Oozie笔记
简介
- Oozie 是用于 Hadoop 平台的开源的工作流调度引擎。
- 用于管理 Hadoop
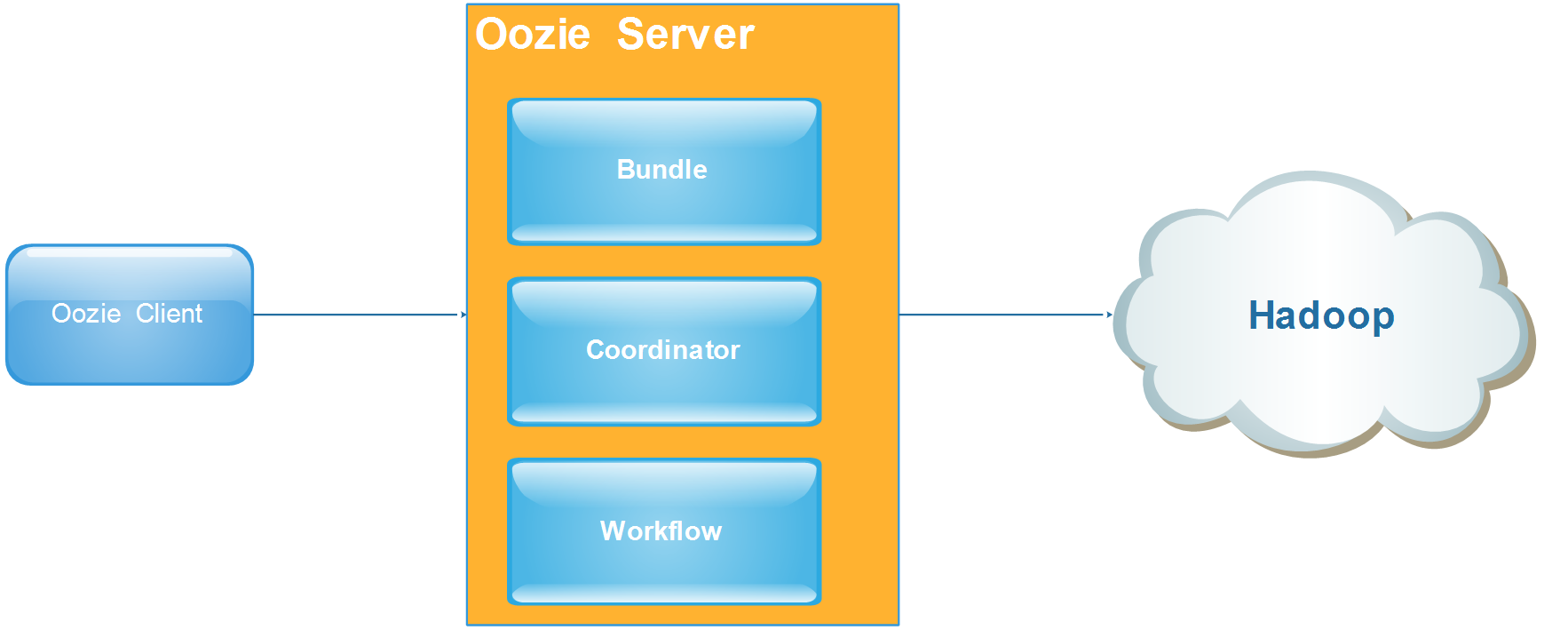
- 属于web应用程序, 由 Oozie client 和 Oozie Server 两个组件构成。
- Oozie Server 运行于 Java Servlet容器 (Tomcat) 中的 web 程序。
作用
- 统一调度hadoop系统中场景的MR任务启动、hdfs操作、shell调度、hive操作等
- 使得复杂的依赖关系、时间触发、事件触发使用xml语言进行表达, 开发效率提高
- 一组任务使用一个DAG来表示, 使用图形表达流程逻辑更加清晰
- 支持很多种任务调度, 能完成大部分 hadoop 任务处理
- 程序定义支持 EL 常量 和 函数, 表达更加丰富
Oozie 架构
安装方式
- 手动安装
- Cloudera Manger 添加服务
Oozie Web控制台
- 解压ext-x.x到/var/lib/oozie目录下 unzip ext-x.x.zip -d /var/lib/oozie/
- Oozie服务中配置启用web控制台
- 保存,重启oozie服务
Oozie 配置
- 节点内存配置
- oozie.service.callablequeueservice.callable.concurrency(节点并发)
- oozie.service.callablequeueservice.queue.size(队列大小)
- oozie.service.ActionService.executor.ext.classes(扩展)
Oozie 共享库
- /user/oozie/share/lib(hdfs中目录)
web管理地址
- http://oozie_host_ip:11000/oozie/
Oozie 管理
- 任务列表查看
- 任务状态查看
- 流程返回信息
- 节点信息查看
- 流程图信息
- 日志查看
- 系统信息查看 和 配置
Oozie CLI 命令
- 启动任务
- oozie job -oozie http://ip:11000/oozie/ -config job.properties -run
- 停止任务
- oozie job -oozie http://ip:11000/oozie/ -kill 0000002-150713234209387-oozie-oozi-W
- 提交任务
- oozie job -oozie http://ip:11000/oozie/ -kill 0000002-150713234209387-oozie-oozi-W
- 开始任务
- oozie job -oozie http://ip:11000/oozie/ -config job.properties -start 0000003-150713234209387-oozie-oozi-W
- 查看任务执行情况
- oozie job -oozie http://ip:11000/oozie/ -config job.properties -info 0000003-150713234209387-oozie-oozi-W
Job 配置 job.properties
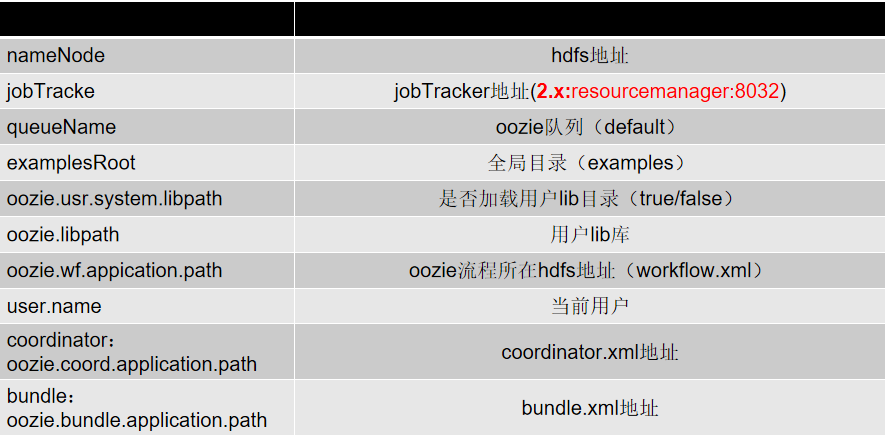
WorkFLow 配置
版本信息
- <workflow-app xmlns="uri:oozie:workflow:0.4" name=“workflow name">
EL函数
基本EL函数
String firstNotNull(String value1, String value2)
String concat(String s1, String s2)
String replaceAll(String src, String regex, String replacement)
String appendAll(String src, String append, String delimeter)
String trim(String s)
String urlEncode(String s)
String timestamp()
String toJsonStr(Map) (since Oozie 3.3)
String toPropertiesStr(Map) (since Oozie 3.3)
String toConfigurationStr(Map) (since Oozie 3.3)
WorkFlow EL
- String wf:id() – 返回当前workflow作业ID
- String wf:name() – 返回当前workflow作业NAME
- String wf:appPath() – 返回当前workflow的路径
- String wf:conf(String name) – 获取当前workflow的完整配置信息
- String wf:user() – 返回启动当前job的用户
- String wf:callback(String stateVar) – 返回结点的回调URL,其中参数为动作指定的退出状态
- int wf:run() – 返回workflow的运行编号,正常状态为0
- Map wf:actionData(String node) – 返回当前节点完成时输出的信息
- int wf:actionExternalStatus(String node) – 返回当前节点的状态
- String wf:lastErrorNode() – 返回最后一个ERROR状态推出的节点名称
- String wf:errorCode(String node) – 返回指定节点执行job的错误码,没有则返回空
- String wf:errorMessage(String message) – 返回执行节点执行job的错误信息,没有则返回空
HDFS EL
- boolean fs:exists(String path)
- boolean fs:isDir(String path)
- long fs:dirSize(String path) – 目录则返回目录下所有文件字节数;否则返回-1
- long fs:fileSize(String path) – 文件则返回文件字节数;否则返回-1\
- long fs:blockSize(String path) – 文件则返回文件块的字节数;否则返回-1
节点
流程控制节点
流程控制节点
- start – 定义workflow开始
- end – 定义workflow结束
- decision – 实现switch功能
- sub-workflow – 调用子workflow
- kill – 杀死workflow
- fork – 并发执行workflow
- join – 并发执行结束(与fork一起使用)
<decision name="[NODE-NAME]">
<switch>
<case to="[NODE_NAME]">[PREDICATE]</case>
...
<case to="[NODE_NAME]">[PREDICATE]</case>
<default to="[NODE_NAME]" />
</switch>
</decision>
动作节点
shell
java
fs
MR
hive
sqoop
<fork name="[FORK-NODE-NAME]">
<path start="[NODE-NAME]" />
...
<path start="[NODE-NAME]" />
</fork>
...
<join name="[JOIN-NODE-NAME]" to="[NODE-NAME]" />
Shell节点
job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=examples oozie.wf.application.path=${nameNode}/user/workflow/oozie/shellworkflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.3" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>echo</exec>
<argument>hi shell in oozie</argument>
</shell>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
调用impala
job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=examples
oozie.usr.system.libpath=true
oozie.libpath=${namenode}/user/${user.name}/workflow/impala/lib oozie.wf.application.path=${nameNode}/user/${user.name}/workflow/impalaworkflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.4" name="impala-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:0.1">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>impala-shell</exec>
<argument>-i</argument>
<argument>node02</argument>
<argument>-q</argument>
<argument>invalidate metadata</argument>
<capture-output/>
</shell>
......
</action>
.......
</workflow-app>
fs节点
workflow.xml
<workflow-app name="[WF-DEF-NAME]" xmlns="uri:oozie:workflow:0.5">
...
<action name="[NODE-NAME]">
<fs>
<delete path='[PATH]'/>
<mkdir path='[PATH]'/>
<move source='[SOURCE-PATH]' target='[TARGET-PATH]'/>
<chmod path='[PATH]' permissions='[PERMISSIONS]' dir-files='false' />
<touchz path='[PATH]' />
<chgrp path='[PATH]' group='[GROUP]' dir-files='false' />
</fs>
<ok to="[NODE-NAME]"/>
<error to="[NODE-NAME]"/>
</action>
</workflow-app>
Java节点
job.properties
nameNode=hdfs://node01:8020
jobTracker=node01:8032
queueName=default
examplesRoot=examples
oozie.usr.system.libpath=true
oozie.libpath=${nameNode}/user/workflow/lib/lib4java oozie.wf.application.path=${nameNode}/user/workflow/oozie/javaworkflow.xml
<workflow-app xmlns="uri:oozie:workflow:0.3" name="mr-wc-wf">
<start to="mr-node"/>
<action name="mr-node">
<java>
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/path" />
<mkdir path="${nameNode}/user/path" />
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<main-class>com.pagename.classname</main-class>
<arg>args1</arg>
<arg>args2</arg>
</java>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
Oozie笔记的更多相关文章
- Hadoop Oozie 学习笔记
Oozie是一个工作流引擎服务器,用于运行Hadoop Map/Reduce和Pig 任务工作流.同时Oozie还是一个Java Web程序,运行在Java Servlet容器中,如Tomcat. O ...
- oozie学习笔记
#################################################################################################### ...
- Hadoop学习笔记—18.Sqoop框架学习
一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数据移植过去并不容易.Apache Sqoop正在加 ...
- #数据技术选型#即席查询Shib+Presto,集群任务调度HUE+Oozie
郑昀 创建于2014/10/30 最后更新于2014/10/31 一)选型:Shib+Presto 应用场景:即席查询(Ad-hoc Query) 1.1.即席查询的目标 使用者是产品/运营/销售 ...
- Hadoop概括——学习笔记<一>
之前有幸在MOOC学院抽中小象学院hadoop体验课. 这是小象学院hadoop2.X概述第一章的笔记 第一章主要讲的是hadoop基础知识.老师讲的还是比较全面简单的,起码作为一个非专业码农以及数据 ...
- sqoop笔记
adoop学习笔记—18.Sqoop框架学习 一.Sqoop基础:连接关系型数据库与Hadoop的桥梁 1.1 Sqoop的基本概念 Hadoop正成为企业用于大数据分析的最热门选择,但想将你的数 ...
- 【Oozie】安装配置Oozie
安装和配置Oozie Oozie用于Hadoop的工作流配置: 参考链接: <Install and Configure Apache Oozie Workflow Scheduler for ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- Hadoop自学笔记(一)常见Hadoop相关项目一览
本自学笔记来自于Yutube上的视频Hadoop系列.网址: https://www.youtube.com/watch?v=-TaAVaAwZTs(当中一个) 以后不再赘述 自学笔记,难免有各类错误 ...
随机推荐
- cmd如何进入和退出Python编程环境?
cmd里面进入python编译环境的方式: 安装Python之后需直接运行: python 即可进入Python开发环境 退出Python编译环境主要有三种方式: 1:输入exit(),回车 2:输入 ...
- nginx 打印详细请求
log_format main escape=json '{ "@timestamp": "$time_iso8601", ' '"remote_ad ...
- HTML有2种路径的写法:绝对路径和相对路径
HTML有2种路径的写法:绝对路径和相对路径 2016年11月30日 17:51:20 Bolon0708 阅读数 21775 版权声明:本文为博主原创文章,未经博主允许不得转载. https:/ ...
- docker for windows 容器内网通过独立IP直接访问的方法
Docker官方推荐我们通过端口映射的方式把Docker容器的服务提供给宿主机或者局域网其他容器使用.一般过程是: 1.Docker进程通过监听宿主机的某个端口,将该端口的数据包发送给Docker容器 ...
- 101、Java中String类之判断是否由数字组成
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...
- ElasticSearch学习,入门篇(一)
概念解析 1.什么是搜索 搜索就是在任何场景下,找寻你想要的信息,这个时候你会输入一段要搜索的关键字,然后期望找到这个关键字相关的有效信息. 2.如果用数据库做搜素会怎么样 select * from ...
- docker 运行ubuntu镜像 apt-get update 问题
docker运行ubuntu镜像后,apt-getupdate出现问题如下: 根据上面的报错大概是因为....文件上没有生效(生效还需要10d 13h 33min 45s),看来是时间不够啊,需要等待 ...
- GoJS实例3
复制如下内容保存到空白的.html文件中,用浏览器打开即可查看效果 <!DOCTYPE html> <html> <head> <meta charset=& ...
- 计算机是如何计算的、运行时栈帧分析(神奇i++续)
关于i++的疑问 通过JVM javap -c 查看字节码执行步骤了解了i++之后,衍生了一个问题: int num1=50; num1++*2执行的是imul(将栈顶两int类型数相乘,结果入栈), ...
- 034、Java中自增之++在前面的写法
01.代码如下: package TIANPAN; /** * 此处为文档注释 * * @author 田攀 微信382477247 */ public class TestDemo { public ...