【模式匹配】更快的Boyer-Moore算法
1. 引言
前一篇中介绍了字符串KMP算法,其利用失配时已匹配的字符信息,以确定下一次匹配时模式串的起始位置。本文所要介绍的Boyer-Moore算法是一种比KMP更快的字符串匹配算法,它到底是怎么快的呢?且听下面分解。
不同于KMP在匹配过程中从左至右与主串字符做比较,Boyer-Moore算法是从模式串的尾字符开始从右至左做比较。下面讨论的一些递推式都与BM算法的这个特性有关。
思想
首先,我们一般化匹配失败的情况,设主串\(y\)、模式串\(x\)的失配位置为i+j与i,且主串、模式串的长度各为\(n\)与\(m\),如下图:

已匹配上的字符结构:
\]
失配后下一次匹配时,模式串应如何对齐于主串呢?从上图中看出,我们可以利用两方面的信息:
- 已经匹配上的字符结构,
- 主串失配位置的字符
前一篇中的KMP算法只利用第一条信息,而Boyer-Moore算法则是将这两方面的信息都利用到了,故模式串的移动更为高效。同时,根据这两方面信息(已匹配信息与失配信息),Boyer-Moore算法引申出来两条移动规则:好后缀移动(good-suffix shift)与坏字符移动(bad-character shift)。
实例
Moore教授在这里给出BM算法一个实例,比如主串=HERE IS A SIMPLE EXAMPLE ,模式串=EXAMPLE。第一次匹配如下图:

在第一次匹配中,模式串在尾字符发生失配,而主串的失配字符为S,且S不属于模式串的字符;因此下一次匹配时模式串指针应向右移动7位(坏字符移动)。第二次匹配如下图:

第二次匹配也是在模式串尾字符发生失配,但不同的是主串的失配字符为P属于模式串的字符;因此下一次匹配时模式串的P(从右开始第一次出现)应对齐于主串的失配字符P(坏字符移动)。第三次匹配如下图:

在第三次匹配中,模式串的后缀MPLE完全匹配上主串,主串的失配字符为I,不属于模式串的字符;那么下一次匹配是模式串指针应怎么移动呢(是坏字符移动,还是好后缀移动?)?BM算法采取的办法:移动步数=\(\max\{坏字符移动步数,\ 好后缀移动步数\}\)。(具体移动步数的计算会在下面给出),这里是按好后缀移动;第四次匹配如下图:
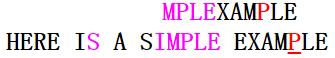
第四次匹配的情况与第二次类似,应按坏字符移动,第五次匹配(模式串与主串完全匹配)如下图:
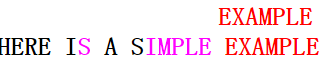
2. BM算法详述
好后缀移动
因已匹配上的字符结构正好为模式串的后缀,故名之为好后缀。好后缀移动一般分为两种情况:
- 移动后,模式串有子串能完全匹配上好后缀;
- 移动后,模式串只有能部分匹配上好后缀的子串
我们用数组bmGs[i]表示模式串的失配位置为i时好后缀移动的步数。第一类情况如下图:

第二类情况如下图:

接下来的问题是应如何计算bmGs[i]呢?我们引入suff函数,其定义如下:
\]
表示了模式串中末字符为x[i]的子串能匹配模式串后缀的最大长度。其中,suff[i]=m。
对于第一类情况,令
i+1=m-suff[a],则x[i+1..m-1]=x[m-suff[a]..m-1];根据suff函数的定义,有x[m-suff[a]..m-1]=x[a-suff[a]-1..a];则x[i+1..m-1]=x[a-suff[a]-1..a],即可得到bmGs[i]=bmGs[m-suff[a]-1]=m-1-a。对于第二类情况,由字符的部分匹配可得
x[0..m-1-bmGs[i]]=x[bmGs[i]..m-1],即suff[m-1-bmGs[i]]=m-bmGs[i]。令m-bmGs[i]=a,有suff[a-1]=a。因为是部分匹配,故bmGs[i] = m-a > i+1,则i < m-a-1。综上,当i < m-a-1且suff[a-1]=a时,bmGs[i]=m-a。有可能上述两种情况都没能被匹配上,则
bmGs[i]=m。
综合上述三类情况,bmGs数组计算的实现代码(参看[2]):
void preBmGs(char *x, int m, int bmGs[]) {
int i, j, suff[XSIZE];
suffixes(x, m, suff);
// case 3, default value
for (i = 0; i < m; ++i)
bmGs[i] = m;
j = 0;
// case 2
for (i = m - 1; i >= 0; --i)
if (suff[i] == i + 1)
for (; j < m - 1 - i; ++j)
if (bmGs[j] == m)
bmGs[j] = m - 1 - i;
// case 1
for (i = 0; i <= m - 2; ++i)
bmGs[m - 1 - suff[i]] = m - 1 - i;
}
坏字符移动
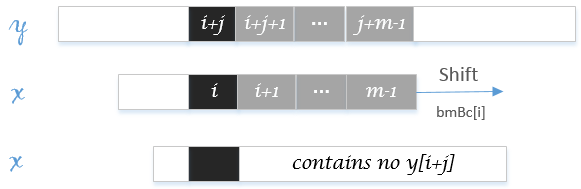
坏字符移动是根据主串失配位置的字符y[i+j]而进行的移动。同样地,我们用数组bmBc[c]表示主串失配位置字符为c时坏字符移动的步数。坏字符移动一般分为两种情况:
模式串
x[0..i-1]有字符y[i+j]且第一次出现,如下图:
整个模式串都不包含该字符串,如下图:

据此,可以将bmBc[c]定义如下:
\]
表示距模式串末字符最近的c字符;若c字符未出现在模式串中,则bmBc[c]=m。C实现代码:
void preBmBc(char *x, int m, int bmBc[]) {
int i;
for (i = 0; i < ASIZE; ++i)
bmBc[i] = m;
for (i = 0; i < m - 1; ++i)
bmBc[x[i]] = m - i - 1;
}
suff函数计算
bmGs[i]的计算依赖于suff函数;如何更为高效的计算suff函数成为了接下来需要考虑的问题。符号标记的定义如下:
i表示当前位置;f记录上一轮匹配的起始位置;g记录上一轮匹配的失配位置。
这里所说的匹配指的是与模式串后缀的匹配。同样地,一般化匹配过程,如下图:
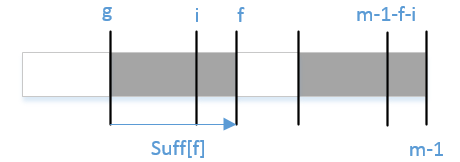
当g < i < f则必有x[i]=x[m-1-(f-i)]=x[m-1-f+i];
- 若
suff[m-1-f+i] < i-g,则suff[i]=suff[m-1-f+i]; - 否则,
suff[i]与suff[m-1-f+i]没有关系,要根据定义进行计算。
C实现代码:
void suffixes(char *x, int m, int *suff) {
int f, g, i;
suff[m - 1] = m;
g = m - 1;
for (i = m - 2; i >= 0; --i) {
if (i > g && suff[i + m - 1 - f] < i - g)
suff[i] = suff[i + m - 1 - f];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && x[g] == x[g + m - 1 - f])
--g;
suff[i] = f - g;
}
}
}
复杂度分析
3. 参考资料
[1] Moore, Boyer-Moore algorithm example.
[2] Thierry Lecroq, Boyer-Moore algorithm.
[3] sealyao, Boyer-Moore算法学习.
【模式匹配】更快的Boyer-Moore算法的更多相关文章
- 【模式匹配】更快的Boyer
1. 引言 前一篇中介绍了字符串KMP算法,其利用失配时已匹配的字符信息,以确定下一次匹配时模式串的起始位置.本文所要介绍的Boyer-Moore算法是一种比KMP更快的字符串匹配算法,它到底是怎么快 ...
- Boyer Moore算法(字符串匹配)
上一篇文章,我介绍了KMP算法. 但是,它并不是效率最高的算法,实际采用并不多.各种文本编辑器的"查找"功能(Ctrl+F),大多采用Boyer-Moore算法. Boyer-Mo ...
- 利用共享内存实现比NCCL更快的集合通信
作者:曹彬 | 旷视 MegEngine 架构师 简介 从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢.针对这种情况下的单机多卡训练,MegEng ...
- 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上)
[转] 设计师和开发人员更快完成工作需求的20个惊人的jqury插件教程(上) jquery的功能总是那么的强大,用他可以开发任何web和移动框架,在浏览器市场,他一直是占有重要的份额,今天,就给大家 ...
- 让互联网更快:新一代QUIC协议在腾讯的技术实践分享
本文来自腾讯资深研发工程师罗成在InfoQ的技术分享. 1.前言 如果:你的 App,在不需要任何修改的情况下就能提升 15% 以上的访问速度,特别是弱网络的时候能够提升 20% 以上的访问速度. 如 ...
- 利用更快的r-cnn深度学习进行目标检测
此示例演示如何使用名为“更快r-cnn(具有卷积神经网络的区域)”的深度学习技术来训练对象探测器. 概述 此示例演示如何训练用于检测车辆的更快r-cnn对象探测器.更快的r-nnn [1]是r-cnn ...
- 让 CDN 更省流量的 Brotli 算法详解
早年,我还是学生的时候,时常会鼓捣自己的个人网站,其中最困扰我的问题就是源站服务器易崩溃.作为学生,一方面我没有足够的钱购买高质量的服务器,另一方面一年的流量费用算下来也挺贵的,要花掉我不少的生活费. ...
- 正则表达式匹配可以更快更简单 (but is slow in Java, Perl, PHP, Python, Ruby, ...)
source: https://swtch.com/~rsc/regexp/regexp1.html translated by trav, travmymail@gmail.com 引言 下图是两种 ...
- Quick UDP Internet Connections 让互联网更快的协议,QUIC在腾讯的实践及性能优化
https://mp.weixin.qq.com/s/44ysXnVBUq_nJByMyX9n5A 让互联网更快:通往QUIC之路 原创: 史天 翻译 云技术实践 8月15日 QUIC(Quick U ...
随机推荐
- CMD命令小结
C:\Windows\Explorer.exe “文件具体目录(要加文件后缀名)”,(Explorer.exe后有一个空格,例如C:\Windows\Explorer.exe C:\temp\New ...
- 灰色预测原理及JAVA实现
最近在做项目时,用户不想使用平均值来判断当前数据状态,想用其他的方式来分析数据的变化状态,在查找了一些资料后,想使用灰色预测来进行数据的预测.下面的内容是从网上综合下来的,java代码也做了一点改动, ...
- DataTable汇总
一.排序 1 获取DataTable的默认视图 2 对视图设置排序表达式 3 用排序后的视图导出的新DataTable替换就DataTable (Asc升序可省略,多列排序用"," ...
- Linux 学习笔记(一) 入门
Shell 显示Shell类型 $ps 切换Shell $[Shell 名称] ex. $tcsh 快捷键 Ctrl + Z:挂起,可用jobs查看到,fg恢复运行 Ctrl + W:删除单词 Ct ...
- CoinPunk项目介绍
CoinPunk是一个bitcoin比特币钱夹服务web应用程序,你可以自己构建钱夹服务.开源,免费. 轻量级,高效 响应式设计 轻易创建新账户 详细的交易记录 构建于Node.js与H ...
- Metrics-Java版的指标度量工具之一
Metrics是一个给JAVA服务的各项指标提供度量工具的包,在JAVA代码中嵌入Metrics代码,可以方便的对业务代码的各个指标进行监控,同时,Metrics能够很好的跟Ganlia.Graphi ...
- MapReduce实例浅析
在文章<MapReduce原理与设计思想>中,详细剖析了MapReduce的原理,这篇文章则通过实例重点剖析MapReduce 本文地址:http://www.cnblogs.com/ar ...
- FTP文件管理
因为网站有下载文件需要和网站分离,使用到了FTP管理文件,这里做一个简单的整理. 1.安装FTP 和安装iis一样.全部勾选. 设置站点名称和路径. 设置ip. 身份授权选择所有用户,可以读写. 完成 ...
- [.net 面向对象编程基础] (18) 泛型
[.net 面向对象编程基础] (18) 泛型 上一节我们说到了两种数据类型数组和集合,数组是指包含同一类型的多个元素,集合是指.net中提供数据存储和检索的专用类. 数组使用前需要先指定大小,并且检 ...
- 今天心情好,给各位免费呈上200兆SVN代码服务器一枚,不谢!
开篇先给大家讲个我自己的故事,几个月前在网上接了个小软件开发的私活,平日上班时间也比较忙,就中午一会儿休息时间能抽出来倒腾着去做点.每天下班复制一份到U盘带回去继续摸索,没多久U盘里躺着的文件列表那叫 ...