elasticsearch视频
简单的集群管理
(1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488006741 15:12:21 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007113 15:18:33 elasticsearch green 2 2 2 1 0 0 0 0 - 100.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007216 15:20:16 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
(2)快速查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
(3)简单的索引操作
创建索引:PUT /test_index?pretty
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test_index XmS9DTAtSkSZSwWhhGEKkQ 5 1 0 0 650b 650b
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
删除索引:DELETE /test_index?pretty
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
商品的CRUD操作
(1)新增商品:新增文档,建立索引
PUT /index/type/id
{
"json数据"
}
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
PUT /ecommerce/product/2
{
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
}
PUT /ecommerce/product/3
{
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
}
es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索
(2)查询商品:检索文档
GET /index/type/id
GET /ecommerce/product/1
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
}
(3)修改商品:替换文档
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao"
}
替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改
(4)修改商品:更新文档
POST /ecommerce/product/1/_update
{
"doc": {
"name": "jiaqiangban gaolujie yagao"
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
(5)删除商品:删除文档
DELETE /ecommerce/product/1
{
"found": true,
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 9,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"found": false
}
多种搜索方式:
1、query string search
2、query DSL
3、query filter
4、full-text search
5、phrase search
6、highlight search
---------------------------------------------------------------------------------------------------------------------------------
把英文翻译成中文,让我觉得很别扭,term,词项
1、query string search
搜索全部商品:GET /ecommerce/product/_search
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 1,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": [
"qingxin"
]
}
}
]
}
}
query string search的由来,因为search参数都是以http请求的query string来附带的
搜索商品名称中包含yagao的商品,而且按照售价降序排序:GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
适用于临时的在命令行使用一些工具,比如curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的
在生产环境中,几乎很少使用query string search
---------------------------------------------------------------------------------------------------------------------------------
2、query DSL
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了
查询所有的商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} }
}
查询名称包含yagao的商品,同时按照价格降序排序
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" : "yagao"
}
},
"sort": [
{ "price": "desc" }
]
}
分页查询商品,总共3条商品,假设每页就显示1条商品,现在显示第2页,所以就查出来第2个商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
指定要查询出来商品的名称和价格就可以
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"_source": ["name", "price"]
}
更加适合生产环境的使用,可以构建复杂的查询
---------------------------------------------------------------------------------------------------------------------------------
3、query filter
搜索商品名称包含yagao,而且售价大于25元的商品
GET /ecommerce/product/_search
{
"query" : {
"bool" : {
"must" : {
"match" : {
"name" : "yagao"
}
},
"filter" : {
"range" : {
"price" : { "gt" : 25 }
}
}
}
}
}
---------------------------------------------------------------------------------------------------------------------------------
4、full-text search(全文检索)
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "yagao producer"
}
}
}
尽量,无论是学什么技术,比如说你当初学java,学linux,学shell,学javascript,学hadoop。。。。一定自己动手,特别是手工敲各种命令和代码,切记切记,减少复制粘贴的操作。只有自己动手手工敲,学习效果才最好。
producer这个字段,会先被拆解,建立倒排索引
special 4
yagao 4
producer 1,2,3,4
gaolujie 1
zhognhua 3
jiajieshi 2
yagao producer ---> yagao和producer
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": [
"meibai"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 0.25811607,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 0.25811607,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": [
"qingxin"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 0.1805489,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
}
]
}
}
---------------------------------------------------------------------------------------------------------------------------------
5、phrase search(短语搜索)
跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
GET /ecommerce/product/_search
{
"query" : {
"match_phrase" : {
"producer" : "yagao producer"
}
}
}
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.70293105,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "4",
"_score": 0.70293105,
"_source": {
"name": "special yagao",
"desc": "special meibai",
"price": 50,
"producer": "special yagao producer",
"tags": [
"meibai"
]
}
}
]
}
}
---------------------------------------------------------------------------------------------------------------------------------
6、highlight search(高亮搜索结果)
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"producer" : "producer"
}
},
"highlight": {
"fields" : {
"producer" : {}
}
}
}
聚合分析:
第一个分析需求:计算每个tag下的商品数量
GET /ecommerce/product/_search
{
"aggs": {
"group_by_tags": {
"terms": { "field": "tags" }
}
}
}
将文本field的fielddata属性设置为true
PUT /ecommerce/_mapping/product
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"all_tags": {
"terms": { "field": "tags" }
}
}
}
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2
},
{
"key": "meibai",
"doc_count": 2
},
{
"key": "qingxin",
"doc_count": 1
}
]
}
}
}
----------------------------------------------------------------------------------------------------------------
第二个聚合分析的需求:对名称中包含yagao的商品,计算每个tag下的商品数量
GET /ecommerce/product/_search
{
"size": 0,
"query": {
"match": {
"name": "yagao"
}
},
"aggs": {
"all_tags": {
"terms": {
"field": "tags"
}
}
}
}
----------------------------------------------------------------------------------------------------------------
第三个聚合分析的需求:先分组,再算每组的平均值,计算每个tag下的商品的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"group_by_tags" : {
"terms" : { "field" : "tags" },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0,
"hits": []
},
"aggregations": {
"group_by_tags": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "fangzhu",
"doc_count": 2,
"avg_price": {
"value": 27.5
}
},
{
"key": "meibai",
"doc_count": 2,
"avg_price": {
"value": 40
}
},
{
"key": "qingxin",
"doc_count": 1,
"avg_price": {
"value": 40
}
}
]
}
}
}
----------------------------------------------------------------------------------------------------------------
第四个数据分析需求:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
GET /ecommerce/product/_search
{
"size": 0,
"aggs" : {
"all_tags" : {
"terms" : { "field" : "tags", "order": { "avg_price": "desc" } },
"aggs" : {
"avg_price" : {
"avg" : { "field" : "price" }
}
}
}
}
}
我们现在全部都是用es的restful api在学习和讲解es的所欲知识点和功能点,但是没有使用一些编程语言去讲解(比如java),原因有以下:
1、es最重要的api,让我们进行各种尝试、学习甚至在某些环境下进行使用的api,就是restful api。如果你学习不用es restful api,比如我上来就用java api来讲es,也是可以的,但是你根本就漏掉了es知识的一大块,你都不知道它最重要的restful api是怎么用的
2、讲知识点,用es restful api,更加方便,快捷,不用每次都写大量的java代码,能加快讲课的效率和速度,更加易于同学们关注es本身的知识和功能的学习
3、我们通常会讲完es知识点后,开始详细讲解java api,如何用java api执行各种操作
4、我们每个篇章都会搭配一个项目实战,项目实战是完全基于java去开发的真实项目和系统
----------------------------------------------------------------------------------------------------------------
第五个数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格
GET /ecommerce/product/_search
{
"size": 0,
"aggs": {
"group_by_price": {
"range": {
"field": "price",
"ranges": [
{
"from": 0,
"to": 20
},
{
"from": 20,
"to": 40
},
{
"from": 40,
"to": 50
}
]
},
"aggs": {
"group_by_tags": {
"terms": {
"field": "tags"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
}
}
第9课:elasticsearch的分布式架构
1、Elasticsearch对复杂分布式机制的透明隐藏特性
2、Elasticsearch的垂直扩容与水平扩容
3、增减或减少节点时的数据rebalance
4、master节点
5、节点对等的分布式架构
--------------------------------------------------------------------------------------------------------------------
1、Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量
隐藏了复杂的分布式机制
分片机制(我们之前随随便便就将一些document插入到es集群中去了,我们有没有care过数据怎么进行分片的,数据到哪个shard中去)
cluster discovery(集群发现机制,我们之前在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard)
shard负载均衡(举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求)
shard副本,请求路由,集群扩容,shard重分配
--------------------------------------------------------------------------------------------------------------------
2、Elasticsearch的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器啊
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
普通服务器:1T,1万,100万
强大服务器:10T,50万,500万
扩容对应用程序的透明性
--------------------------------------------------------------------------------------------------------------------
3、增减或减少节点时的数据rebalance
保持负载均衡
--------------------------------------------------------------------------------------------------------------------
4、master节点
(1)创建或删除索引
(2)增加或删除节点
--------------------------------------------------------------------------------------------------------------------
5、节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求
(2)自动请求路由
(3)响应收集
课程10:
1、shard&replica机制再次梳理
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
------------------------------------------------------------------------------------------------
2、图解单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
课程11,2个node的图解:
1、图解2个node环境下replica shard是如何分配的
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
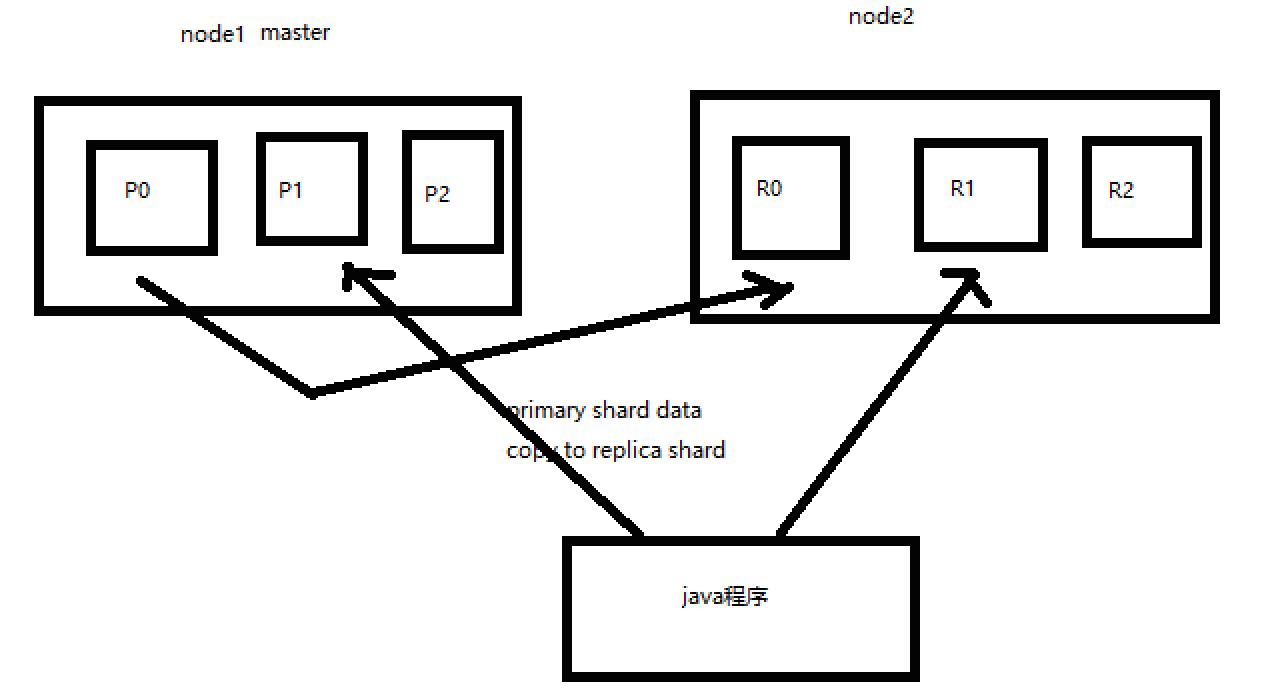
课程12:图解横向扩容过程,如何超出扩容极限,以及提升容错性
课程13:.图解Elasticsearch容错机制:master选举,replica容错,数据恢复
课程14:解析document的核心元数据以及图解剖析index创建反例
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"test_content": "test test"
}
}
------------------------------------------------------------------------------------------------------------------------------------------
1、_index元数据
(1)代表一个document存放在哪个index中
(2)类似的数据放在一个索引,非类似的数据放不同索引:product index(包含了所有的商品),sales index(包含了所有的商品销售数据),inventory index(包含了所有库存相关的数据)。如果你把比如product,sales,human resource(employee),全都放在一个大的index里面,比如说company index,不合适的。
(3)index中包含了很多类似的document:类似是什么意思,其实指的就是说,这些document的fields很大一部分是相同的,你说你放了3个document,每个document的fields都完全不一样,这就不是类似了,就不太适合放到一个index里面去了。
(4)索引名称必须是小写的,不能用下划线开头,不能包含逗号:product,website,blog
2、_type元数据
(1)代表document属于index中的哪个类别(type)
(2)一个索引通常会划分为多个type,逻辑上对index中有些许不同的几类数据进行分类:因为一批相同的数据,可能有很多相同的fields,但是还是可能会有一些轻微的不同,可能会有少数fields是不一样的,举个例子,就比如说,商品,可能划分为电子商品,生鲜商品,日化商品,等等。
(3)type名称可以是大写或者小写,但是同时不能用下划线开头,不能包含逗号
3、_id元数据
(1)代表document的唯一标识,与index和type一起,可以唯一标识和定位一个document
(2)我们可以手动指定document的id(put /index/type/id),也可以不指定,由es自动为我们创建一个id
第16节:document的_source元数据以及定制返回结果解析
1、_source元数据
put /test_index/test_type/1
{
"test_field1": "test field1",
"test_field2": "test field2"
}
get /test_index/test_type/1
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
}
_source元数据:就是说,我们在创建一个document的时候,使用的那个放在request body中的json串,默认情况下,在get的时候,会原封不动的给我们返回回来。
------------------------------------------------------------------------------------------------------------------
2、定制返回结果
定制返回的结果,指定_source中,返回哪些field
GET /test_index/test_type/1?_source=test_field1,test_field2
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field2": "test field2"
}
}
第21节:上机动手实战演练基于_version进行乐观锁并发控制
1、上机动手实战演练基于_version进行乐观锁并发控制
(1)先构造一条数据出来
PUT /test_index/test_type/7
{
"test_field": "test test"
}
(2)模拟两个客户端,都获取到了同一条数据
GET test_index/test_type/7
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 1,
"found": true,
"_source": {
"test_field": "test test"
}
}
(3)其中一个客户端,先更新了一下这个数据
同时带上数据的版本号,确保说,es中的数据的版本号,跟客户端中的数据的版本号是相同的,才能修改
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 1"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
(4)另外一个客户端,尝试基于version=1的数据去进行修改,同样带上version版本号,进行乐观锁的并发控制
PUT /test_index/test_type/7?version=1
{
"test_field": "test client 2"
}
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "3",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[test_type][7]: version conflict, current version [2] is different than the one provided [1]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "3",
"index": "test_index"
},
"status": 409
}
(5)在乐观锁成功阻止并发问题之后,尝试正确的完成更新
GET /test_index/test_type/7
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 2,
"found": true,
"_source": {
"test_field": "test client 1"
}
}
基于最新的数据和版本号,去进行修改,修改后,带上最新的版本号,可能这个步骤会需要反复执行好几次,才能成功,特别是在多线程并发更新同一条数据很频繁的情况下
PUT /test_index/test_type/7?version=2
{
"test_field": "test client 2"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "7",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
第22节:上机动手实战演练基于external version进行乐观锁并发控制
external version
es提供了一个feature,就是说,你可以不用它提供的内部_version版本号来进行并发控制,可以基于你自己维护的一个版本号来进行并发控制。举个列子,加入你的数据在mysql里也有一份,然后你的应用系统本身就维护了一个版本号,无论是什么自己生成的,程序控制的。这个时候,你进行乐观锁并发控制的时候,可能并不是想要用es内部的_version来进行控制,而是用你自己维护的那个version来进行控制。
?version=1
?version=1&version_type=external
version_type=external,唯一的区别在于,_version,只有当你提供的version与es中的_version一模一样的时候,才可以进行修改,只要不一样,就报错;当version_type=external的时候,只有当你提供的version比es中的_version大的时候,才能完成修改
es,_version=1,?version=1,才能更新成功
es,_version=1,?version>1&version_type=external,才能成功,比如说?version=2&version_type=external
(1)先构造一条数据
PUT /test_index/test_type/8
{
"test_field": "test"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
(2)模拟两个客户端同时查询到这条数据
GET /test_index/test_type/8
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_version": 1,
"found": true,
"_source": {
"test_field": "test"
}
}
(3)第一个客户端先进行修改,此时客户端程序是在自己的数据库中获取到了这条数据的最新版本号,比如说是2
PUT /test_index/test_type/8?version=2&version_type=external
{
"test_field": "test client 1"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
(4)模拟第二个客户端,同时拿到了自己数据库中维护的那个版本号,也是2,同时基于version=2发起了修改
PUT /test_index/test_type/8?version=2&version_type=external
{
"test_field": "test client 2"
}
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[test_type][8]: version conflict, current version [2] is higher or equal to the one provided [2]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "1",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[test_type][8]: version conflict, current version [2] is higher or equal to the one provided [2]",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "1",
"index": "test_index"
},
"status": 409
}
(5)在并发控制成功后,重新基于最新的版本号发起更新
GET /test_index/test_type/8
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_version": 2,
"found": true,
"_source": {
"test_field": "test client 1"
}
}
PUT /test_index/test_type/8?version=3&version_type=external
{
"test_field": "test client 2"
}
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
第25节:图解partial update乐观锁并发控制原理以及相关操作讲解:
post /index/type/id/_update?retry_on_conflict=5&version=6
第26节:上机动手实战演练mget批量查询api
1、批量查询的好处
就是一条一条的查询,比如说要查询100条数据,那么就要发送100次网络请求,这个开销还是很大的
如果进行批量查询的话,查询100条数据,就只要发送1次网络请求,网络请求的性能开销缩减100倍
2、mget的语法
(1)一条一条的查询
GET /test_index/test_type/1
GET /test_index/test_type/2
(2)mget批量查询
GET /_mget
{
"docs" : [
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 1
},
{
"_index" : "test_index",
"_type" : "test_type",
"_id" : 2
}
]
}
{
"docs": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 2,
"found": true,
"_source": {
"test_field1": "test field1",
"test_field2": "test field2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"_version": 1,
"found": true,
"_source": {
"test_content": "my test"
}
}
]
}
(3)如果查询的document是一个index下的不同type种的话
GET /test_index/_mget
{
"docs" : [
{
"_type" : "test_type",
"_id" : 1
},
{
"_type" : "test_type",
"_id" : 2
}
]
}
(4)如果查询的数据都在同一个index下的同一个type下,最简单了
GET /test_index/test_type/_mget
{
"ids": [1, 2]
}
3、mget的重要性
可以说mget是很重要的,一般来说,在进行查询的时候,如果一次性要查询多条数据的话,那么一定要用batch批量操作的api
尽可能减少网络开销次数,可能可以将性能提升数倍,甚至数十倍,非常非常之重要
第27节:分布式文档系统_上机动手实战演练bulk批量增删改:
课程大纲
1、bulk语法
POST /_bulk
{ "delete": { "_index": "test_index", "_type": "test_type", "_id": "3" }}
{ "create": { "_index": "test_index", "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_index": "test_index", "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_index": "test_index", "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
每一个操作要两个json串,语法如下:
{"action": {"metadata"}}
{"data"}
举例,比如你现在要创建一个文档,放bulk里面,看起来会是这样子的:
{"index": {"_index": "test_index", "_type", "test_type", "_id": "1"}}
{"test_field1": "test1", "test_field2": "test2"}
有哪些类型的操作可以执行呢?
(1)delete:删除一个文档,只要1个json串就可以了
(2)create:PUT /index/type/id/_create,强制创建
(3)index:普通的put操作,可以是创建文档,也可以是全量替换文档
(4)update:执行的partial update操作
bulk api对json的语法,有严格的要求,每个json串不能换行,只能放一行,同时一个json串和一个json串之间,必须有一个换行
{
"error": {
"root_cause": [
{
"type": "json_e_o_f_exception",
"reason": "Unexpected end-of-input: expected close marker for Object (start marker at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@5a5932cd; line: 1, column: 1])\n at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@5a5932cd; line: 1, column: 3]"
}
],
"type": "json_e_o_f_exception",
"reason": "Unexpected end-of-input: expected close marker for Object (start marker at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@5a5932cd; line: 1, column: 1])\n at [Source: org.elasticsearch.transport.netty4.ByteBufStreamInput@5a5932cd; line: 1, column: 3]"
},
"status": 500
}
{
"took": 41,
"errors": true,
"items": [
{
"delete": {
"found": true,
"_index": "test_index",
"_type": "test_type",
"_id": "10",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
},
{
"create": {
"_index": "test_index",
"_type": "test_type",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"create": {
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"status": 409,
"error": {
"type": "version_conflict_engine_exception",
"reason": "[test_type][2]: version conflict, document already exists (current version [1])",
"index_uuid": "6m0G7yx7R1KECWWGnfH1sw",
"shard": "2",
"index": "test_index"
}
}
},
{
"index": {
"_index": "test_index",
"_type": "test_type",
"_id": "4",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true,
"status": 201
}
},
{
"index": {
"_index": "test_index",
"_type": "test_type",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false,
"status": 200
}
},
{
"update": {
"_index": "test_index",
"_type": "test_type",
"_id": "1",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"status": 200
}
}
]
}
bulk操作中,任意一个操作失败,是不会影响其他的操作的,但是在返回结果里,会告诉你异常日志
POST /test_index/_bulk
{ "delete": { "_type": "test_type", "_id": "3" }}
{ "create": { "_type": "test_type", "_id": "12" }}
{ "test_field": "test12" }
{ "index": { "_type": "test_type" }}
{ "test_field": "auto-generate id test" }
{ "index": { "_type": "test_type", "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_type": "test_type", "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
POST /test_index/test_type/_bulk
{ "delete": { "_id": "3" }}
{ "create": { "_id": "12" }}
{ "test_field": "test12" }
{ "index": { }}
{ "test_field": "auto-generate id test" }
{ "index": { "_id": "2" }}
{ "test_field": "replaced test2" }
{ "update": { "_id": "1", "_retry_on_conflict" : 3} }
{ "doc" : {"test_field2" : "bulk test1"} }
2、bulk size最佳大小
bulk request会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的bulk size。一般从1000~5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在5~15MB之间。
第35节:初识搜索引擎_multi-index&multi-type搜索模式解析以及搜索原理初步图解
1、multi-index和multi-type搜索模式
告诉你如何一次性搜索多个index和多个type下的数据
/_search:所有索引,所有type下的所有数据都搜索出来
/index1/_search:指定一个index,搜索其下所有type的数据
/index1,index2/_search:同时搜索两个index下的数据
/*1,*2/_search:按照通配符去匹配多个索引
/index1/type1/_search:搜索一个index下指定的type的数据
/index1/type1,type2/_search:可以搜索一个index下多个type的数据
/index1,index2/type1,type2/_search:搜索多个index下的多个type的数据
/_all/type1,type2/_search:_all,可以代表搜索所有index下的指定type的数据
第36节:初识搜索引擎_分页搜索以及deep paging性能问题深度图解揭秘
1、讲解如何使用es进行分页搜索的语法
size,from
GET /_search?size=10
GET /_search?size=10&from=0
GET /_search?size=10&from=20
分页的上机实验
GET /test_index/test_type/_search
"hits": {
"total": 9,
"max_score": 1,
我们假设将这9条数据分成3页,每一页是3条数据,来实验一下这个分页搜索的效果
GET /test_index/test_type/_search?from=0&size=3
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 9,
"max_score": 1,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": 1,
"_source": {
"test_field": "test client 2"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": 1,
"_source": {
"test_field": "tes test"
}
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "4",
"_score": 1,
"_source": {
"test_field": "test4"
}
}
]
}
}
第一页:id=8,6,4
GET /test_index/test_type/_search?from=3&size=3
第二页:id=2,自动生成,7
GET /test_index/test_type/_search?from=6&size=3
第三页:id=1,11,3
2、什么是deep paging问题?为什么会产生这个问题,它的底层原理是什么?
和mysql一样 limit翻页如果很大,会把几万条数据全取出来。
第37节:初识搜索引擎_快速掌握query string search语法以及_all metadata原理揭秘
1、query string基础语法
GET /test_index/test_type/_search?q=test_field:test
GET /test_index/test_type/_search?q=+test_field:test 必须包含test_field:test (其实加不加一样)
GET /test_index/test_type/_search?q=-test_field:test 必须不包含这个数据才能被搜索出来
一个是掌握q=field:search content的语法,还有一个是掌握+和-的含义
2、_all metadata的原理和作用
GET /test_index/test_type/_search?q=test
直接可以搜索所有的field,任意一个field包含指定的关键字就可以搜索出来。我们在进行中搜索的时候,难道是对document中的每一个field都进行一次搜索吗?不是的
es中的_all元数据,在建立索引的时候,我们插入一条document,它里面包含了多个field,此时,es会自动将多个field的值,全部用字符串的方式串联起来,变成一个长的字符串,作为_all field的值,同时建立索引
后面如果在搜索的时候,没有对某个field指定搜索,就默认搜索_all field,其中是包含了所有field的值的
举个例子
{
"name": "jack",
"age": 26,
"email": "jack@sina.com",
"address": "guamgzhou"
}
"jack 26 jack@sina.com guangzhou",作为这一条document的_all field的值,同时进行分词后建立对应的倒排索引
生产环境不使用
第38节:初识搜索引擎_用一个例子告诉你mapping到底是什么:
插入几条数据,让es自动为我们建立一个索引
PUT /website/article/1
{
"post_date": "2017-01-01",
"title": "my first article",
"content": "this is my first article in this website",
"author_id": 11400
}
PUT /website/article/2
{
"post_date": "2017-01-02",
"title": "my second article",
"content": "this is my second article in this website",
"author_id": 11400
}
PUT /website/article/3
{
"post_date": "2017-01-03",
"title": "my third article",
"content": "this is my third article in this website",
"author_id": 11400
}
尝试各种搜索
GET /website/article/_search?q=2017 3条结果
GET /website/article/_search?q=2017-01-01 3条结果
GET /website/article/_search?q=post_date:2017-01-01 1条结果
GET /website/article/_search?q=post_date:2017 1条结果
查看es自动建立的mapping,带出什么是mapping的知识点
自动或手动为index中的type建立的一种数据结构和相关配置,简称为mapping
dynamic mapping,自动为我们建立index,创建type,以及type对应的mapping,mapping中包含了每个field对应的数据类型,以及如何分词等设置
我们当然,后面会讲解,也可以手动在创建数据之前,先创建index和type,以及type对应的mapping
GET /website/_mapping/article
{
"website": {
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"post_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
搜索结果为什么不一致,因为es自动建立mapping的时候,设置了不同的field不同的data type。不同的data type的分词、搜索等行为是不一样的。所以出现了_all field和post_date field的搜索表现完全不一样。
第42节:初识搜索引擎_query string的分词以及mapping引入案例遗留问题的大揭秘
1、query string分词
query string必须以和index建立时相同的analyzer进行分词
query string对exact value和full text的区别对待
date:exact value
_all:full text
比如我们有一个document,其中有一个field,包含的value是:hello you and me,建立倒排索引
我们要搜索这个document对应的index,搜索文本是hell me,这个搜索文本就是query string
query string,默认情况下,es会使用它对应的field建立倒排索引时相同的分词器去进行分词,分词和normalization,只有这样,才能实现正确的搜索
我们建立倒排索引的时候,将dogs --> dog,结果你搜索的时候,还是一个dogs,那不就搜索不到了吗?所以搜索的时候,那个dogs也必须变成dog才行。才能搜索到。
知识点:不同类型的field,可能有的就是full text,有的就是exact value
post_date,date:exact value
_all:full text,分词,normalization
2、mapping引入案例遗留问题大揭秘
GET /_search?q=2017
搜索的是_all field,document所有的field都会拼接成一个大串,进行分词
2017-01-02 my second article this is my second article in this website 11400
doc1 doc2 doc3
2017 * * *
01 *
02 *
03 *
_all,2017,自然会搜索到3个docuemnt
GET /_search?q=2017-01-01
_all,2017-01-01,query string会用跟建立倒排索引一样的分词器去进行分词
2017
01
01
GET /_search?q=post_date:2017-01-01
date,会作为exact value去建立索引
doc1 doc2 doc3
2017-01-01 *
2017-01-02 *
2017-01-03 *
post_date:2017-01-01,2017-01-01,doc1一条document
GET /_search?q=post_date:2017,这个在这里不讲解,因为是es 5.2以后做的一个优化
3、测试分词器
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
第44节:初识搜索引擎_mapping的核心数据类型以及dynamic mapping
1、核心的数据类型
string
byte,short,integer,long
float,double
boolean
date
2、dynamic mapping
true or false --> boolean
123 --> long
123.45 --> double
2017-01-01 --> date
"hello world" --> string/text
3、查看mapping
GET /index/_mapping/type
第45节:初识搜索引擎_手动建立和修改mapping以及定制string类型数据是否分词
1、如何建立索引
analyzed
not_analyzed
no
2、修改mapping
只能创建index时手动建立mapping,或者新增field mapping,但是不能update field mapping
PUT /website
{
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "long"
},
"title": {
"type": "text",
"analyzer": "english"
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"publisher_id": {
"type": "text",
"index": "not_analyzed"
}
}
}
}
}
PUT /website
{
"mappings": {
"article": {
"properties": {
"author_id": {
"type": "text"
}
}
}
}
}
{
"error": {
"root_cause": [
{
"type": "index_already_exists_exception",
"reason": "index [website/co1dgJ-uTYGBEEOOL8GsQQ] already exists",
"index_uuid": "co1dgJ-uTYGBEEOOL8GsQQ",
"index": "website"
}
],
"type": "index_already_exists_exception",
"reason": "index [website/co1dgJ-uTYGBEEOOL8GsQQ] already exists",
"index_uuid": "co1dgJ-uTYGBEEOOL8GsQQ",
"index": "website"
},
"status": 400
}
PUT /website/_mapping/article
{
"properties" : {
"new_field" : {
"type" : "string",
"index": "not_analyzed"
}
}
}
3、测试mapping
GET /website/_analyze
{
"field": "content",
"text": "my-dogs"
}
GET website/_analyze
{
"field": "new_field",
"text": "my dogs"
}
{
"error": {
"root_cause": [
{
"type": "remote_transport_exception",
"reason": "[4onsTYV][127.0.0.1:9300][indices:admin/analyze[s]]"
}
],
"type": "illegal_argument_exception",
"reason": "Can't process field [new_field], Analysis requests are only supported on tokenized fields"
},
"status": 400
}
第46节:初识搜索引擎_mapping复杂数据类型以及object类型数据底层结构大揭秘
1、multivalue field
{ "tags": [ "tag1", "tag2" ]}
建立索引时与string是一样的,数据类型不能混
2、empty field
null,[],[null]
3、object field
PUT /company/employee/1
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}
address:object类型
GET /company/_mapping/employee
{
"company": {
"mappings": {
"employee": {
"properties": {
"address": {
"properties": {
"city": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"province": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"age": {
"type": "long"
},
"join_date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
}
}
{
"address": {
"country": "china",
"province": "guangdong",
"city": "guangzhou"
},
"name": "jack",
"age": 27,
"join_date": "2017-01-01"
}
{
"name": [jack],
"age": [27],
"join_date": [2017-01-01],
"address.country": [china],
"address.province": [guangdong],
"address.city": [guangzhou]
}
{
"authors": [
{ "age": 26, "name": "Jack White"},
{ "age": 55, "name": "Tom Jones"},
{ "age": 39, "name": "Kitty Smith"}
]
}
{
"authors.age": [26, 55, 39],
"authors.name": [jack, white, tom, jones, kitty, smith]
}
第47节:初识搜索引擎_search api的基础语法介绍
1、search api的基本语法
GET /search
{}
GET /index1,index2/type1,type2/search
{}
GET /_search
{
"from": 0,
"size": 10
}
2、http协议中get是否可以带上request body
HTTP协议,一般不允许get请求带上request body,但是因为get更加适合描述查询数据的操作,因此还是这么用了
GET /_search?from=0&size=10
POST /_search
{
"from":0,
"size":10
}
碰巧,很多浏览器,或者是服务器,也都支持GET+request body模式
如果遇到不支持的场景,也可以用POST /_search
第48节:初识搜索引擎_快速上机动手实战Query DSL搜索语法
课程大纲
1、一个例子让你明白什么是Query DSL
GET /_search
{
"query": {
"match_all": {}
}
}
2、Query DSL的基本语法
{
QUERY_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
{
QUERY_NAME: {
FIELD_NAME: {
ARGUMENT: VALUE,
ARGUMENT: VALUE,...
}
}
}
示例:
GET /test_index/test_type/_search
{
"query": {
"match": {
"test_field": "test"
}
}
}
3、如何组合多个搜索条件
搜索需求:title必须包含elasticsearch,content可以包含elasticsearch也可以不包含,author_id必须不为111
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "website",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "my hadoop article",
"content": "hadoop is very bad",
"author_id": 111
}
},
{
"_index": "website",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "my elasticsearch article",
"content": "es is very bad",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "3",
"_score": 1,
"_source": {
"title": "my elasticsearch article",
"content": "es is very goods",
"author_id": 111
}
}
]
}
}
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
GET /test_index/_search
{
"query": {
"bool": {
"must": { "match": { "name": "tom" }},
"should": [
{ "match": { "hired": true }},
{ "bool": {
"must": { "match": { "personality": "good" }},
"must_not": { "match": { "rude": true }}
}}
],
"minimum_should_match": 1
}
}
}
第49节:初识搜索引擎_filter与query深入对比解密:相关度,性能
1、filter与query示例
PUT /company/employee/2
{
"address": {
"country": "china",
"province": "jiangsu",
"city": "nanjing"
},
"name": "tom",
"age": 30,
"join_date": "2016-01-01"
}
PUT /company/employee/3
{
"address": {
"country": "china",
"province": "shanxi",
"city": "xian"
},
"name": "marry",
"age": 35,
"join_date": "2015-01-01"
}
搜索请求:年龄必须大于等于30,同时join_date必须是2016-01-01
GET /company/employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"join_date": "2016-01-01"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
2、filter与query对比大解密
filter,仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响
query,会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query;如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter
除非是你的这些搜索条件,你希望越符合这些搜索条件的document越排在前面返回,那么这些搜索条件要放在query中;如果你不希望一些搜索条件来影响你的document排序,那么就放在filter中即可
3、filter与query性能
filter,不需要计算相关度分数,不需要按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据
query,相反,要计算相关度分数,按照分数进行排序,而且无法cache结果
第50节:初识搜索引擎_上机动手实战常用的各种query搜索语法
课程大纲
1、match all
GET /_search
{
"query": {
"match_all": {}
}
}
2、match
GET /_search
{
"query": { "match": { "title": "my elasticsearch article" }}
}
3、multi match
GET /test_index/test_type/_search
{
"query": {
"multi_match": {
"query": "test",
"fields": ["test_field", "test_field1"]
}
}
}
4、range query
GET /company/employee/_search
{
"query": {
"range": {
"age": {
"gte": 30
}
}
}
}
5、term query 把这个字段当成exact value来查询
GET /test_index/test_type/_search
{
"query": {
"term": {
"test_field": "test hello"
}
}
}
6、terms query
GET /_search
{
"query": { "terms": { "tag": [ "search", "full_text", "nosql" ] }}
}
7、exist query(2.x中的查询,现在已经不提供了)
第51节:初识搜索引擎_上机动手实战多搜索条件组合查询
课程大纲
GET /website/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "elasticsearch"
}
}
],
"should": [
{
"match": {
"content": "elasticsearch"
}
}
],
"must_not": [
{
"match": {
"author_id": 111
}
}
]
}
}
}
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
bool
must,must_not,should,filter
每个子查询都会计算一个document针对它的相关度分数,然后bool综合所有分数,合并为一个分数,当然filter是不会计算分数的
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}
}
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
第52节:初识搜索引擎_上机动手实战如何定位不合法的搜索以及其原因
课程大纲
GET /test_index/test_type/_validate/query?explain
{
"query": {
"math": {
"test_field": "test"
}
}
}
{
"valid": false,
"error": "org.elasticsearch.common.ParsingException: no [query] registered for [math]"
}
GET /test_index/test_type/_validate/query?explain
{
"query": {
"match": {
"test_field": "test"
}
}
}
{
"valid": true,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"explanations": [
{
"index": "test_index",
"valid": true,
"explanation": "+test_field:test #(#_type:test_type)"
}
]
}
一般用在那种特别复杂庞大的搜索下,比如你一下子写了上百行的搜索,这个时候可以先用validate api去验证一下,搜索是否合法
第53节:初识搜素引擎_上机动手实战如何定制搜索结果的排序规则
课程大纲
1、默认排序规则
默认情况下,是按照_score降序排序的
然而,某些情况下,可能没有有用的_score,比如说filter
GET /_search
{
"query" : {
"bool" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
当然,也可以是constant_score
GET /_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"author_id" : 1
}
}
}
}
}
2、定制排序规则
GET /company/employee/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
},
"sort": [
{
"join_date": {
"order": "asc"
}
}
]
}
第54节:初识搜索引擎_解密如何将一个field索引两次来解决字符串排序问题
课程大纲
如果对一个string field进行排序,结果往往不准确,因为分词后是多个单词,再排序就不是我们想要的结果了
通常解决方案是,将一个string field建立两次索引,一个分词,用来进行搜索;一个不分词,用来进行排序
PUT /website
{
"mappings": {
"article": {
"properties": {
"title": {
"type": "text",
"fields": {
"raw": {
"type": "string",
"index": "not_analyzed"
}
},
"fielddata": true
},
"content": {
"type": "text"
},
"post_date": {
"type": "date"
},
"author_id": {
"type": "long"
}
}
}
}
}
PUT /website/article/1
{
"title": "first article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "website",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"title": "first article",
"content": "this is my first article",
"post_date": "2017-02-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"title": "second article",
"content": "this is my second article",
"post_date": "2017-01-01",
"author_id": 110
}
},
{
"_index": "website",
"_type": "article",
"_id": "3",
"_score": 1,
"_source": {
"title": "third article",
"content": "this is my third article",
"post_date": "2017-03-01",
"author_id": 110
}
}
]
}
}
GET /website/article/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"title.raw": {
"order": "desc"
}
}
]
}
第59节:初识搜索引擎_搜索相关参数梳理以及bouncing results问题解决方案
1、preference
决定了哪些shard会被用来执行搜索操作
_primary(只把请求打到primary shards上去), _primary_first(优先把请求打到primary shards上去), _local, _only_node:xyz, _prefer_node:xyz, _shards:2,3
bouncing results问题,两个document排序,field值相同;不同的shard上,可能排序不同;每次请求轮询打到不同的replica shard上;每次页面上看到的搜索结果的排序都不一样。这就是bouncing result,也就是跳跃的结果。
搜索的时候,是轮询将搜索请求发送到每一个replica shard(primary shard),但是在不同的shard上,可能document的排序不同
解决方案就是将preference设置为一个字符串,比如说user_id,让每个user每次搜索的时候,都使用同一个replica shard去执行,就不会看到bouncing results了
2、timeout,已经讲解过原理了,主要就是限定在一定时间内,将部分获取到的数据直接返回,避免查询耗时过长
3、routing,document文档路由,_id路由,routing=user_id,这样的话可以让同一个user对应的数据到一个shard上去
4、search_type
default:query_then_fetch
dfs_query_then_fetch,可以提升revelance sort精准度
第60:初识搜索引擎_上机动手实战基于scoll技术滚动搜索大量数据
课程大纲
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scoll滚动查询,一批一批的查,直到所有数据都查询完处理完
使用scoll滚动搜索,可以先搜索一批数据,然后下次再搜索一批数据,以此类推,直到搜索出全部的数据来
scoll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
采用基于_doc进行排序的方式,性能较高
每次发送scroll请求,我们还需要指定一个scoll参数,指定一个时间窗口,每次搜索请求只要在这个时间窗口内能完成就可以了
GET /test_index/test_type/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": [ "_doc" ],
"size": 3
}
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 10,
"max_score": null,
"hits": [
{
"_index": "test_index",
"_type": "test_type",
"_id": "8",
"_score": null,
"_source": {
"test_field": "test client 2"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "6",
"_score": null,
"_source": {
"test_field": "tes test"
},
"sort": [
0
]
},
{
"_index": "test_index",
"_type": "test_type",
"_id": "AVp4RN0bhjxldOOnBxaE",
"_score": null,
"_source": {
"test_content": "my test"
},
"sort": [
0
]
}
]
}
}
获得的结果会有一个scoll_id,下一次再发送scoll请求的时候,必须带上这个scoll_id
GET /_search/scroll
{
"scroll": "1m",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAACxeFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAALF8WNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAACxhFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAAsYhY0b25zVFlWWlRqR3ZJajlfc3BXejJ3"
}
11,4,7
3,2,1
20
scoll,看起来挺像分页的,但是其实使用场景不一样。分页主要是用来一页一页搜索,给用户看的;scoll主要是用来一批一批检索数据,让系统进行处理的
第61节:索引管理_快速上机动手实战创建、修改以及删除索引
课程大纲
1、为什么我们要手动创建索引?
2、创建索引
创建索引的语法
PUT /my_index
{
"settings": { ... any settings ... },
"mappings": {
"type_one": { ... any mappings ... },
"type_two": { ... any mappings ... },
...
}
}
创建索引的示例
PUT /my_index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"my_type": {
"properties": {
"my_field": {
"type": "text"
}
}
}
}
}
3、修改索引
PUT /my_index/_settings
{
"number_of_replicas": 1
}
4、删除索引
DELETE /my_index
DELETE /index_one,index_two
DELETE /index_*
DELETE /_all
elasticsearch.yml
action.destructive_requires_name: true (不能用通配符方式一次性干掉所有索引)
第62节:索引管理_快速上机动手实战修改分词器以及定制自己的分词器
课程大纲
1、默认的分词器
standard
standard tokenizer:以单词边界进行切分
standard token filter:什么都不做
lowercase token filter:将所有字母转换为小写
stop token filer(默认被禁用):移除停用词,比如a the it等等
2、修改分词器的设置
启用english停用词token filter
PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"es_std": {
"type": "standard",
"stopwords": "_english_"
}
}
}
}
}
GET /my_index/_analyze
{
"analyzer": "standard",
"text": "a dog is in the house"
}
GET /my_index/_analyze
{
"analyzer": "es_std",
"text":"a dog is in the house"
}
3、定制化自己的分词器
PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": ["&=> and"]
}
},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": ["the", "a"]
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": ["html_strip", "&_to_and"],
"tokenizer": "standard",
"filter": ["lowercase", "my_stopwords"]
}
}
}
}
}
GET /my_index/_analyze
{
"text": "tom&jerry are a friend in the house, <a>, HAHA!!",
"analyzer": "my_analyzer"
}
PUT /my_index/_mapping/my_type
{
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
第65节:索引管理_定制化自己的dynamic mapping策略
第66节:索引管理_复杂上机实验:基于scoll+bulk+索引别名实现零停机重建索引
课程大纲
1、重建索引
一个field的设置是不能被修改的,如果要修改一个Field,那么应该重新按照新的mapping,建立一个index,然后将数据批量查询出来,重新用bulk api写入index中
批量查询的时候,建议采用scroll api,并且采用多线程并发的方式来reindex数据,每次scoll就查询指定日期的一段数据,交给一个线程即可
(1)一开始,依靠dynamic mapping,插入数据,但是不小心有些数据是2017-01-01这种日期格式的,所以title这种field被自动映射为了date类型,实际上它应该是string类型的
PUT /my_index/my_type/3
{
"title": "2017-01-03"
}
{
"my_index": {
"mappings": {
"my_type": {
"properties": {
"title": {
"type": "date"
}
}
}
}
}
}
(2)当后期向索引中加入string类型的title值的时候,就会报错
PUT /my_index/my_type/4
{
"title": "my first article"
}
{
"error": {
"root_cause": [
{
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]"
}
],
"type": "mapper_parsing_exception",
"reason": "failed to parse [title]",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Invalid format: \"my first article\""
}
},
"status": 400
}
(3)如果此时想修改title的类型,是不可能的
PUT /my_index/_mapping/my_type
{
"properties": {
"title": {
"type": "text"
}
}
}
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
}
],
"type": "illegal_argument_exception",
"reason": "mapper [title] of different type, current_type [date], merged_type [text]"
},
"status": 400
}
(4)此时,唯一的办法,就是进行reindex,也就是说,重新建立一个索引,将旧索引的数据查询出来,再导入新索引
(5)如果说旧索引的名字,是old_index,新索引的名字是new_index,终端java应用,已经在使用old_index在操作了,难道还要去停止java应用,修改使用的index为new_index,才重新启动java应用吗?这个过程中,就会导致java应用停机,可用性降低
(6)所以说,给java应用一个别名,这个别名是指向旧索引的,java应用先用着,java应用先用goods_index alias来操作,此时实际指向的是旧的my_index
PUT /my_index/_alias/goods_index
(7)新建一个index,调整其title的类型为string
PUT /my_index_new
{
"mappings": {
"my_type": {
"properties": {
"title": {
"type": "text"
}
}
}
}
}
(8)使用scroll api将数据批量查询出来
GET /my_index/_search?scroll=1m
{
"query": {
"match_all": {}
},
"sort": ["_doc"],
"size": 1
}
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAADpAFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6QRY0b25zVFlWWlRqR3ZJajlfc3BXejJ3AAAAAAAAOkIWNG9uc1RZVlpUakd2SWo5X3NwV3oydwAAAAAAADpDFjRvbnNUWVZaVGpHdklqOV9zcFd6MncAAAAAAAA6RBY0b25zVFlWWlRqR3ZJajlfc3BXejJ3",
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": null,
"hits": [
{
"_index": "my_index",
"_type": "my_type",
"_id": "2",
"_score": null,
"_source": {
"title": "2017-01-02"
},
"sort": [
0
]
}
]
}
}
(9)采用bulk api将scoll查出来的一批数据,批量写入新索引
POST /_bulk
{ "index": { "_index": "my_index_new", "_type": "my_type", "_id": "2" }}
{ "title": "2017-01-02" }
(10)反复循环8~9,查询一批又一批的数据出来,采取bulk api将每一批数据批量写入新索引
(11)将goods_index alias切换到my_index_new上去,java应用会直接通过index别名使用新的索引中的数据,java应用程序不需要停机,零提交,高可用
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index", "alias": "goods_index" }},
{ "add": { "index": "my_index_new", "alias": "goods_index" }}
]
}
(12)直接通过goods_index别名来查询,是否ok
GET /goods_index/my_type/_search
2、基于alias对client透明切换index
PUT /my_index_v1/_alias/my_index
client对my_index进行操作
reindex操作,完成之后,切换v1到v2
POST /_aliases
{
"actions": [
{ "remove": { "index": "my_index_v1", "alias": "my_index" }},
{ "add": { "index": "my_index_v2", "alias": "my_index" }}
]
}
第68节:内核原理探秘_深度图解剖析document写入原理(buffer,segment,commit)
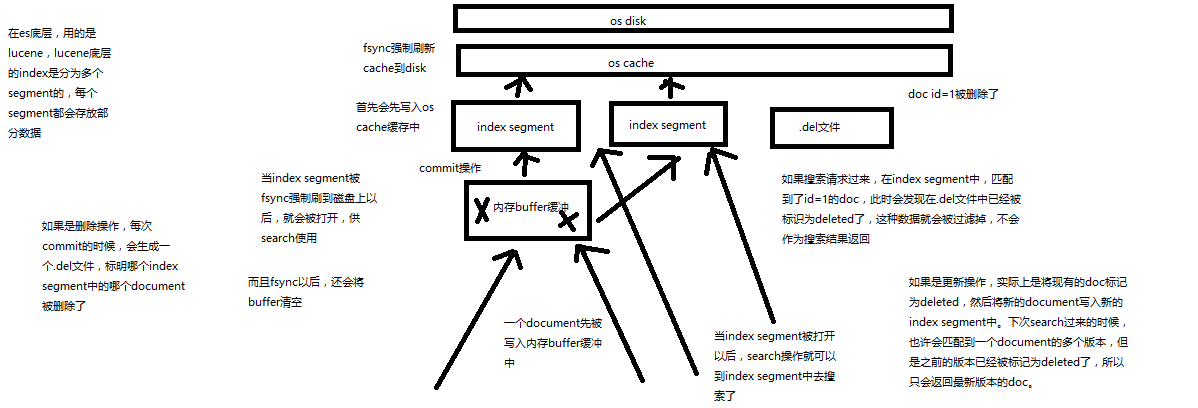
(1)数据写入buffer
(2)commit point
(3)buffer中的数据写入新的index segment
(4)等待在os cache中的index segment被fsync强制刷到磁盘上
(5)新的index sgement被打开,供search使用
(6)buffer被清空
每次commit point时,会有一个.del文件,标记了哪些segment中的哪些document被标记为deleted了
搜索的时候,会依次查询所有的segment,从旧的到新的,比如被修改过的document,在旧的segment中,会标记为deleted,在新的segment中会有其新的数据
第72节:Java API初步使用_员工管理案例:基于Java实现员工信息的增删改查
课程大纲
强调一下,我们的es讲课的风格
1、es这门技术有点特殊,跟比如其他的像纯java的课程,比如分布式课程,或者大数据类的课程,比如hadoop,spark,storm等。不太一样
2、es非常重要的一个api,是它的restful api,你自己思考一下,掌握这个es的restful api,可以让你执行一些核心的运维管理的操作,比如说创建索引,维护索引,执行各种refresh、flush、optimize操作,查看集群的健康状况,比如还有其他的一些操作,就不在这里枚举了。或者说探查一些数据,可能用java api并不方便。
3、es的学习,首先,你必须学好restful api,然后才是你自己的熟悉语言的api,java api。
这个《核心知识篇(上半季)》,其实主要还是打基础,包括核心的原理,还有核心的操作,还有部分高级的技术和操作,大量的实验,大量的画图,最后初步讲解怎么使用java api
《核心知识篇(下半季)》,包括深度讲解搜索这块技术,还有聚合分析这块技术,包括数据建模,包括java api的复杂使用,有一个项目实战s
员工信息
姓名
年龄
职位
国家
入职日期
薪水
我是默认大家至少有java基础的,如果你java一点都不会,请先自己补一下
1、maven依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>
log4j2.properties
appender.console.type = Console
appender.console.name = console
appender.console.layout.type = PatternLayout
rootLogger.level = info
rootLogger.appenderRef.console.ref = console
2、构建client
Settings settings = Settings.builder()
.put("cluster.name", "myClusterName").build();
TransportClient client = new PreBuiltTransportClient(settings);
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("host1"), 9300))
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("host2"), 9300));
client.close();
3、创建document
IndexResponse response = client.prepareIndex("index", "type", "1")
.setSource(jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
.get();
4、查询document
GetResponse response = client.prepareGet("index", "type", "1").get();
5、修改document
client.prepareUpdate("index", "type", "1")
.setDoc(jsonBuilder()
.startObject()
.field("gender", "male")
.endObject())
.get();
6、删除document
DeleteResponse response = client.prepareDelete("index", "type", "1").get();
第73节:Java API初步使用_员工管理案例:基于Java对员工信息进行复杂的搜索操作
课程大纲
SearchResponse response = client.prepareSearch("index1", "index2")
.setTypes("type1", "type2")
.setQuery(QueryBuilders.termQuery("multi", "test")) // Query
.setPostFilter(QueryBuilders.rangeQuery("age").from(12).to(18)) // Filter
.setFrom(0).setSize(60)
.get();
需求:
(1)搜索职位中包含technique的员工
(2)同时要求age在30到40岁之间
(3)分页查询,查找第一页
GET /company/employee/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"position": "technique"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30,
"lte": 40
}
}
}
}
},
"from": 0,
"size": 1
}
告诉大家,为什么刚才一边运行创建document,一边搜索什么都没搜索到????
近实时!!!
默认是1秒以后,写入es的数据,才能被搜索到。很明显刚才,写入数据不到一秒,我门就在搜索。
package com.roncoo.es.score.first;
import java.net.InetAddress;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
/**
* 员工搜索应用程序
* @author Administrator
*
*/
public class EmployeeSearchApp {
@SuppressWarnings({ "unchecked", "resource" })
public static void main(String[] args) throws Exception {
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch")
.build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
// prepareData(client);
executeSearch(client);
client.close();
}
/**
* 执行搜索操作
* @param client
*/
private static void executeSearch(TransportClient client) {
SearchResponse response = client.prepareSearch("company")
.setTypes("employee")
.setQuery(QueryBuilders.matchQuery("position", "technique"))
.setPostFilter(QueryBuilders.rangeQuery("age").from(30).to(40))
.setFrom(0).setSize(1)
.get();
SearchHit[] searchHits = response.getHits().getHits();
for(int i = 0; i < searchHits.length; i++) {
System.out.println(searchHits[i].getSourceAsString());
}
}
/**
* 准备数据
* @param client
*/
private static void prepareData(TransportClient client) throws Exception {
client.prepareIndex("company", "employee", "1")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name", "jack")
.field("age", 27)
.field("position", "technique software")
.field("country", "china")
.field("join_date", "2017-01-01")
.field("salary", 10000)
.endObject())
.get();
client.prepareIndex("company", "employee", "2")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name", "marry")
.field("age", 35)
.field("position", "technique manager")
.field("country", "china")
.field("join_date", "2017-01-01")
.field("salary", 12000)
.endObject())
.get();
client.prepareIndex("company", "employee", "3")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name", "tom")
.field("age", 32)
.field("position", "senior technique software")
.field("country", "china")
.field("join_date", "2016-01-01")
.field("salary", 11000)
.endObject())
.get();
client.prepareIndex("company", "employee", "4")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name", "jen")
.field("age", 25)
.field("position", "junior finance")
.field("country", "usa")
.field("join_date", "2016-01-01")
.field("salary", 7000)
.endObject())
.get();
client.prepareIndex("company", "employee", "5")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name", "mike")
.field("age", 37)
.field("position", "finance manager")
.field("country", "usa")
.field("join_date", "2015-01-01")
.field("salary", 15000)
.endObject())
.get();
}
}
第74节:Java API初步使用_员工管理案例:基于Java对员工信息进行聚合分析
课程大纲
SearchResponse sr = node.client().prepareSearch()
.addAggregation(
AggregationBuilders.terms("by_country").field("country")
.subAggregation(AggregationBuilders.dateHistogram("by_year")
.field("dateOfBirth")
.dateHistogramInterval(DateHistogramInterval.YEAR)
.subAggregation(AggregationBuilders.avg("avg_children").field("children"))
)
)
.execute().actionGet();
我们先给个需求:
(1)首先按照country国家来进行分组
(2)然后在每个country分组内,再按照入职年限进行分组
(3)最后计算每个分组内的平均薪资
PUT /company
{
"mappings": {
"employee": {
"properties": {
"age": {
"type": "long"
},
"country": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
},
"fielddata": true
},
"join_date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"position": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"salary": {
"type": "long"
}
}
}
}
}
GET /company/employee/_search
{
"size": 0,
"aggs": {
"group_by_country": {
"terms": {
"field": "country"
},
"aggs": {
"group_by_join_date": {
"date_histogram": {
"field": "join_date",
"interval": "year"
},
"aggs": {
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
}
}
}
}
Map<String, Aggregation> aggrMap = searchResponse.getAggregations().asMap();
StringTerms groupByCountry = (StringTerms) aggrMap.get("group_by_country");
Iterator<Bucket> groupByCountryBucketIterator = groupByCountry.getBuckets().iterator();
while(groupByCountryBucketIterator.hasNext()) {
Bucket groupByCountryBucket = groupByCountryBucketIterator.next();
System.out.println(groupByCountryBucket.getKey() + "\t" + groupByCountryBucket.getDocCount());
Histogram groupByJoinDate = (Histogram) groupByCountryBucket.getAggregations().asMap().get("group_by_join_date");
Iterator<org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket> groupByJoinDateBucketIterator = groupByJoinDate.getBuckets().iterator();
while(groupByJoinDateBucketIterator.hasNext()) {
org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket groupByJoinDateBucket = groupByJoinDateBucketIterator.next();
System.out.println(groupByJoinDateBucket.getKey() + "\t" + groupByJoinDateBucket.getDocCount());
Avg avgSalary = (Avg) groupByJoinDateBucket.getAggregations().asMap().get("avg_salary");
System.out.println(avgSalary.getValue());
}
}
client.close();
}
代码:
package com.roncoo.es.score.first;
import java.net.InetAddress;
import java.util.Iterator;
import java.util.Map;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.search.aggregations.Aggregation;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.bucket.histogram.DateHistogramInterval;
import org.elasticsearch.search.aggregations.bucket.histogram.Histogram;
import org.elasticsearch.search.aggregations.bucket.terms.StringTerms;
import org.elasticsearch.search.aggregations.bucket.terms.Terms.Bucket;
import org.elasticsearch.search.aggregations.metrics.avg.Avg;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
/**
* 员工聚合分析应用程序
* @author Administrator
*
*/
public class EmployeeAggrApp {
@SuppressWarnings({ "unchecked", "resource" })
public static void main(String[] args) throws Exception {
Settings settings = Settings.builder()
.put("cluster.name", "elasticsearch")
.build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("localhost"), 9300));
SearchResponse searchResponse = client.prepareSearch("company")
.addAggregation(AggregationBuilders.terms("group_by_country").field("country")
.subAggregation(AggregationBuilders
.dateHistogram("group_by_join_date")
.field("join_date")
.dateHistogramInterval(DateHistogramInterval.YEAR)
.subAggregation(AggregationBuilders.avg("avg_salary").field("salary")))
)
.execute().actionGet();
Map<String, Aggregation> aggrMap = searchResponse.getAggregations().asMap();
StringTerms groupByCountry = (StringTerms) aggrMap.get("group_by_country");
Iterator<Bucket> groupByCountryBucketIterator = groupByCountry.getBuckets().iterator();
while(groupByCountryBucketIterator.hasNext()) {
Bucket groupByCountryBucket = groupByCountryBucketIterator.next();
System.out.println(groupByCountryBucket.getKey() + ":" + groupByCountryBucket.getDocCount());
Histogram groupByJoinDate = (Histogram) groupByCountryBucket.getAggregations().asMap().get("group_by_join_date");
Iterator<org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket> groupByJoinDateBucketIterator = groupByJoinDate.getBuckets().iterator();
while(groupByJoinDateBucketIterator.hasNext()) {
org.elasticsearch.search.aggregations.bucket.histogram.Histogram.Bucket groupByJoinDateBucket = groupByJoinDateBucketIterator.next();
System.out.println(groupByJoinDateBucket.getKey() + ":" +groupByJoinDateBucket.getDocCount());
Avg avg = (Avg) groupByJoinDateBucket.getAggregations().asMap().get("avg_salary");
System.out.println(avg.getValue());
}
}
client.close();
}
}
elasticsearch视频的更多相关文章
- elasticsearch视频34季
02_结构化搜索_在案例中实战使用term filter来搜索数据 课程大纲 1.根据用户ID.是否隐藏.帖子ID.发帖日期来搜索帖子 (1)插入一些测试帖子数据 POST /forum/articl ...
- ES-什么是elasticsearch
前言 观今宜鉴古,无古不成今.在学习elasticsearch之前,我们要知道,elasticsearch是什么?为什么要学习elasticsearch?以及用它能干什么? 关于elasticsear ...
- elastic search(以下简称es)
参考博客园https://www.cnblogs.com/Neeo/p/10304892.html#more 如何学好elasticsearch 除了万能的百度和Google 之外,我们还有一些其他的 ...
- EasySwoole+ElasticSearch打造 高性能 小视频服务系统
EasySwoole+ElasticSearch打造高性能小视频服务 第1章 课程概述 第2章 EasySwoole框架快速上手 第3章 性能测试 第4章 玩转高性能消息队列服务 第5章 小视频服务平 ...
- ElasticSearch 安装, 带视频
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 疯狂创客圈 高并 ...
- 30分钟全方位了解阿里云Elasticsearch(附公开课完整视频)
摘要: 阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据 ...
- 使用elasticsearch的关键技术点
前言 最近有一个项目用到了搜索引擎,这里记录下使用过程中遇到的一些问题和解决方案. 0.准备工作 1)安装elasticsearch 2)安装Marvel 3)安装head tips:在es的配置文件 ...
- elasticsearch使用操作部分
本片文章记录了elasticsearch概念.特点.集群.插件.API使用方法. 1.elasticsearch的概念及特点.概念:elasticsearch是一个基于lucene的搜索服务器.luc ...
- Centos7下使用ELK(Elasticsearch + Logstash + Kibana)搭建日志集中分析平台
日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散在各个生产服务器,且开发人员无法登陆生产服务器,这时候就需要一个集中式的日志收集装置,对日志中的关键字进行监控,触发异常 ...
随机推荐
- redis远程连接报错记录
错误如下 redis可视化工具连接测试 telnet ip 6379 修改关键参数如下 #开通外网访问 # bind 127.0.0.1 #以后台方式运行 daemonize no #取消保护模式,保 ...
- [物理学与PDEs]第1章习题1 无限长直线的电场强度与电势
设有一均匀分布着电荷的无限长直线, 其上的电荷线密度 (即单位长度上的电荷量) 为 $\sigma$. 试求该直线所形成的电场的电场强度及电势. 解答: 设空间上点 $P$ 到直线的距离为 $r$, ...
- Sql server not in优化
使用EXISTS(或NOT EXISTS)通常将提高查询的效率,由于NOT IN子句将对子查询中的表执行了一个全表遍历. oracle在执行IN子查询过程中,先执行子查询结果放入临时表再进行主查询: ...
- C语言网蓝桥杯1116 IP判断
判断IP地址的合法性, 1.不能出现除数字和点字符以外的的其他字符 2.数字必须在0-255之间,要注意边界. 题目分析: 因为一个IP是又四个数字组成,且可能存在符号和其他字符,故不能用整型数组处理 ...
- Ubuntu查看端口占用情况
netstat -apn 其中最后一列是PID,可以通过kill Pid进行结束进程. 更精确的查找: netstat -apn | grep 8080 查询8080端口的进程 如果要查询这个进程的详 ...
- Jquery点击div之外的地方隐藏当前div
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <script sr ...
- Python 爬虫 JD商品-scrapy+requests
目标站点需求分析 JD商品信息抓取 需求信息字段 涉及的库 scrapy, requests,re lxml 获取单页源码 解析单页源码 获取总页数 获取商品url 解析商品信息 保存本地文件 保存m ...
- UI设计师给的px尺寸单位,安卓如何换算成dp?
很多UI工程师为了适配IOS,常常拿IOS手机作用参考模型,设计出来的UI稿只有PX标注的.他们也不懂Android的dp和sp单位是怎么回事.这个时候我们Android工程师如果不注意怎么转换的话, ...
- centos + nginx + php-fpm +mysql的简单配置
安装前准备 安装约定(这个根据自己习惯,可自行修改) 1.软件源码包我都下载到/usr/local/src这个目录下 2.软件一般都编译安装到/usr/local这个目录下 安装基础库 yum -y ...
- SpringBoot图片上传(五) 上一篇的新版本,样式修改后的
简单描述:一次上传N张图片(N可自定义):上传完后图片回显,鼠标放到已经上传的图片上后,显示删除,点击后可以删除图片,鼠标离开后,图片恢复. 效果:一次上传多个图片后的效果 上传成功: 鼠标悬浮到图片 ...