prometheus 集群
思路一
统一区域的监控目标,prometheus server两台监控相同的目标群体。

改变后

上面这个变化对于监控目标端,会多出一倍的查询请求,但在一台prometheus server宕机的情况下,可以不影响监控。
思路二
这是一个金字塔式的层次结构,而不是分布式层次结构。Prometheus 的抓取请求也会加载到prometheus work节点上,这是需要考虑的。
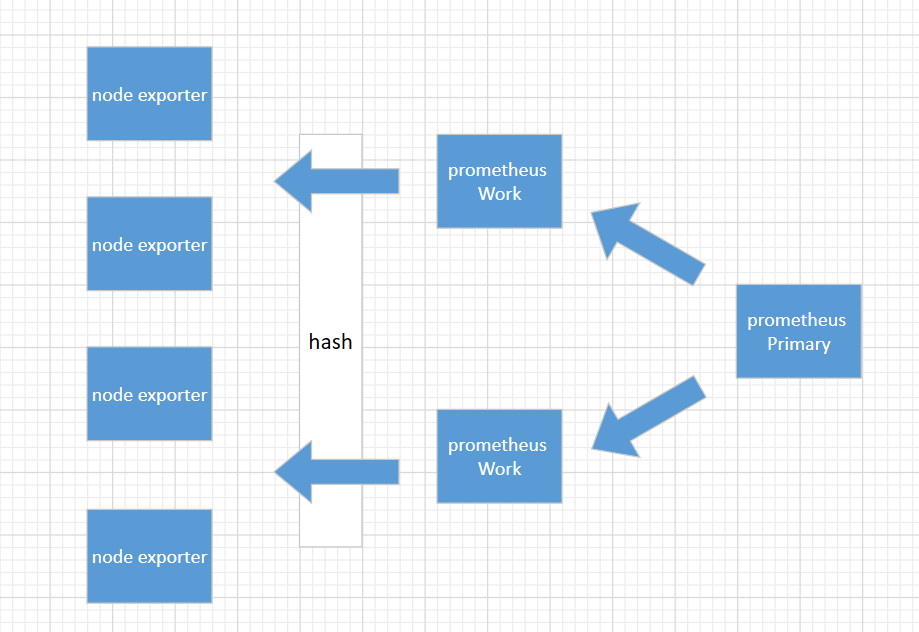
上面这种模式,准备3台prometheus server进行搭建,这种方式work节点一台宕机后,其它wokr节点不会去接手故障work节点的机器。
1、环境准备
192.168.31.151(primary)
192.168.31.144 (worker)
192.168.31.82(worker)
2、部署prometheus
cd /usr/loacl
tar -xvf prometheus-2.8.0.linux-amd64.tar.gz
ln -s /usr/local/prometheus-2.8.0.linux-amd64 /usr/local/prometheus
cd /usr/local/prometheus;mkdir bin conf data
mv ./promtool bin
mv ./prometheus bin
mv ./prometheus.yml conf
3、worker节点配置(192.168.31.144)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
worker: 0 # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets:
- 192.168.31.151:9090
- 192.168.31.144:9090
- 192.168.31.82:9090
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'docker'
file_sd_configs:
- files:
- targets/docker/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
- job_name: 'alertmanager'
static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^0$
action: keep
worker节点配置(192.168.31.82)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
external_labels:
worker: 1 # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_rules.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
static_configs:
- targets:
- 192.168.31.151:9090
- 192.168.31.144:9090
- 192.168.31.82:9090
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'node_exporter'
file_sd_configs:
- files:
- targets/nodes/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'docker'
file_sd_configs:
- files:
- targets/docker/*.json
refresh_interval: 1m
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
- job_name: 'alertmanager'
static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093
relabel_configs:
- source_labels: [__address__]
modulus: 2
target_label: __tmp_hash
action: hashmod
- source_labels: [__tmp_hash]
regex: ^1$
action: keep
primary节点配置(192.168.31.151)
prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s). # Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.31.151:9093
- 192.168.31.144:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_alerts.yml" # A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
- job_name: 'node_workers'
file_sd_configs:
- files:
- 'targets/workers/*.json'
refresh_interval: 5m
honor_labels: true
metrics_path: /federate
params:
'match[]':
- '{__name__=~"^instance:.*"}'
cat ./targets/workers/workers.json
[{
"targets": [
"192.168.31.144:9090",
"192.168.31.82:9090"
]
}]
prometheus 集群的更多相关文章
- Prometheus集群介绍-1
Prometheus监控介绍 公司做教育的,要迁移上云,所以需要我这边从零开始调研加后期维护Prometheus:近期看过二本方面的prometheus书籍,一本是深入浅出一般是实战方向的:官方文档主 ...
- Thanos prometheus 集群以及多租户解决方案docker-compose 试用(一)
prometheus 是一个非常不多的metrics 监控解决方案,但是对于ha 以及多租户的处理并不是很好,当前有好多解决方案 cortex Thanos prometheus+ influxdb ...
- 部署prometheus监控kubernetes集群并存储到ceph
简介 Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目. ...
- 如何扩展单个Prometheus实现近万Kubernetes集群监控?
引言 TKE团队负责公有云,私有云场景下近万个集群,数百万核节点的运维管理工作.为了监控规模如此庞大的集群联邦,TKE团队在原生Prometheus的基础上进行了大量探索与改进,研发出一套可扩展,高可 ...
- 如何用Prometheus监控十万container的Kubernetes集群
概述 不久前,我们在文章<如何扩展单个Prometheus实现近万Kubernetes集群监控?>中详细介绍了TKE团队大规模Kubernetes联邦监控系统Kvass的演进过程,其中介绍 ...
- vivo 容器集群监控系统架构与实践
vivo 互联网服务器团队-YuanPeng 一.概述 从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实 ...
- 如何使用helm优雅安装prometheus-operator,并监控k8s集群微服务
前言:随着云原生概念盛行,对于容器.服务.节点以及集群的监控变得越来越重要.Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态.但是它不支持分布式,不支持数据 ...
- Kubernetes集群部署史上最详细(二)Prometheus监控Kubernetes集群
使用Prometheus监控Kubernetes集群 监控方面Grafana采用YUM安装通过服务形式运行,部署在Master上,而Prometheus则通过POD运行,Grafana通过使用Prom ...
- Prometheus监控elasticsearch集群(以elasticsearch-6.4.2版本为例)
部署elasticsearch集群,配置文件可"浓缩"为以下: cluster.name: es_cluster node.name: node1 path.data: /app/ ...
随机推荐
- PostGIS计算矢量切片(二)--按值渲染
方案背景 今年三月份写了一篇postgis计算矢量切片,参考了网上资料给出了一份很粗糙的相关方案(文章写的更粗糙).当时的方案中只能针对gis形状进行渲染,而不能用属性渲染.针对这个情况,本文 ...
- Fragment生命周期以及使用时的小问题
前言- 昨天在写UI的时候用到了FRAGMENT,发现自己对此还不是非常了解,借此机会记录一下 Fragment的生命周期- 官方生命周期图: Fragment每个生命周期方法的意义.作用- onVi ...
- 卸载windows补丁
wusa /uninstall /kb: wusa /uninstall /kb: 和某些应用软件冲突时,需要将上述补丁卸载.
- 使用Linq的过程中碰到的问题
1. 在使用linq过程DefaultIfEmpty的过程中如果 O.RS 这个支段的值是null,在取这个数据 就会报错 ,正确的写法 2. 在使用Linq 用where条件判断要好分辨大小写 3. ...
- WDS和DHCP配置说明
网络启动程序 (NBP) 是网络启动过程中第一个下载和执行的文件,它可以控制启动开始时的体验(例如,用户是否必须按 F12 才能开始网络启动) WDS服务器配置说明: 1)如果WDS和DHCP安装在同 ...
- 用css 添加手状样式,鼠标移上去变小手,变小手
用css 添加手状样式,鼠标移上去变小手,变小手 cursor:pointer; 用JS使鼠标变小手onmouseover(鼠标越过的时候) onmouseover="this.style. ...
- [ gczdac ] HDU1000
地址:http://acm.hdu.edu.cn/showproblem.php?pid=1000 Problem Description Calculate A + B. Input Eac ...
- HashMap源码分析(二)
前言:上篇文章,笔者分析了jdk1.7中HashMap的源码,这里将对jdk1.8的HashMap的源码进行分析. 注:jdk版本:jdk1.8.0_172 1.再看put操作 public V pu ...
- [LeetCode] 24. 两两交换链表中的节点
题目链接:https://leetcode-cn.com/problems/swap-nodes-in-pairs/ 题目描述: 给定一个链表,两两交换其中相邻的节点,并返回交换后的链表. 你不能只是 ...
- redis5.0.4多实例安装
一.安装第一个实例 https://www.cnblogs.com/qq931399960/p/10584877.html 二.拷贝配置文件 cp /etc/redis.conf /etc/redis ...