Python操作rabbitmq系列(六):进行RPC调用
此刻,我们已经进入第6章,是官方的最后一个环节,但是,并非本系列的最后一个环节。因为在实战中还有一些经验教训,并没体现出来。由于马上要给同事没培训celery了。我也来不及写太多。等后面,我们再慢慢补充。
RPC:是远程过程调用。百度写了一大堆。此刻,我们简单点说:比如,我们在本地的代码中调用一个函数,那么这个函数不一定有返回值,但一定有返回。若是在分布式环境中,香我们前几章的例子,发送消息出去后,发送端是不清楚客户端处理完后的结果的。由于rabbitmq的响应机制,顶多能获取到客户端的处理状态,但并不能获取处理结果。那么,我们想像本地调用那样,需要客户端处理后返回结果该怎么办呢。就是如下图:
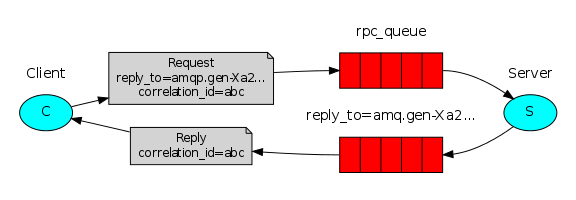
client发送请求,同时告诉server处理完后要发送消息给:回调队列的ID:correlation_id=abc,并调用replay_to回调队列对应的回调函数。请上代码:
客户端:
客户端:发消息也收消息
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
# 创建连接
self.connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
self.channel = self.connection.channel()
# 创建回调队列
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
# 这里:这个是消息发送方,当要执行回调的时候,它又是接收方
# 使用callback_queue 实现消息接收。即是回调。注意:这里的回调
# 不需要对消息进行确认。反复确认,没玩没了就成了死循环
#这里设置回调
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
# 定义回调的响应函数。
# 判断:若是当前的回调ID和响应的回调ID相同,即表示,是本次请求的回调
# 原因:若是发起上百个请求,发送端总得知道回来的对应的是哪一个发送的
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
# 设置响应和回调通道的ID
self.response = None
self.corr_id = str(uuid.uuid4())
# properties中指定replay_to:表示回调要调用那个函数
# 指定correlation_id:表示回调返回的请求ID是那个
# body:是要交给接收端的参数
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
# 监听回调
while self.response is None:
self.connection.process_data_events()
# 返回的结果是整数,这里进行强制转换
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
服务端:
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
def on_request(ch, method, props, body):
#收到的消息
n = int(body)
print(" [.] fib(%s)" % n)
#要处理的任务
response = fib(n)
#发布消息。通知到客户端
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id= props.correlation_id),
body=str(response))
#手动响应
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
结果:

OK,我们的rabbitmq系列,就暂时告一段落。这其中还有一个实际的问题,我们还没有解决。就是:一个消息到达队列,我们需要多少个消费端去处理,这些消费端又该如何进行管理,比如:那些消费端工作已经做完,那些有出异常挂掉,队列除了使用prefetch_count属性又该如何进一步来平衡各消费端的负载等等。看样子我们还有很多事要做
Python操作rabbitmq系列(六):进行RPC调用的更多相关文章
- Python操作rabbitmq系列(一)
从本文开始,接下来的内容,我们将讨论rabbitmq的相关功能.我的这些文章,最终是要实现一个项目(具体是什么暂不透露).前面每一篇,都是在为这个系统做准备.rabbitmq,是我们这个项目的关键部分 ...
- Python操作rabbitmq系列(五):根据主题分配消息
接着上一章,使用exchange_type='direct'进行消息传递.这样消息会完全匹配后发送到对应的接收端.现在我们想干这样一件事: C1获取消息中包含:orange内容的消息,并且消息是由3个 ...
- Python操作rabbitmq系列(二):多个接收端消费消息
今天,我们要逐步开始讨论rabbitmq稍微高级点的耍法了.了解这一步,对我们设计高并发的系统非常有用.当然,还可以使用kafka.不过还是算了,有几个硬性条件不支持,还是用rabbitmq吧. 循环 ...
- Python操作rabbitmq系列(四):根据类型订阅消息
在上一章中,所有的接收端获取的所有的消息.这一章,我们将讨论,一些消息,仍然发送给所有接收端.其中,某个接收端,只对其中某些消息感兴趣,它只想接收这一部分消息.如下图:C1,只对error感兴趣,C2 ...
- Python操作rabbitmq系列(三):多个接收端消费消息
接着上一章.这一章,我们要将同一个消息发给多个客户端.这就是发布订阅模式.直接看代码: 发送端: import pikaimport sys connection = pika.BlockingCon ...
- Python操作RabbitMQ
RabbitMQ介绍 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- python - 操作RabbitMQ
python - 操作RabbitMQ 介绍 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议.MQ全称为Mess ...
- 文成小盆友python-num12 Redis发布与订阅补充,python操作rabbitMQ
本篇主要内容: redis发布与订阅补充 python操作rabbitMQ 一,redis 发布与订阅补充 如下一个简单的监控模型,通过这个模式所有的收听者都能收听到一份数据. 用代码来实现一个red ...
随机推荐
- 如何查看子线程中的GC Alloc
1)如何查看子线程中的GC Alloc2)Build时,提示安卓NDK异常3)如何获得ParticleSystem产生的三角形数量4)关于图片通道的问题5)GPUSkinning导致模型动画不平滑 M ...
- python获取群成员信息
#coding: utf-8 import itchat,datetime from itchat.content import TEXT itchat.auto_login(hotReload=Tr ...
- 五分钟了解Semaphore
一.前言 多个线程之间的同步,我们会用到Semaphore,翻译成中文就是信号量.使用Semaphore可以限制多个线程对同一资源的访问.我们先看下C#中对Semaphore的定义,如下图: 翻译成中 ...
- Natas9 Writeup(命令注入)
Natas9: 审计源码,发现关键代码: $key = ""; if(array_key_exists("needle", $_REQUEST)) { $key ...
- 大数据软件安装之Azkaban(任务调度)
一.安装部署 1.安装前准备 1)下载地址:http://azkaban.github.io/downloads.html 2)将Azkaban Web服务器.Azkaban执行服务器.Azkaban ...
- Journal of Proteome Research | Down-Regulation of a Male-Specific H3K4 Demethylase, KDM5D, Impairs Cardiomyocyte Differentiation (男性特有的H3K4脱甲基酶基因(KDM5D)下调会损伤心肌细胞分化) | (解读人:徐宁)
文献名:Down-Regulation of a Male-Specific H3K4 Demethylase, KDM5D, Impairs Cardiomyocyte Differentiatio ...
- Error: java.net.ConnectException: Call From tuge1/192.168.40.100 to tuge2:8032 failed on connection exception
先看解决方案,再看唠嗑,唠嗑可以忽略. 解决方案: 使用start yarn.sh启动yarn就可以了. 唠嗑: 今天学习Spark基于Yarn部署.然后总以为Yarn是让Spark启动的,提交程序的 ...
- HTML中的IE条件注释,让低版本IE也能正常运行HTML5+CSS3网站的3种解决方案
最近的项目中,因为需要兼容IE7,IE8,IE9,解研究了IE的条件注释,顺手写下来备忘. HTML中的IE条件注释 IE条件注释是一种特殊的HTML注释,这种注释只有IE5.0及以上版本才能理解. ...
- Cisco 模拟配置
本次模拟:采用Cisco Packet Tracer 软件,进行cisco网络设备的模拟.可以实现CLI界面命令配置,同实际交换机一样. 1.同一VLAN 可以互相访问,不同VLAN 不能访问 PC0 ...
- React Hook上车
React Hook 是 v16.8 的新功能,自诞生以来,受到广泛的好评,在 React 版本更新中具有里程碑的意义.现在都2020年了,再不上车 React Hook 就真的 out 了... H ...