Transformer【Attention is all you need】
前言
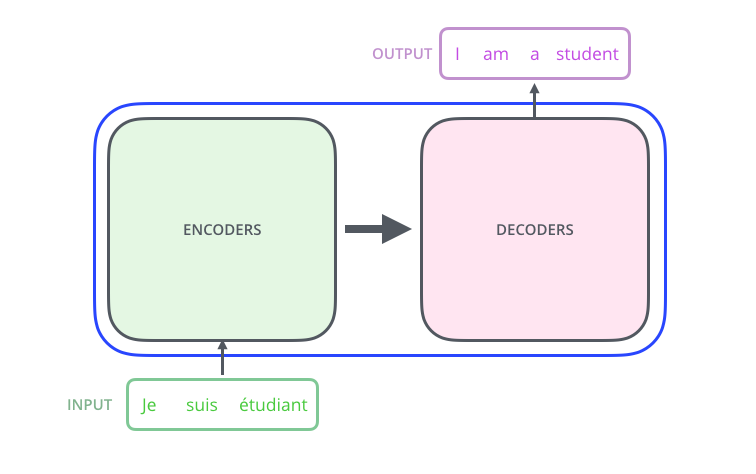
Transfomer是一种encoder-decoder模型,在机器翻译领域主要就是通过encoder-decoder即seq2seq,将源语言(x1, x2 ... xn) 通过编码,再解码的方式映射成(y1, y2 ... ym), 之前的做法是用RNN进行encode-decoder,但是由于RNN在某一时间刻的输入是依赖于上一时间刻的输出,所以RNN不能并行处理,导致效率低效,而Transfomer就避开了RNN,因此encoder-decoder效率高。
Transformer
从一个高的角度来看Transformer,它就是将源语言 转换 成目标语言

打开Transformer单元,我们会发现有两个部分组成,分别是encoders单元和decoders单元
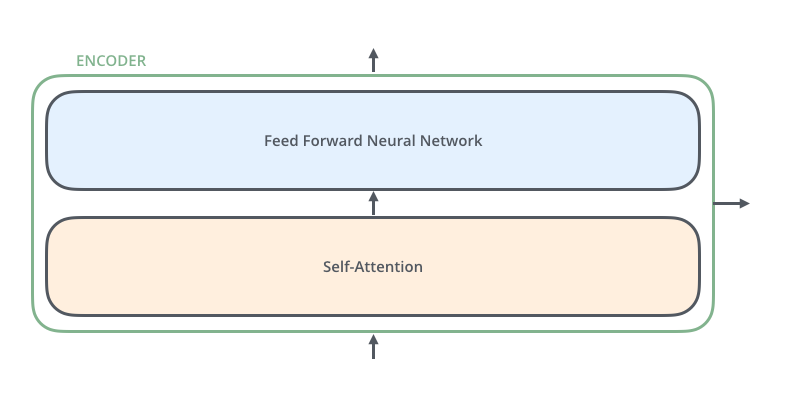
而对于encoders单元,它是由六个encoder组成的,同样decoders单元,它也是由六个decoders组成。

对于每一个encoder,它们结构都一样的,但是权重不共享,每一个encoder的结构都是由两部分组成,分别是self-attention和feed forward neural network。
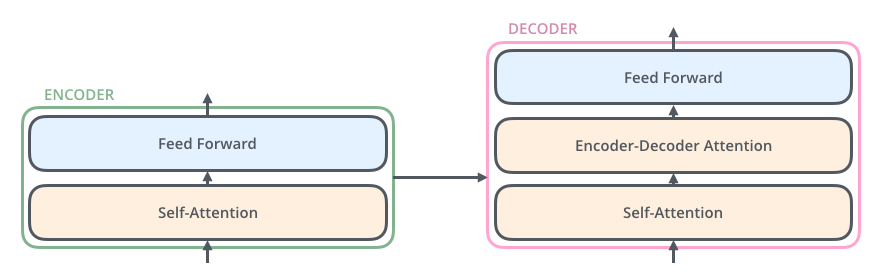
Transformer的处理流程是这样的:输入数据传给self-attention,然后selft-attention计算每一个位置的与其他位置的相关性,从而获得每一个位置的输出结果,该输出结果传给FFNN,得到第一个encoder的输出z1,z1作为第二个encoder的输入,步骤如上,直到最后一个encoder输出 ouput。
该输出ouput,在传给decoder,大致过程和encoder一致,有些许差异,稍后分析。
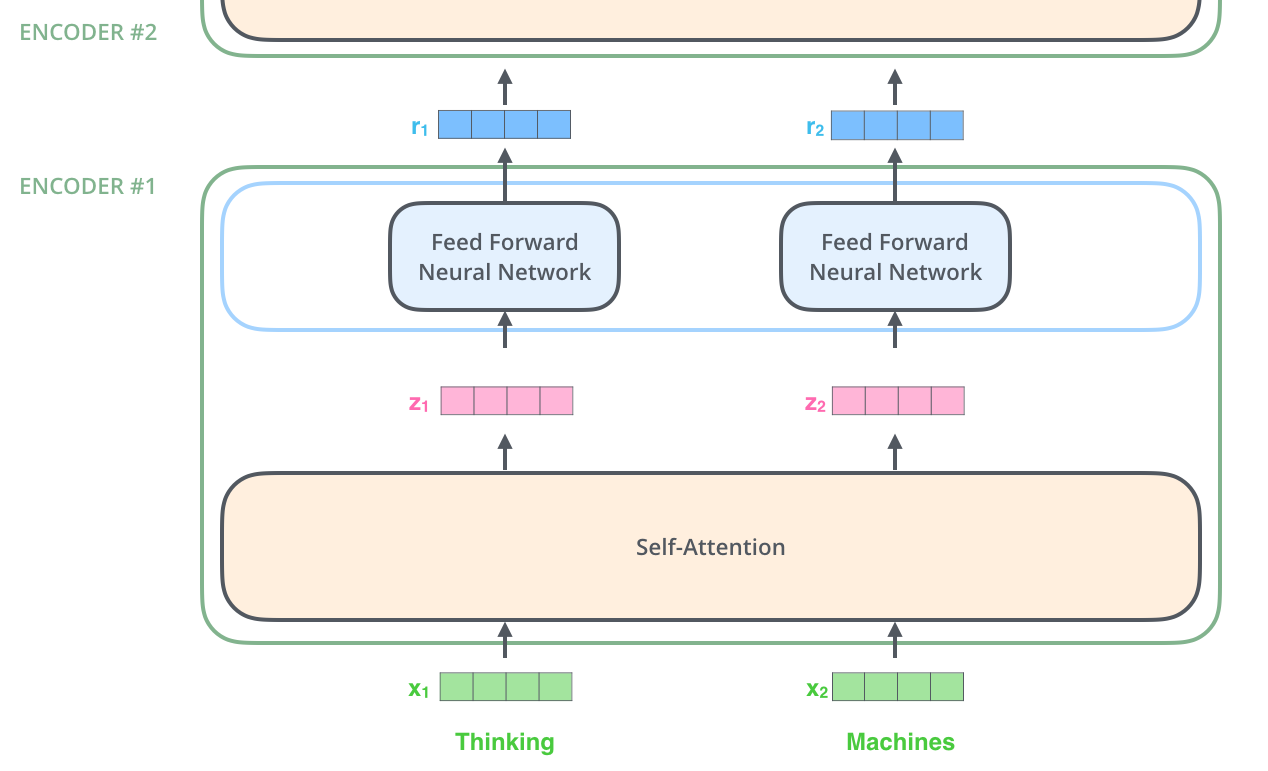
具体示例:
假设输入的是两个单词:Thinking Machine, 首先对单词作embedding,然后作为第一个encoder的输入,在第一个encoder里面经过self-attention,得到zi,然后zi经过FFNN得到第一个encoder的输出ri,然后ri像embedding一样,作为第二个encoder的输入
self-attention
selft-attention的作用就是求 某一位置与其他位置的相关性权重。
selft-attention执行流程:
第一步:
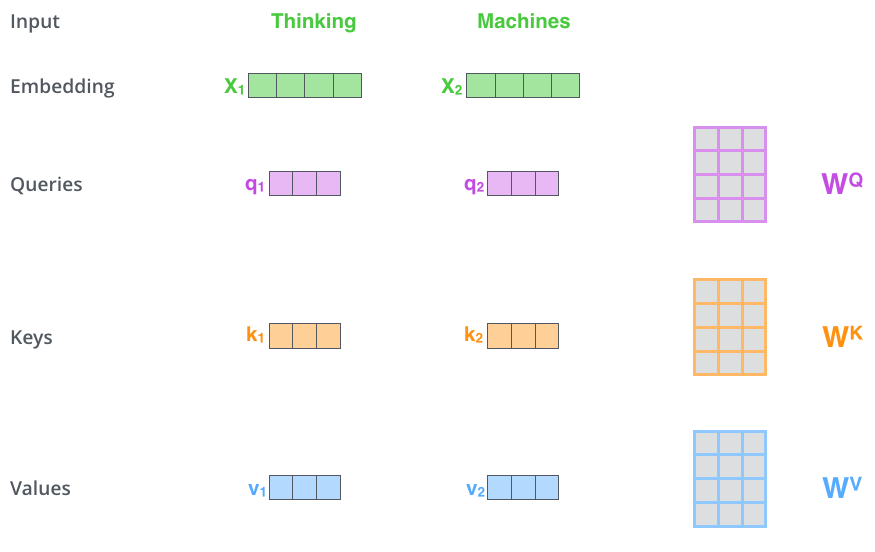
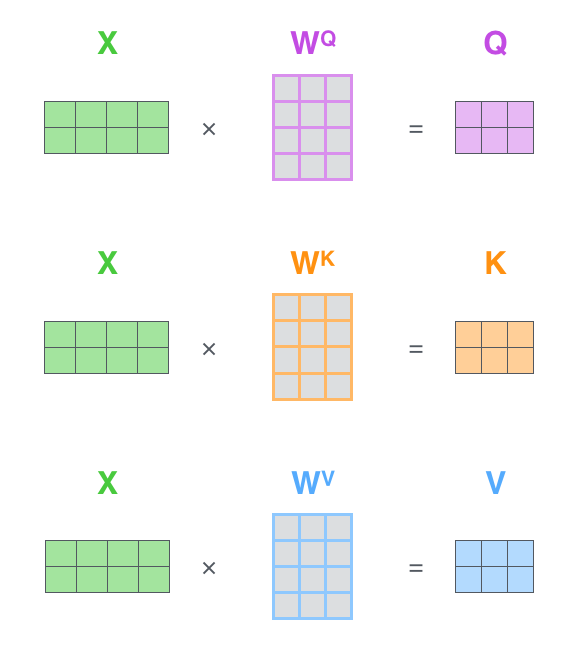
输入向量 embedding分别与三个权重矩阵(WQ WK ,WV)相乘,得到三个向量, Queries, Keys, Values。据说三个权重矩阵(WQ WK ,WV)是在训练过程中获得的,我很好奇它是怎么训练获得的。
还有就是 Queries, Keys, Values这三个向量的维度要比 embedding的维度小, Queries, Keys, Values的维度是64, embedding的维度是512。至于为什么要小,是为了便于multi-head计算
第二步:
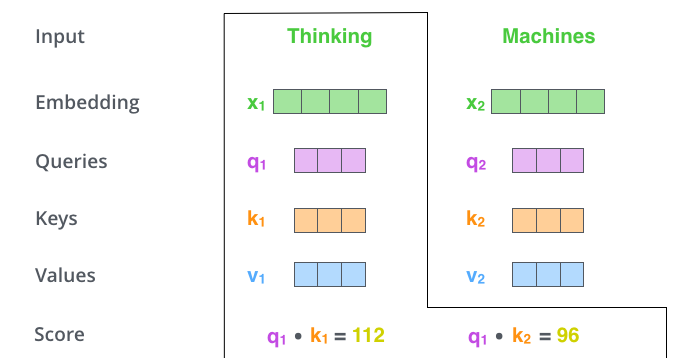
计算每一个位置与其他位置的得分。
如图,以第一个单词Thinking为例,用q1分别与不同位置的keys向量ki进行点积,得到与每其他位置的得分。
第三步
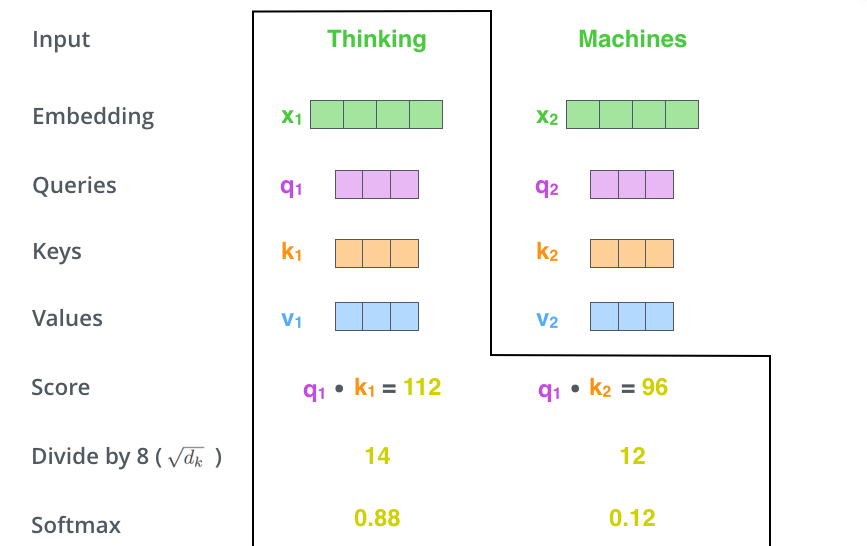
将得分 除以 8, keys的维度平方根,paper是64。
第四步
对得分进行sotfmax
第五步:
用softmax的得分(权重) 乘以 对应位置的values向量,
第六步:
对加权values向量求和
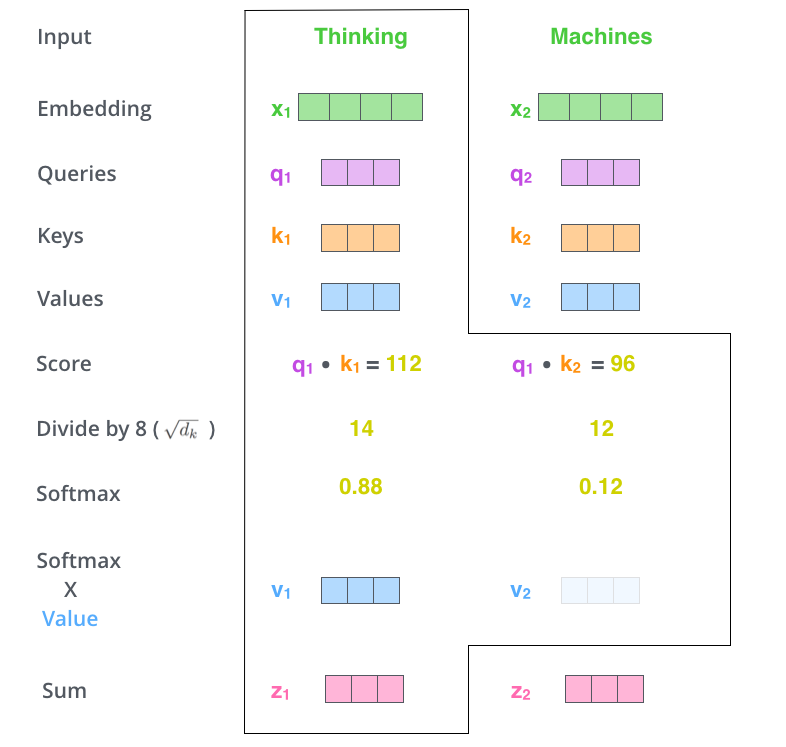
以上是对于一个单词的运算过程,可以用矩阵对整个输入序列进行操作
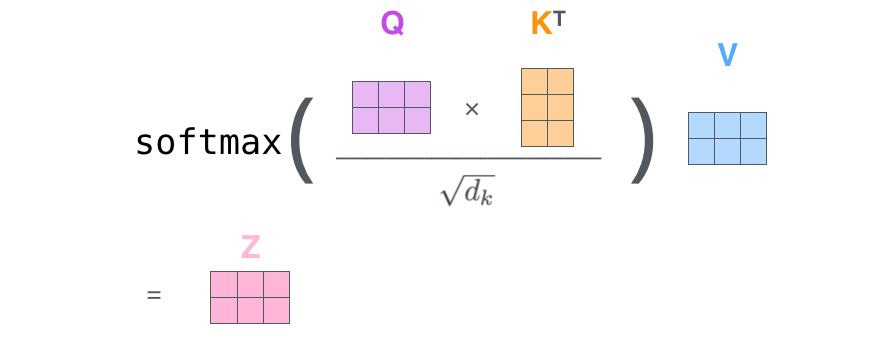
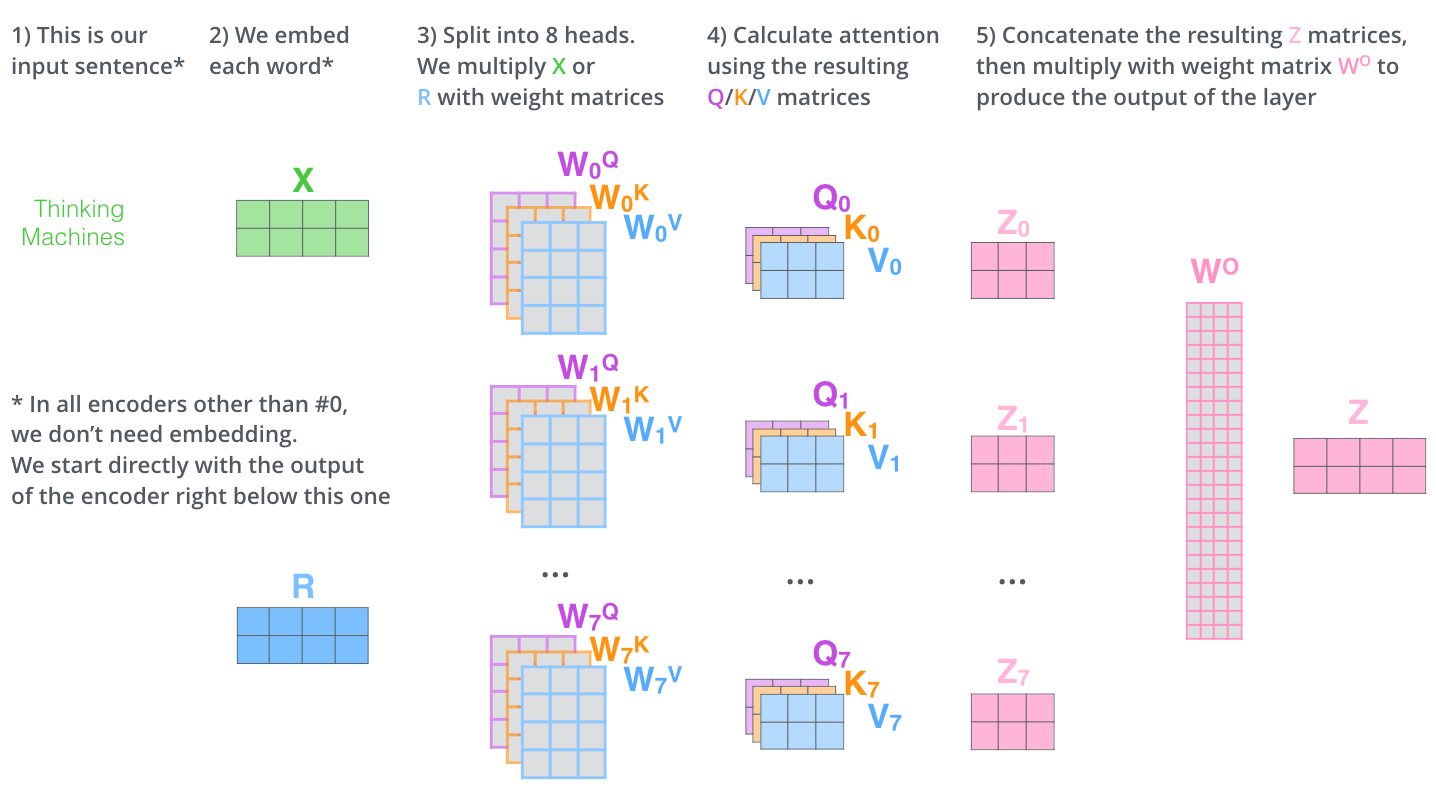
优化Multi-head
motivation:
1、对于上面的计算过程,最后的到z1仅包含与他相关的那些位置的信息,而其他位置信息就包含的较少,Multi-headed可以覆盖到每一个位置的信息 (不太理解,不就是要找到最相关的位置吗, 为什么要其他的都包含呢)
2、它为attention层提供了更多的表示空间。在上面的计算过程中,都产生了一个 Queries,Keys, Values的权重矩阵,Transformer使用了八个head,每一个head相当于一个独立的子空间,在这里将随机初始化 Queries,Keys, Values的权重矩阵,所以最终会有八个权重矩阵,也就是会有八个 Queries,Keys, Values向量。
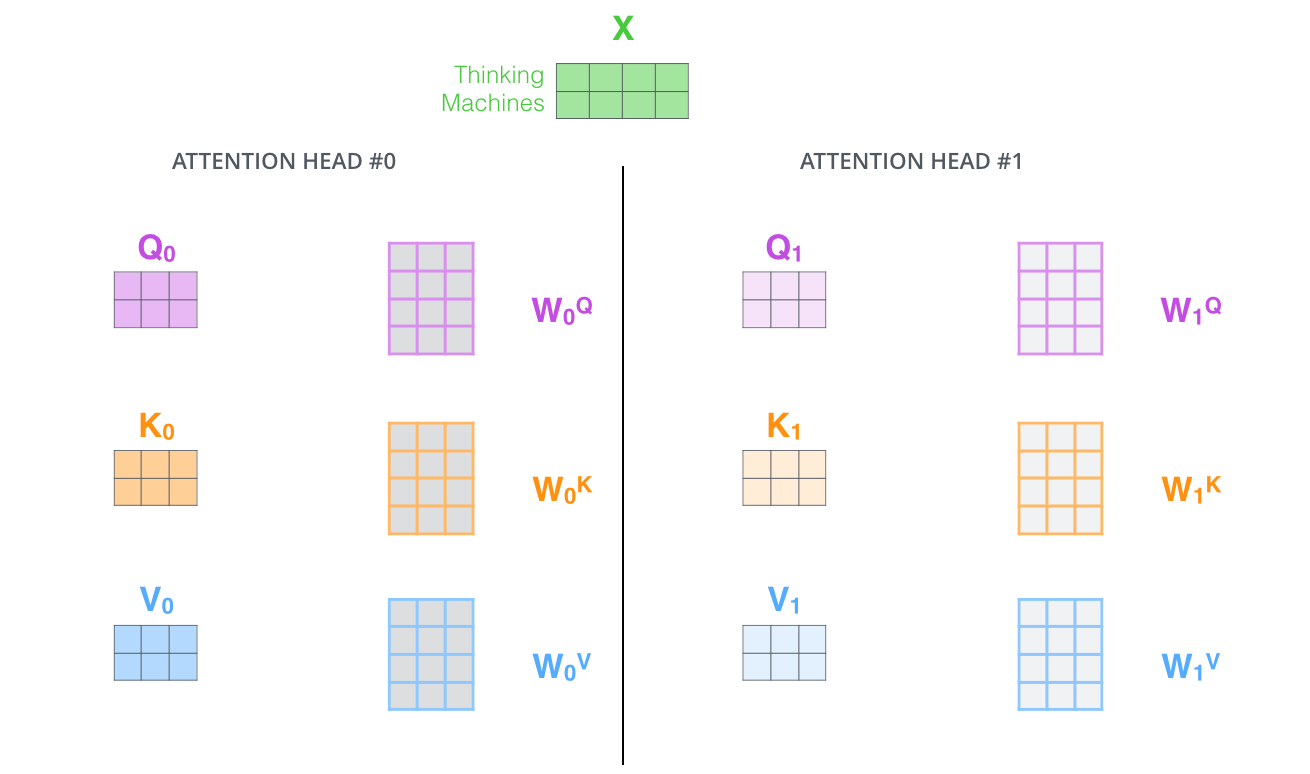
与之前一样的计算方式,embeding需要与每一个head进行计算,最后会有八个输出
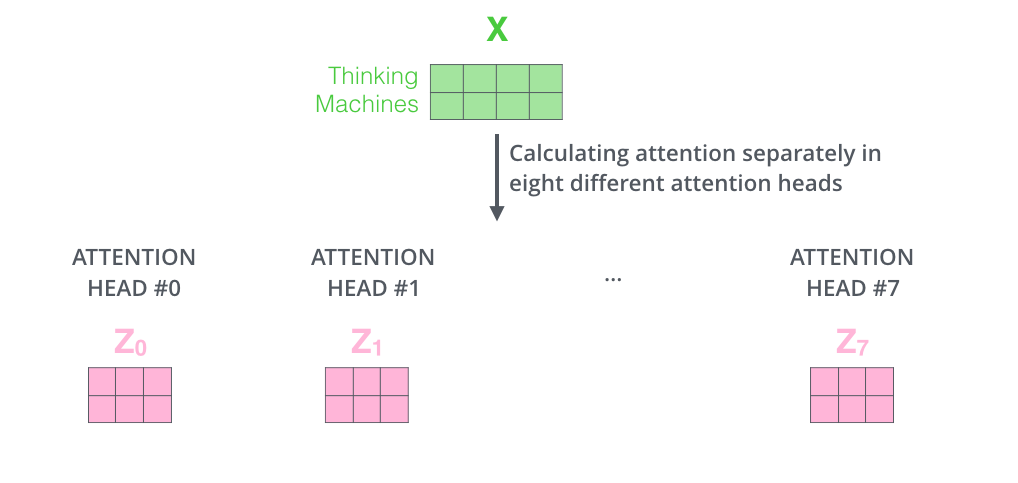
然后八个输出拼接成一个向量,乘以 另一个权重矩阵Wo (怎么得到的?)得到最后的输出Z

multi-headed的整体过程如下:
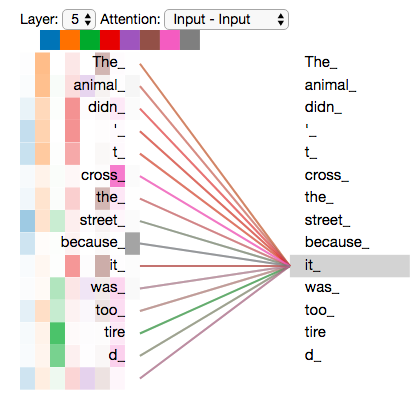
multi-headed与single-headed的效果:
single-headed只关注与他最相关的,也就是权重最大的,如左图。而Multi-headed会关注好的内容,如右图

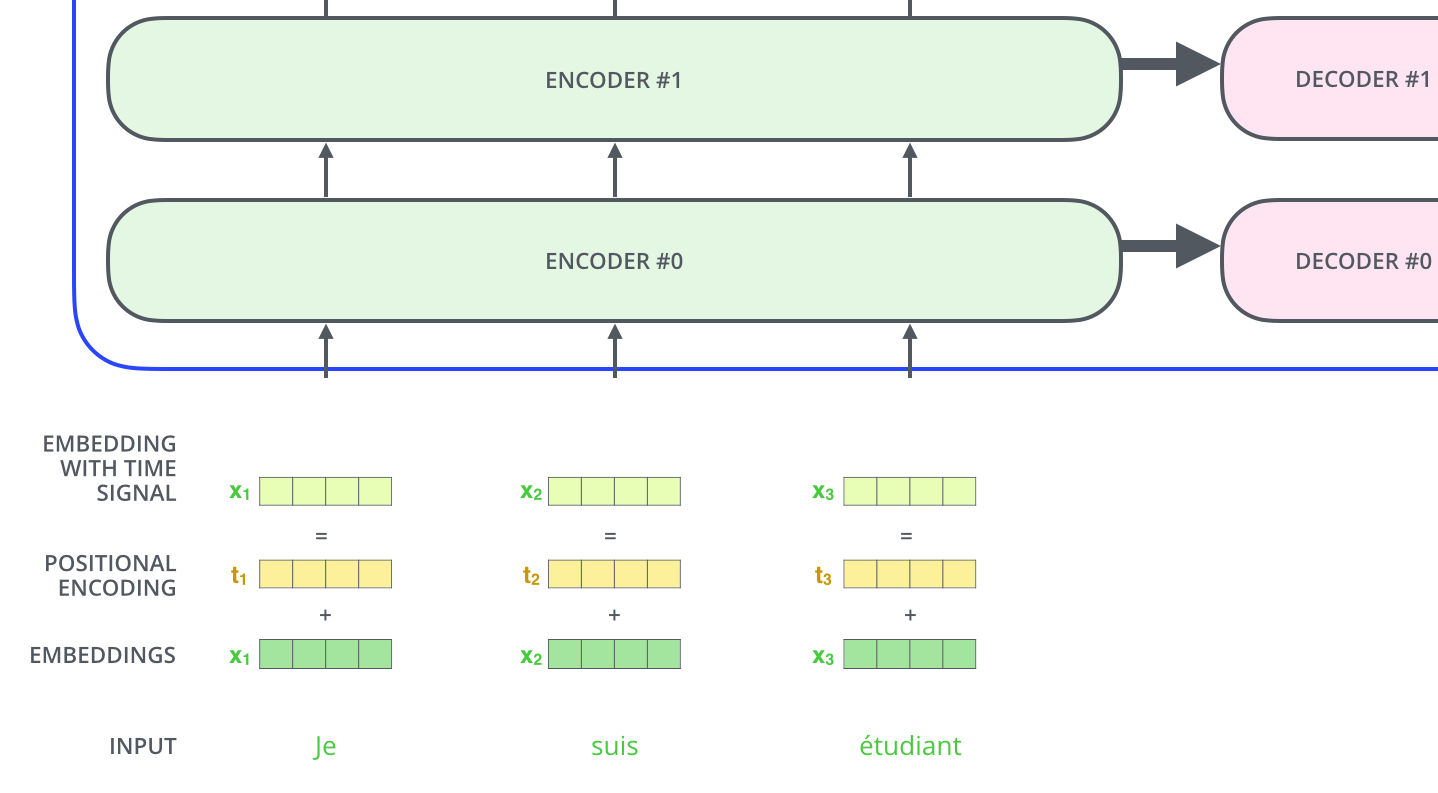
Position-embedding
上面模型没有考虑位置信息,Transformer增加了一个位置向量,该位置向量是通过也是通过模型学习到的,(怎么学习到的?!),所以 embedding = positional-embeding + embedding
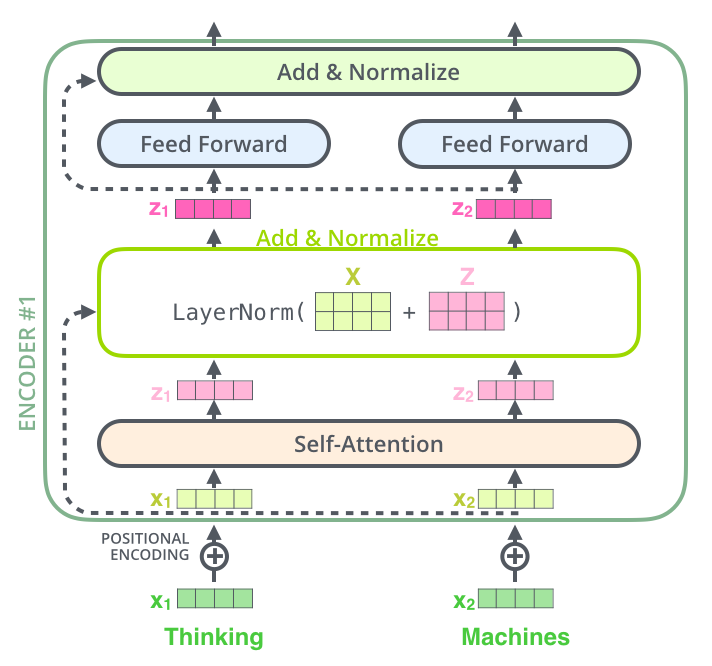
The Residuals
另外在 self-attention与FFNN之间还加入了 一个 residual connection,在这之后还有一个layer-normalization.
意义:为什么?!
对于一个2层的encoder-decoder,它们的架构如图所示:
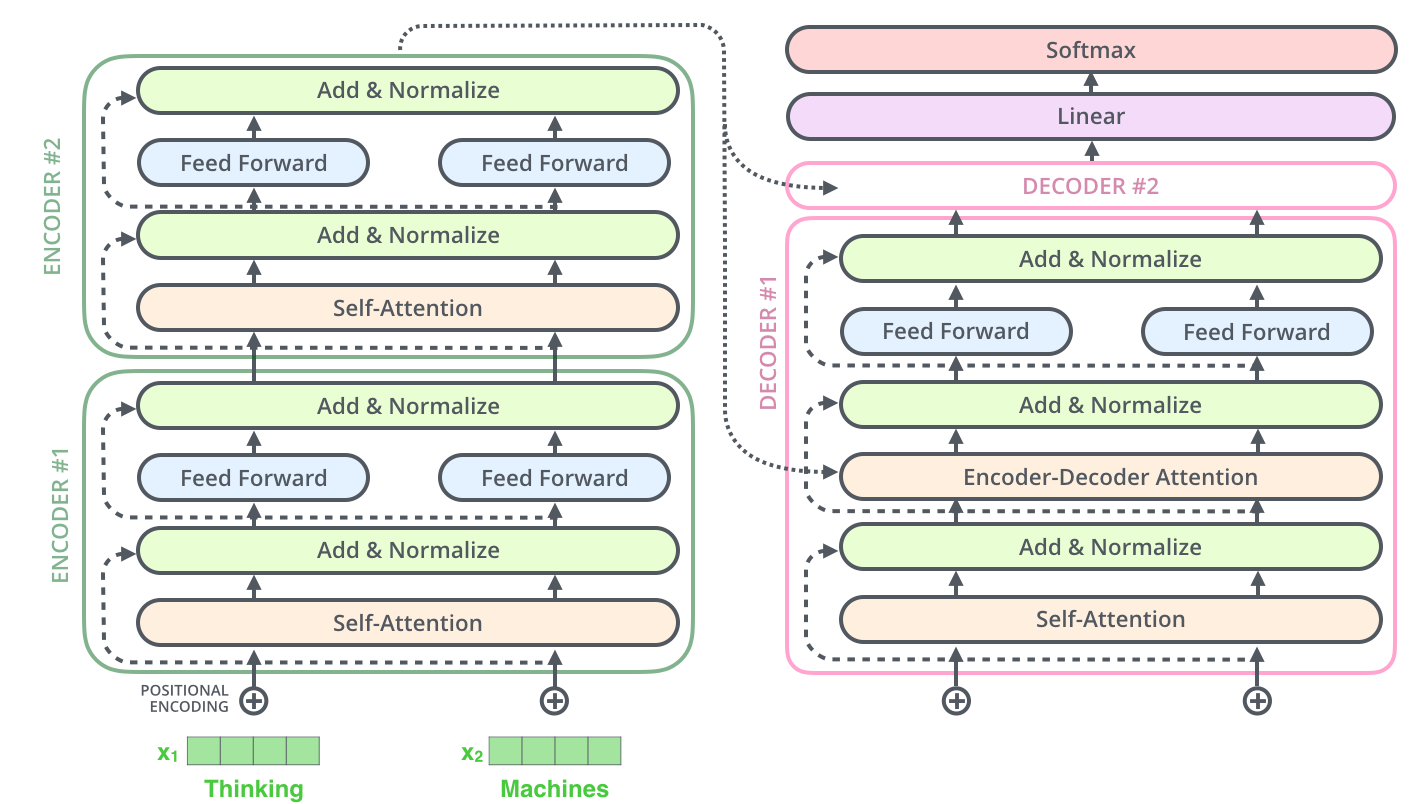
Decoder side
encoder最后一层的输出将被转化成 key, value向量,(怎么转化?!)这两个向量在 decoder中的encoder-decoder attention层共享。
decoder对于输入也和encoder一样加入位置编码,与encoder中selfattetion有些许区别,它只考虑该时间步之前的信息,
decoder中querry是怎样的呢?

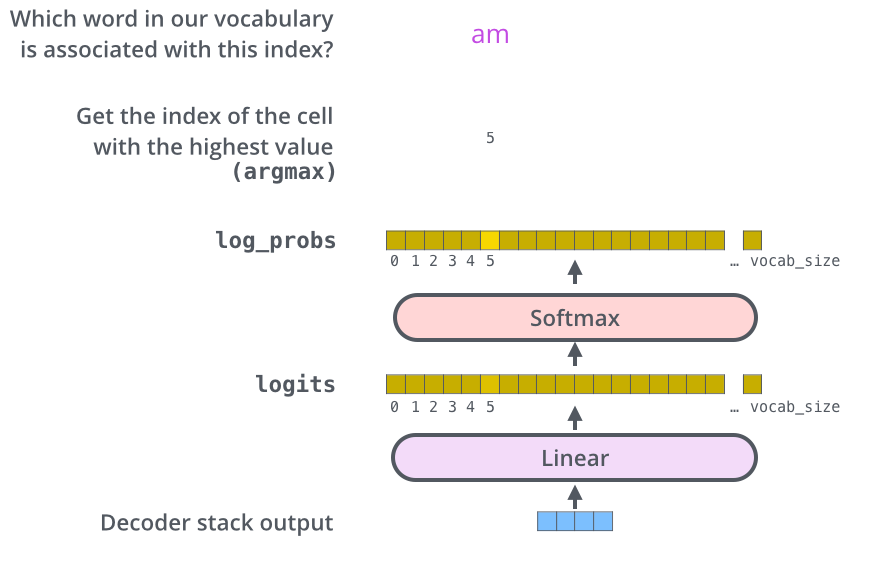
最后在加一个全连接层,softmax得到最后结果
参考:
https://jalammar.github.io/illustrated-transformer/
https://kexue.fm/archives/4765
Transformer【Attention is all you need】的更多相关文章
- 【英语魔法俱乐部——读书笔记】 3 高级句型-简化从句&倒装句(Reduced Clauses、Inverted Sentences) 【完结】
[英语魔法俱乐部——读书笔记] 3 高级句型-简化从句&倒装句(Reduced Clauses.Inverted Sentences):(3.1)从属从句简化的通则.(3.2)形容词从句简化. ...
- 【校招面试 之 C/C++】第17题 C 中的malloc相关
1.malloc (1)原型:extern void *malloc(unsigned int num_bytes); 头文件:#include <malloc.h> 或 #include ...
- 【Python五篇慢慢弹】快速上手学python
快速上手学python 作者:白宁超 2016年10月4日19:59:39 摘要:python语言俨然不算新技术,七八年前甚至更早已有很多人研习,只是没有现在流行罢了.之所以当下如此盛行,我想肯定是多 ...
- 【Python五篇慢慢弹】数据结构看python
数据结构看python 作者:白宁超 2016年10月9日14:04:47 摘要:继<快速上手学python>一文之后,笔者又将python官方文档认真学习下.官方给出的pythondoc ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【ASP.NET程序员福利】打造一款人见人爱的ORM(二)
上一篇我已经给大家介绍AntORM的框架[ASP.NET程序员福利]打造一款人见人爱的ORM(一),今天就来着重介绍一下如何使用这套框架 1>AntORM 所有成员 如果你只想操作一种数据库,可 ...
随机推荐
- Dynamics 365-关于Solution的那些事(二)
接着上一篇的说,现在有一个已知前提:Solution的增量特性.然后我们再思考这么一个场景,项目开发过程中,存在多次迭代的情况,每次迭代可能涉及到的solution是同一个,唯一区别的,就是solut ...
- OpenCL中三种内存创建image的效率对比
第一种:使用ION: cl_mem_ion_host_ptr ion_host_ptr1; ion_host_ptr1.ext_host_ptr.allocation_type = CL_MEM_IO ...
- 3Delight NSI: A Streamable Render API
3Delight是应用于高端电影级别渲染的软件渲染器,迄今为止已经参与了无数的电影制作,具体可以参见链接. 如果你对3Delight的印象就依然是RenderMan的替代品,那就显然已经和时代发展脱节 ...
- linux 子系统折腾记 (三)
所以说,英文真是个好东西,很多资料都只有英文版本,要是不懂英文,甚至你不知道这个资料的存在,更别提用蹩脚的翻译软件去翻译了. wsl 的资料:https://docs.microsoft.com/zh ...
- [20190418]exclusive latch spin count.txt
[20190418]exclusive latch spin count.txt--//昨天测试"process allocation" latch,主要这个latch与其它拴锁s ...
- C# -- 使用 Task 执行多线程任务
C# -- 使用 Task 执行多线程任务 1. 使用 Task 执行多线程任务 class Program { static void Main(string[] args) { Task task ...
- linux的常用命令介绍
1.ls 列出当前目录下的所有的文件和文件夹的名称. 参数如下:-a 显示隐藏文件 -l 显示方式为列表 -h 以可读性高的方式输出 eg: ls -lh /logs/tran 目录如果不指定(相 ...
- java 浅复制 代码
1 类实现Cloneable接口 2 重写clone()方法 3 类变量引用类型无法复制 class Dog extends Pet implements Cloneable{ int c; i ...
- 不停服务,动态加载properties资源文件
系统运行过程中,我们用注解@Value("${****}")可以获取资源文件中的内 容,获取的内容会被存储在spring缓存中,因此如果我们修改了资源文件,要 想读取到修改后的内容 ...
- 通过 docker 搭建自用的 gitlab 服务
前言 git 是当下如日中天的版本管理系统.现在如果不是工作在 git 版本管理系统之下,几乎都不好意思和人打招呼了.有很多现成的互联网的 git 服务提供给大家使用,例如号称程序员社交网络的 Git ...