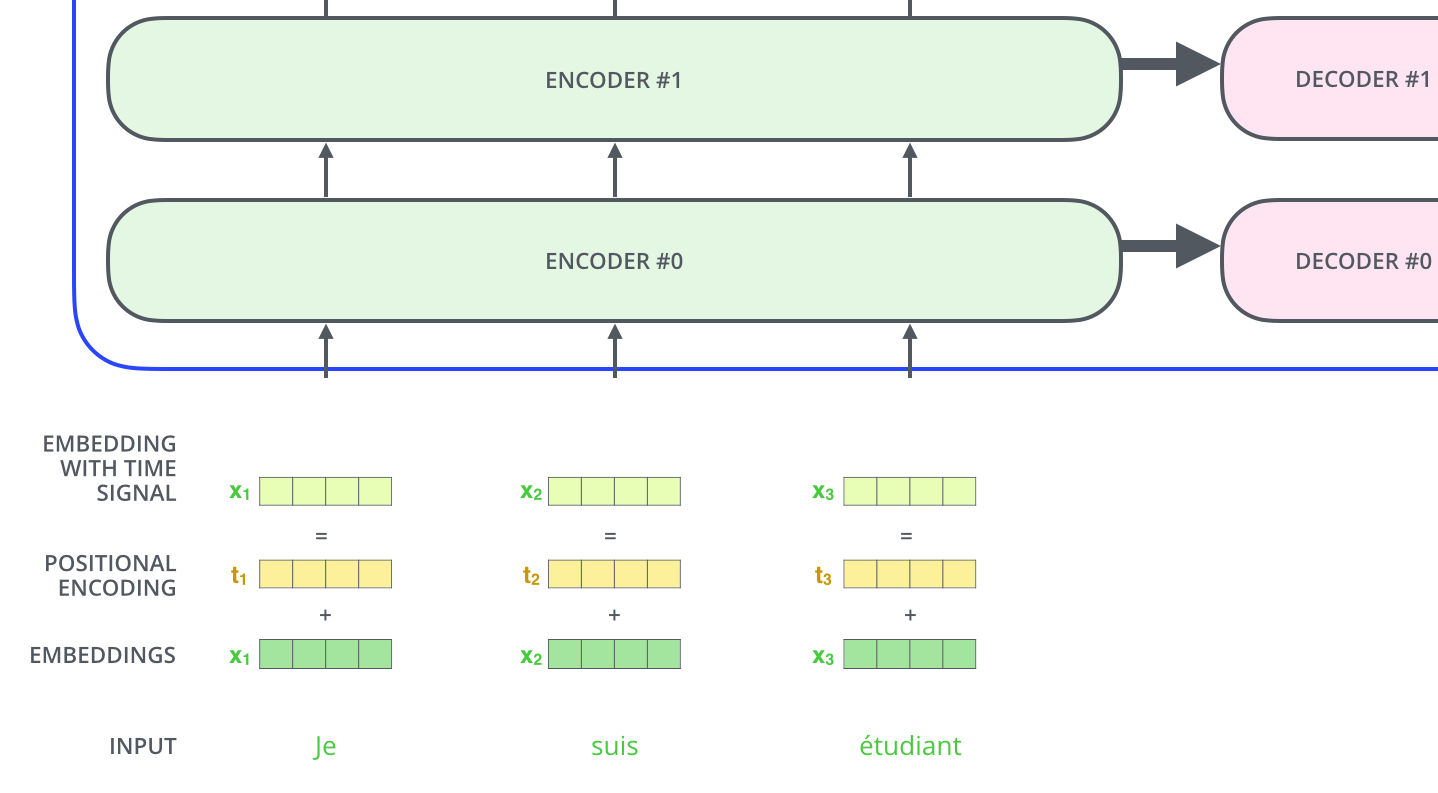
Position-embedding
上面模型没有考虑位置信息,Transformer增加了一个位置向量,该位置向量是通过也是通过模型学习到的,(怎么学习到的?!),所以 embedding = positional-embeding + embedding
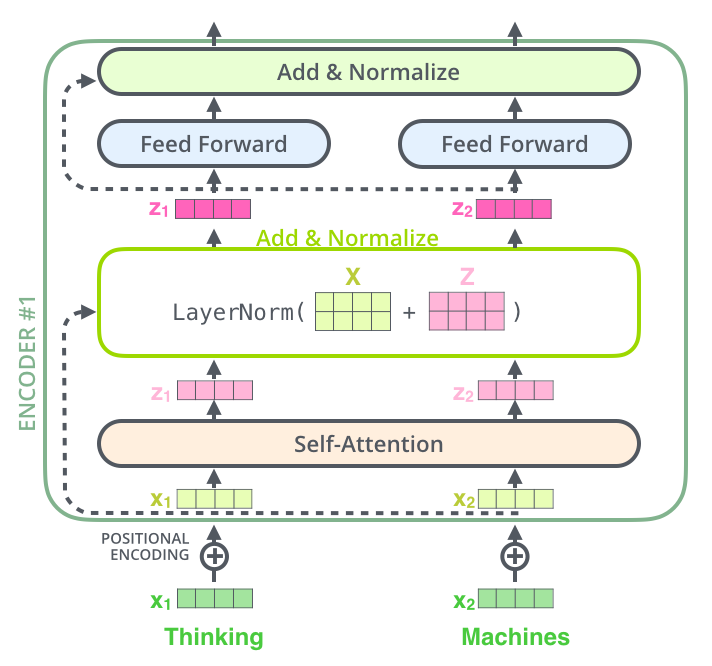
The Residuals
另外在 self-attention与FFNN之间还加入了 一个 residual connection,在这之后还有一个layer-normalization.
意义:为什么?!
对于一个2层的encoder-decoder,它们的架构如图所示:
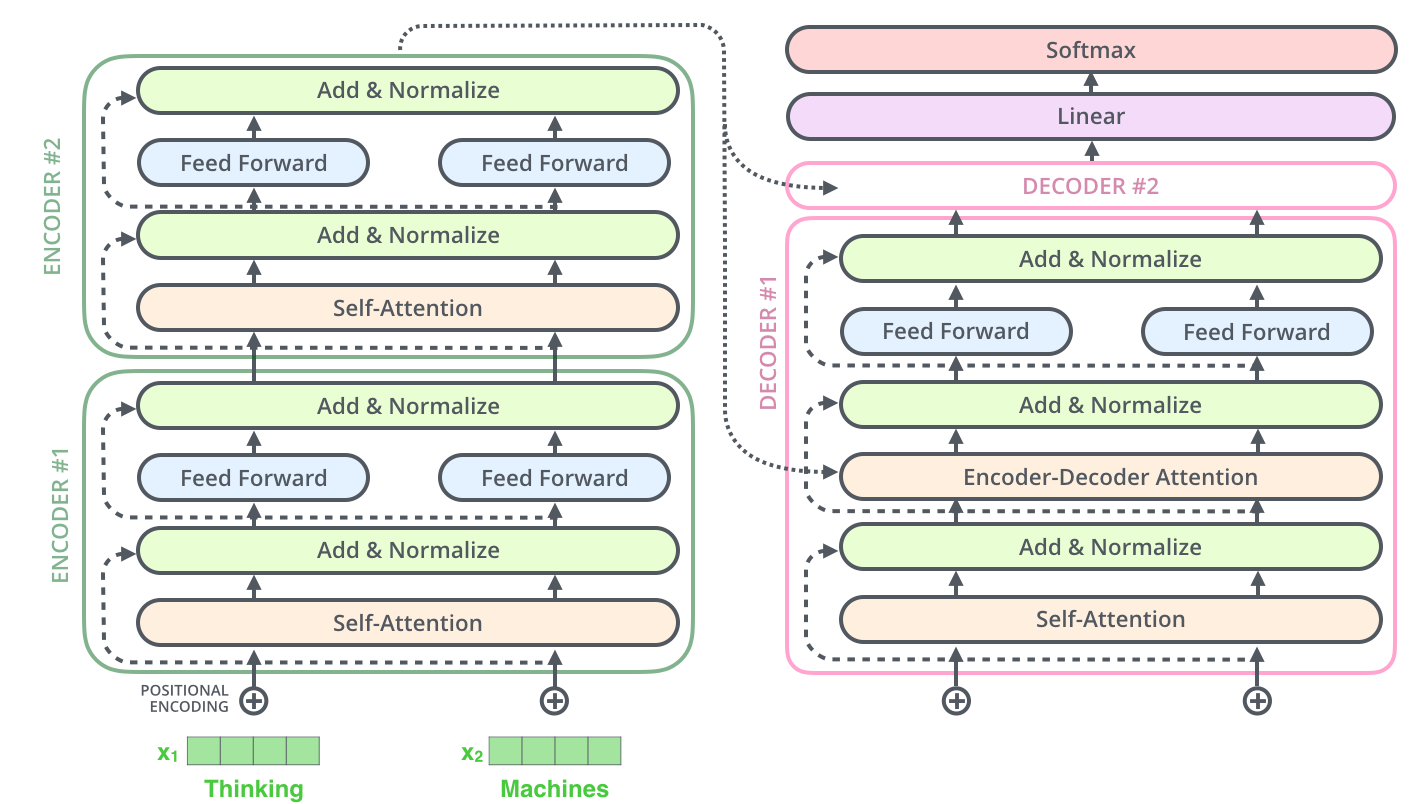
Decoder side
encoder最后一层的输出将被转化成 key, value向量,(怎么转化?!)这两个向量在 decoder中的encoder-decoder attention层共享。
decoder对于输入也和encoder一样加入位置编码,与encoder中selfattetion有些许区别,它只考虑该时间步之前的信息,
decoder中querry是怎样的呢?

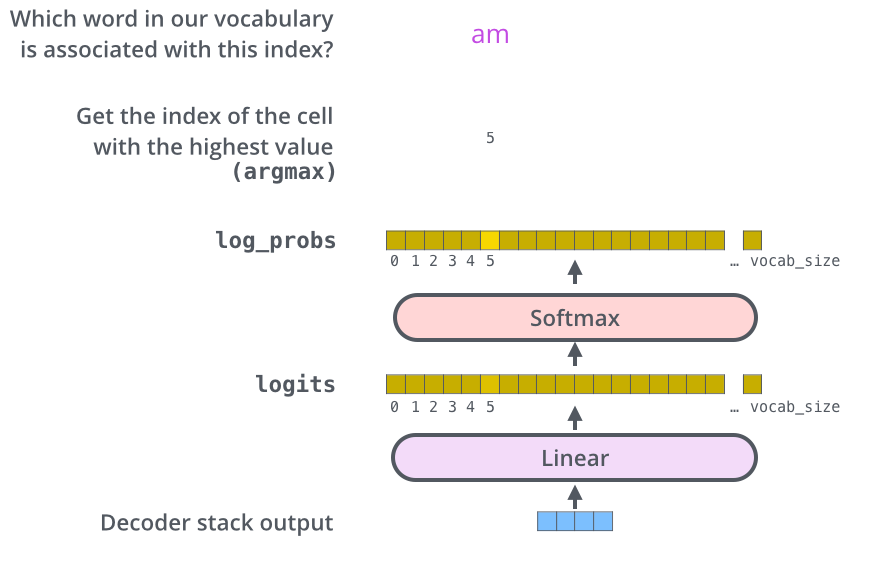
最后在加一个全连接层,softmax得到最后结果
参考:
https://jalammar.github.io/illustrated-transformer/
https://kexue.fm/archives/4765
Transformer【Attention is all you need】的更多相关文章
- 【英语魔法俱乐部——读书笔记】 3 高级句型-简化从句&倒装句(Reduced Clauses、Inverted Sentences) 【完结】
[英语魔法俱乐部——读书笔记] 3 高级句型-简化从句&倒装句(Reduced Clauses.Inverted Sentences):(3.1)从属从句简化的通则.(3.2)形容词从句简化. ...
- 【校招面试 之 C/C++】第17题 C 中的malloc相关
1.malloc (1)原型:extern void *malloc(unsigned int num_bytes); 头文件:#include <malloc.h> 或 #include ...
- 【Python五篇慢慢弹】快速上手学python
快速上手学python 作者:白宁超 2016年10月4日19:59:39 摘要:python语言俨然不算新技术,七八年前甚至更早已有很多人研习,只是没有现在流行罢了.之所以当下如此盛行,我想肯定是多 ...
- 【Python五篇慢慢弹】数据结构看python
数据结构看python 作者:白宁超 2016年10月9日14:04:47 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给出的pythondoc ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【ASP.NET程序员福利】打造一款人见人爱的ORM(二)
上一篇我已经给大家介绍AntORM的框架[ASP.NET程序员福利]打造一款人见人爱的ORM(一),今天就来着重介绍一下如何使用这套框架 1>AntORM 所有成员 如果你只想操作一种数据库,可 ...
随机推荐
- Linux使用nginx反向代理。可实现域名指向特定端口
在配置80指向域名的时候出现端口占用,使用kill -9无法杀死端口,应使用下面的命令来杀死进程killall -9 nginx(使用完本命令需要再把配置过的配置文件重新启动.命令写在了PS下面)后在 ...
- QT通过url下载图片到本地
/* strUrl:下载图片时需要的url strFilePath:下载图片的位置(/home/XXX/YYY.png) */ void ThorPromote::downloadFileFromUr ...
- Python使用Plotly绘图工具,绘制面积图
今天我们来讲一下如何使用Python使用Plotly绘图工具,绘制面积图 绘制面积图与绘制散点图和折线图的画法类似,使用plotly graph_objs 中的Scatter函数,不同之处在于面积图对 ...
- sql server REPLACE 替换文本中的回车和换行符
--替换回车符 REPLACE(exp, CHAR(13), '') --替换换行符 REPLACE(exp, CHAR(10), '') --水平制表符 REPLACE(exp, CHAR( ...
- JS中 confirm() 方法
前言 环境: window 10,google 浏览器 测试代码 <html> <!-- 测试确定框,如果点 "是" ,则返回 true,这样就触发 a 标签的 ...
- [转]Lua和Lua JIT及优化指南
一.什么是lua&luaJit lua(www.lua.org)其实就是为了嵌入其它应用程序而开发的一个脚本语言, luajit(www.luajit.org)是lua的一个Just-In-T ...
- maven-3.5.3通过eclipse打包问题(1)
1.maven版本:3.5.3 2.ide: Eclipse Oxygen.2 (4.7.2)(Version: 3.9.2.RELEASE) 3. 配置ide 错误原因: 解决方法以及运行结果:
- Excel自定义公式,类似VLOOKUP的查询
Excel在使用VLOOKUP时,当检索值超过255长度的时候就会报错,没法正常检索. 官方提供的办法是通过INDEX和MATCH公式组合使用来解决. 微软官方方案 1,公式 =INDEX($A$5: ...
- windows下为qt msvc版本配置调试器
原文:https://blog.csdn.net/whatnamecaniuse/article/details/80716616 根据开发机的环境,下载 我的机器是win10,因此下载win 10 ...
- RocketMQ三主三从二命名服务平滑版本升级实操
本文介绍本次进行RocketMQ平滑过渡升级的实际操作 前文已经介绍过了升级基本原理,主要思想就是先升级NameSrv(命名服务)然后在升级broker节点.broker节点先升级master节点然 ...